课程 的子部分
17.C加加编程
- 15.计算机图形学OpenGL与C++
理解GLFW和GLAD
GLFW()
GLFW是一个开源的、跨平台的库,用于创建窗口、处理输入和渲染图形。它提供了一种简单的方式来与OpenGL进行交互,使得开发图形应用程序变得更加容易。
- 14.新标准C加加程序设计
内存分区模型
内存代码区的意义:程序代码放在不同的区域,有程序自动管理的代码,也有程序员管理的代码,灵活管理;
一、程序执行前
1.代码区 存放二进制指令,就是代码,特点:
- 13.从C到C++
指针
指针的声明:

数组
数组的范围必须是常量表达式,同时如果需要变化的范围可以做如下定义:

2.字符串文字量
指的是用 ““括起来的字符串。
- 12.其他库的介绍
为什么需要哈希函数?
哈希函数在计算机科学中扮演着重要的角色,其主要作用包括:
-
数据检索:哈希函数可以将键(key)映射到哈希表中的一个位置,从而快速检索数据。这是哈希表(如 C++ 中的
std::unordered_map和std::unordered_set)的基础。 - 11.STL库学习之适配器
整体框架的回顾
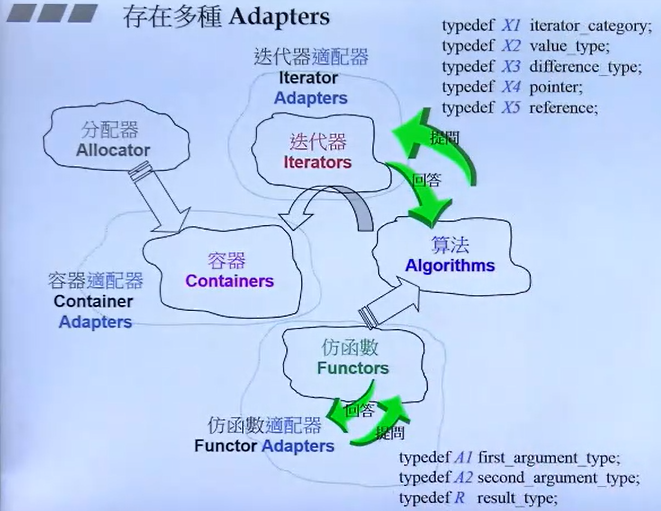
存在多种适配器-adapters
一个人理解,要将适配器理解透彻,我们需要先从别的组件入手,这里以vector容器为例,我们都知道该容器需要迭代器,也就是一些智能指针来确定容器的头尾,以及内容位置,目的是方便后续的算法的怎删改查等操作,假设算法现在要做拿到位置8的数据,那么vector的指针要怎么移动呢?已知指针移动上,vector是随机访问指针,也就是前后都可以跑,而这个操作实际上是迭代器的其中一个内容,而这一内容就需要一个适配器去做适配。
- 10.STL库学习之仿函数
仿函数的个人理解
仿函数是行为类似函数的一个类,比较明显的特征是仿函数重载了operate(),比如你写了一个struct,并在里面重载了operate(),当调用这个类的()时就会返回响应的数据。
- 9.STL库学习之迭代器与算法
标准库常用算法

迭代器
迭代器-的分类
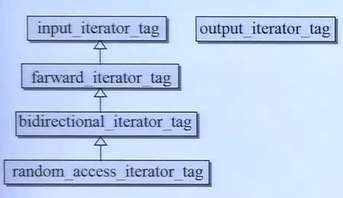
struct input_iterator_tag {}; struct output_iterator_tag {}; struct forward_iterator_tag:public input_iterator_tag{}; struct bidirectional_iterator_tag:public forward_iterator_tag{}; struct random_access_tag:public bidirectional_iterator_tag {};以上5中迭代器的继承关系,如下图所示。
1.Input Iterator(输入迭代器): 输入迭代器是最基本的迭代器类型,支持单向遍历,只能向前移动。
- 8.STL库学习之容器
list
vector
deque
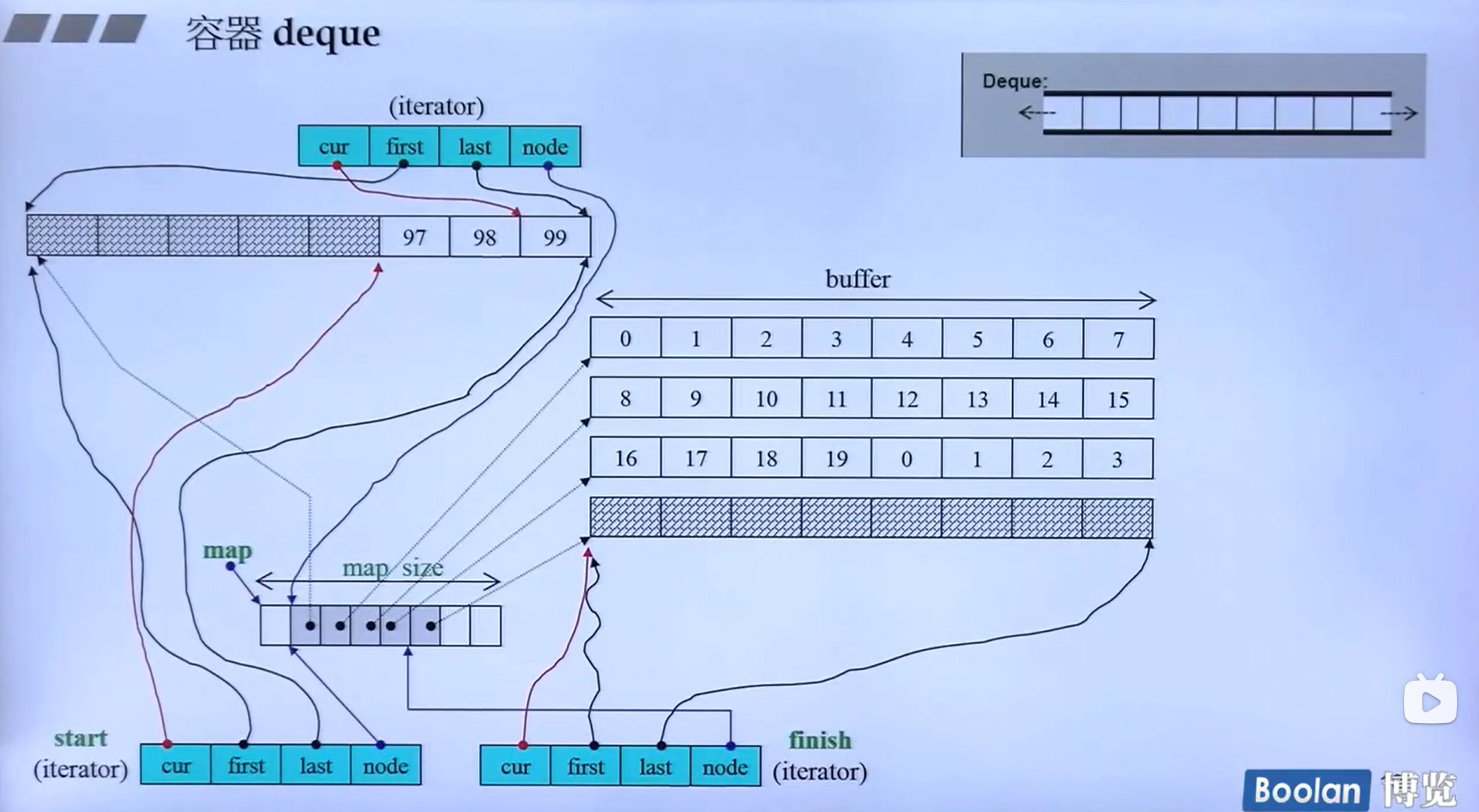
deque的迭代器

deque实现中间插入值的做法:如果欲插入值在最前端(最尾端)调用
push_front()(push_back()),否则借助insert_aux()迭代器,实现如果欲插入位置靠近前端使用,就让前端的数据往前挪,否则往后挪。 - 7.STL库学习之分配器
分配器源代码位置:xmemory.h

除了array和vector外,其他容器的适配器必须是一个类,
- 6.STL库学习之筑基概要
STL程序源代码位置
了解自身编译器STL程序源代码位置。
OOP 与 GP
面向对象编程(OOP):
面向对象编程是一种编程范式,它将数据和处理这些数据的方法封装在对象中。这种方法强调了数据和函数的捆绑,使得代码更加模块化,易于理解和维护。对象可以包含属性(数据)和方法(函数),它们一起工作来模拟现实世界的行为。
- 5.STL库之观其大略
一下主要讲STL组件的测试用例,特别是容器的测试
学习资料
- CPLusPlus.com
- CppReference.com
- gcc.gnu.org
- 《STL源码剖析》
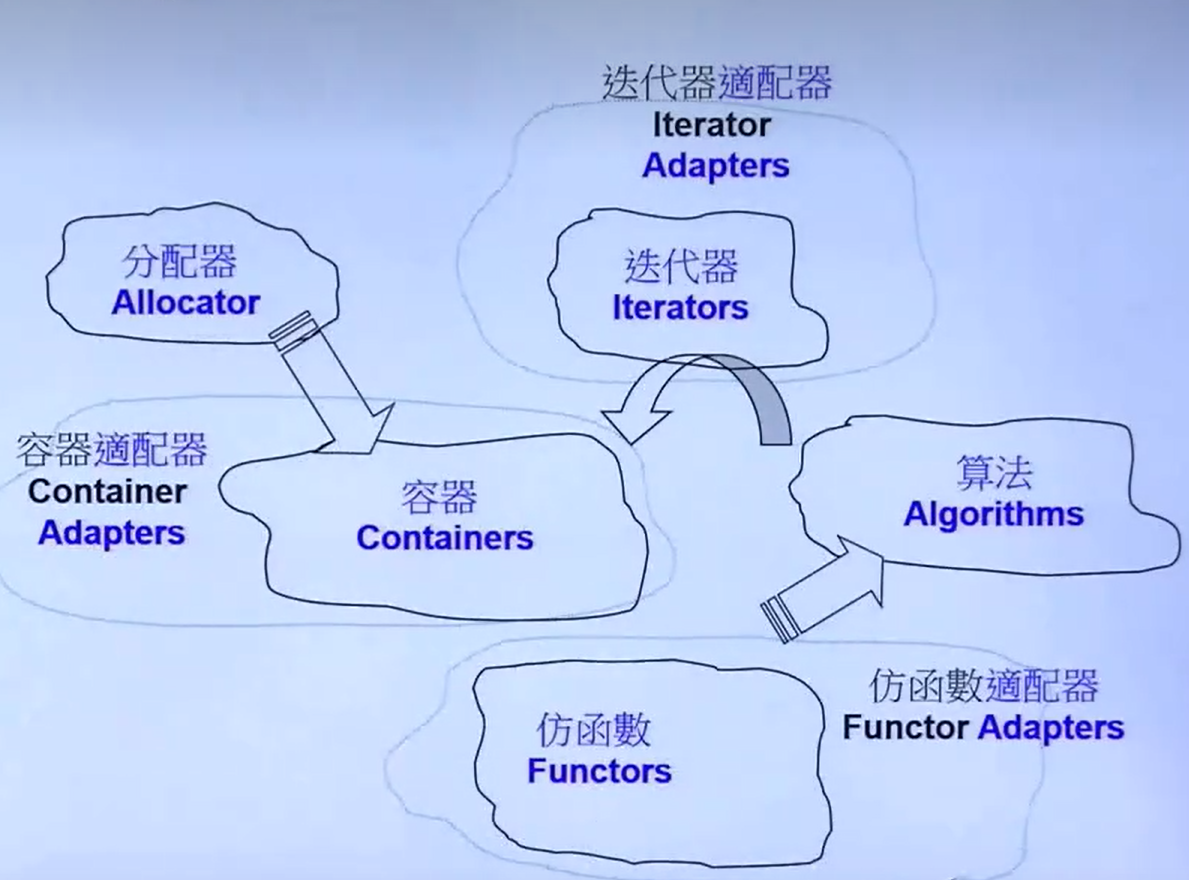
STL六大组件
- 容器-Containers,申请内存用于存储数据
- 分配器-Allocators,配合容器分配内存
- 算法- Algorithms,处理某一数据的最优办法
- 迭代器- Iterators,指针的泛型,本质与指针类似
- 适配器- Adapters,
- 仿函数-Functors,类似函数。
六者的关系
- 4.C++2.0特性的使用
VS 2022的设置
首先你可以先用下面的代码测试使用可以执行:
#include <iostream> void printTypes() { } template <typename T, typename... U> void printTypes(const T& t, const U&... u) { std::cout << t << std::endl; printTypes(u...); } int main() { printTypes('a', 1.5, 'b'); }如果报错了,如typename…未定义,那么请你按照如下步骤操作,

- 3.导读
书籍推荐
- 《C++ Premier》
- 《C++ Programming Language》
- 《Effective Modern C++》
- 《Efficient C++》
- 《The C++ standard library》
- 《STL C++》
- 《STL源码剖析》
- 《算法+数据结构=程序》
- “网站CPLusPlus”
- “网站CppReference”
- “网站gcc.gnu”
学习路线

- 2.组合与继承
类与类的三种关系
Composition-复合
以我个人的理解,复合就是一个类中包含有另外一个类,使用到另一个类的内容。复合的类他们的构造和析构函数运行次序是,构造函数有内到外依次运行,析构函数则相反。可以使用下图表示这种关系
- 1.代码编写规范
如何写一个标准的.h文件
以下内容来自B站。
接下来将以复数的库文件为例来回答这个问题,下面是一段参考复数库文件代码:
class complex { private: /* data */ double re,im; friend complex& __doapl (complex*,const complex&); public: complex (double r,double i) :re(r),im(i) //这是一个构造函数,这种写法意思是初始化变量 {}; complex& operator += (complex operator&); double read () const {return re;} //这里需要加const 意思就是修饰函数的返回值,不允许改变返回值类型 double imag () const {return im;} };构造函数的特性
这一点需要关注下面的代码:
-
17.C加加编程 的子部分
15.计算机图形学OpenGL与C++
理解GLFW和GLAD
GLFW()
GLFW是一个开源的、跨平台的库,用于创建窗口、处理输入和渲染图形。它提供了一种简单的方式来与OpenGL进行交互,使得开发图形应用程序变得更加容易。
GLFW的主要功能包括:
- 创建窗口
- 定义上下文
- 处理用户输入
GLAD()
GLAD是一个开源的、跨平台的库,用于管理OpenGL的函数指针。它提供了一种简单的方式来获取OpenGL的函数指针,使得开发OpenGL应用程序变得更加容易。
相关说明:
- OpenGL本身知识规范/标准
- 各个厂家具体实现方式可以不同
- 不同操作系统处理方式也可以不同
主要功能:
- 获取OpenGL函数指针
- 处理OpenGL版本兼容性问题
- 处理OpenGL扩展函数 ……
如果没有GLAD库,在Windows下:
typedef void (*GL_GENBUFFER) (GLsizei,GLuint*);//声明函数指针
GL_GENBUUFFER glGenBuffer = (GL_GENBUFFER)wglGetProcAddress('glGenBuffer');//获取函数指针
unsigned int buffer;//声明缓冲区对象
glGenBuffer(1,&buffer);//调用函数
有了GLAD库,只需要:
unsigned int buffer;
glGenBuffer(1,&buffer);14.新标准C加加程序设计
内存分区模型
内存代码区的意义:程序代码放在不同的区域,有程序自动管理的代码,也有程序员管理的代码,灵活管理;
一、程序执行前
1.代码区 存放二进制指令,就是代码,特点:
- 共享:多个进程的代码区是共享的,因为代码是相同的,所以只需要加载一份到内存中即可,节省内存空间。
- 只读:代码是只读的,防止程序意外地修改了代码。
2.全局区 全局变量和静态变量存储在全局区,还包括常量区、字符串常量和其他常量(如:const),特点:
- 全局区是程序结束后由系统释放。
- 全局变量和静态变量在程序结束后系统会自动释放,而局部变量在函数结束后由系统自动释放。
例子:
#include <iostream>
using namespace std;
//全局变量
int g_a = 10;
int g_b;
//const 修饰的全局变量
const int c_g_a = 10;
int main(int argc,char *argv[]){
//局部变量
int a = 10;
int b = 20;
//静态变量
static int s_a = 10;
static int s_b;
//字符串常量
char *P = "hello world";
//const修饰的局部变量
const int c_l_a = 10;
cout<<"局部变量a的地址:"<<&a<<endl;
cout<<"局部变量b的地址:"<<&b<<endl;
cout<<"全局变量a的地址:"<<&g_a<<endl;
cout<<"全局变量b的地址:"<<&g_b<<endl;
cout<<"静态变量a的地址:"<<&s_a<<endl;
cout<<"静态变量b的地址:"<<&s_b<<endl;
cout<<"字符串常量P的地址:"<<P<<endl;
cout<<"const修饰的局部变量c_l_a的地址:"<<&c_l_a<<endl;
cout<<"const修饰的全局变量c_g_a的地址:"<<&c_g_a<<endl;
return 0;
}3.总结
- 代码区:存放二进制指令,共享,只读。
- 全局区:存放全局变量和静态变量,程序结束后由系统释放。
二、程序运行后
1.栈区
由编译器自动分配释放,存放函数的参数值,局部变量等。
注意: 不要返回局部变量的地址,因为局部变量在函数结束后会被系统释放,再次访问会导致程序崩溃。
例子:
#include <iostream>
using namespace std;
int *GetAddr(int b){//形参数据也放在栈区
b = 10;
int a = 10;
return &a;//返回局部变量的地址
}
int main(){
int *p = GetAddr();
cout<<*p<<endl;//第一次可以打印正确的数据,是因为编译器做了保留,
cout<<*p<<endl;// 但是第二次访问将不再保留
return 0;
}2.堆区
由程序员分配释放,如果程序员不释放,程序结束时由系统回收。
在C++中主要利用new和delete操作符进行动态内存管理。
例子1-在堆上开辟空间:
#include <iostream>
using namespace std;
int* getAddr(){
//在堆上开辟空间,并初始化为10
int *p = new int(10);//new出来的数据返回的是一个指针
//使用存在栈区的局部指针指向堆区的数据,栈区的内容会被程序自动释放,但是指向堆区的数据不会被释放
return p;
}
int main(){
int *p = getAddr();
cout<<*p<<endl;//输出10
delete p;//释放空间
return 0;
}图解:
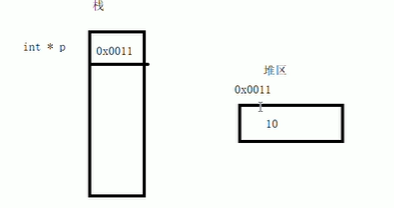
例子2-堆区上的数据开辟与释放
#include <iostream>
using namespace std;
void test(){
int *P = new int(10);
cout<<*P<<endl;
delete P;
}
void test2(){
int *arr = new int[10];
for(int i = 0;i<10;i++){
arr[i] = i+10;
}
for(int i = 0;i<10;i++){
cout<<arr[i]<<" ";
}
delete[] arr;
}
int main(){
test();
}引用
给变量取别名。
一、变量引用
引用注意事项:
- 引用必须初始化,int &b;//这样是不正确的
- 引用初始化后不能改变
- 通过引用参数产生的效果与指针地址传递效果一样,引用语法更清楚;
测试代码:
//值传递
void test1(int a,int b) {
}
//地址传递
void test2(int *a,int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
//引用传递
void test3(int &a,int &b) {
int temp = a;
a = b;
b = temp;
}二、应用做函数的返回值
- 不要返回局部变量的引用
- 函数返回值是引用,那么这个函数调用可以作为左值
测试代码:
// 二、引用做函数返回值
//1.不能返回应用返回值
int& test04()//以引用的方式返回b,相当于给这个b起了一个别名
{
int b = 10;//局部变量存放在栈区,函数结束后会被释放
return b;
}
//2. 函数的调用可以作为左值
int& test05()
{
static int b = 10;//静态变量存放在全局区,程序结束后由系统自动释放
return b;
}
int main()
{
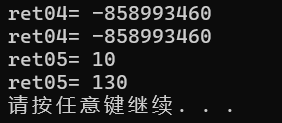
int& ret04 = test04();
int& ret05 = test05();
std::cout << "ret04= "<<ret04 << std::endl;
std::cout << "ret04= " << ret04 << std::endl;//第二次访问返回的是乱码
std::cout << "ret05= " << ret05 << std::endl;
test05() = 130;//函数的返回是引用,函数的调用可以作为左值
std::cout << "ret05= " << ret05 << std::endl;
system("pause");
return 0;
}测试代码结果
三、引用的本质
引用的本质在C++内部实现是一个指针常量,引用类型必须和引用实体是同类型。
四、常量引用
作用:用来修饰形参,防止误操作。
代码说明:
//四、常量引用
//int &ref = 10; 这样的操作是不被允许的,因为赋值给引用的是一个字面量,引用需要一个合法的空间,
// 程序运行时没有专门为其分配可修改的内存空间
// 但是如果在前面在上const,这条代码就通过
// const int &ref = 10;
//用来修饰形参,防止误操作
void test06(const int &val)
{
//val = 100;不被允许修改
std::cout << "val = " << val << std::endl;
}函数进阶
一、函数默认参数
返回值 函数名(参数 = 默认值){}
注意事项:
1.如果某个位置已经有了默认参数,那么该位置往后都必须有默认参数
//函数默认参数
void test(int a ,int b = 20,int c = 30)
{
std::cout << "a = " << a << std::endl;
std::cout << "b = " << b << std::endl;
std::cout << "c = " << c << std::endl;
}2.函数的声明有默认参数,函数实现不能有默认参数,声明和实现只能有一个有默认值
#include <iostream>
//函数声明
void test(int a=10,int b = 20);//
//函数实现
void test(int a ,int b)
{
std::cout << "a = " << a << std::endl;
std::cout << "b = " << b << std::endl;
}二、函数占位参数
作用:为了函数声明和定义的统一 语法:返回类型 函数名(数据类型){}
//函数占位参数
void test(int a,int)//第二个参数为占位参数
{
std::cout << "a = " << a << std::endl;
}
int main() {
test(10,10);//占位参数必须填补,否则无法运行
}注意:占位参数可以有默认参数,此时调用时就不用在传值
//函数占位参数
void test(int a,int = 10)//第二个参数为占位参数,含默认值
{
std::cout << "a = " << a << std::endl;
}
int main() {
test(10);//不需要传站位参数
}三、函数重载
满足条件:
- 在同一个作用域下。
- 函数名相同,
- 参数类型不同,
- 参数个数不同,
- 参数顺序不同。
作用: 提高复用性
注意:
1.返回值不能作为重载的条件
2.引用作为重载的条件
加const和不加是可以重载的
void fun(int &a){
std::cout<<"fun(int &a)"<<std::endl;
}
void fun(const int &a){
std::cout<<"fun(const int &a)"<<std::endl;
}
int main(){
int a = 10;
const int &b = 20;
fun(a);//调用fun(int &a)
fun(b);//调用fun(const int &a)
fun(10);//调用fun(const int &a)
return 0;
}3.函数重载遇到默认参数
void fun2(int a,int b = 10){
std::cout<<"fun(int &a)"<<std::endl;
}
void fun2(int a){
std::cout<<"fun(const int &a)"<<std::endl;
}
int main(){
fun2(10);//此时程序出现二义性,无法确定调用哪个函数
return 0;
}类和对象的基本概念
C++的特性:封装、多态、继承
一、基本概念
- 抽象:将事物所能进行的的行为归纳出来,形成函数,这些函数可以操作事物归纳后的数据结构。
- 类: 、
封装
将事物归纳的数据结构和操作该数据结构的算法呈现显而易见的紧密关系,叫封装。
一、 封装的意义
1.将属性和行为作为一个整体,表现生活中的事物。
namespace test_class
{
//设计一个圆的类
#define PI 3.14
class Circle
{
//访问权限
public:
//属性
int m_r;
//行为
double calculateZC()
{
return 2 * PI * m_r;
}
};
void test() {
Circle c1;
c1.m_r = 10;
cout << "圆的周长 = " << c1.calculateZC() << endl;
}
}2.访问权限
- public 公共权限
- protected 保护权限
- private 私有权限
二、访问权限说明
- public修饰的成员,可以在类内或者类外直接访问
- protected修饰的成员,只能在类内和子类中访问
- private修饰的成员,只能在类内访问
三、struct 与 Class 的区别
- 默认访问权限不同
- struct 默认权限为 public
- class 默认权限为 private
四、设置访问权限
一般对于变量设置为private,当要访问private的变量时,通过public的函数来访问。
namespace test_class
{
class Person
{
private:
//姓名
string m_Name;
//年龄
int m_Age;
public:
void setAge(int age)
{
m_Age = age;
}
};
int main(){
Person p;
p.setAge(18);
return 0;
}
}对象特性
一、初始化和清零 如果我们不提供构造函数,编译器会自动提供默认构造函数,但两个函数是空实现。
1.作用
- 构造函数:主要作用在于粗昂见对象那个时为对象成员属性赋值,
- 析构函数:主要作用在于对象销毁前系统自动调用析构函数,执行一些清理工作。
2.语法

二、构造函数的分类及调用
- 按参数分类:有参构造和无参构造(默认构造函数)
- 按类型分类:普通构造和拷贝构造
3.调用规则
- 如果定义了有参构造,最好显示定义无参构造
- 如果定义了拷贝构造,最好显示定义赋值构造
namespace test
{
//构造函数的分类及调用
//分类 按照参数分:有参构造函数和无参构造函数(默认构造函数)
// 按照类型分:普通构造和拷贝构造
class Person
{
public:
Person() {
cout << "调用无参构造函数" << endl;
}
Person(int Age)
{
age = Age;
cout << "调用有参构造函数" << endl;
}
Person(const Person &p)
{
age = p.age;
cout << "调用拷贝构造函数" << endl;
}
~Person() {
cout << "调用析构函数" << endl;
}
private:
int age;
};
//调用
void test() {
//1.括号法
Person p1;
Person p2(18);
Person p3(p2);
//注意事项
// 如果写的是 Person p1();那么编译器会认为是函数声明,而不会调用默认构造函数
//2.显示法
Person p1;
Person p2 = Person(10);
Person p3 = Person(p2);
//匿名对象:只写Person (10)的形式,特点是当前行执行结束后,系统会立即回收
// 注意2:
// 不要使用拷贝构造函数初始化匿名对象、编译器会认为Person (p3) === Person p3;即对象声明
//3.隐式调用
Person p4 = 10;//隐式转换为Person p4 = Person(10);
}
}三、拷贝构造函数调用时机
1.使用一个已经创建完毕的对象来初始化一个新对象 2.值传递的方式给函数参数传值 3.值方式返回局部对象
namespace test_copy
{
//拷贝构造函数调用时机
class Person
{
public:
Person() {
cout << "调用无参构造函数" << endl;
}
Person(int Age)
{
age = Age;
cout << "调用有参构造函数" << endl;
}
Person(const Person& p)
{
age = p.age;
cout << "调用拷贝构造函数" << endl;
}
int getAge() {
return age;
}
~Person() {
cout << "调用析构函数" << endl;
}
private:
int age;
};
//1.使用一个创建好的对象初始化一个新的对象
void test01() {
Person p(19);
Person p2(p);
}
//2.值传递方式传给函数参数传值
void doWork01(Person p){
cout << "值传递方式调用拷贝构造函数" << endl;
}
//3.以返回值的方式返回
Person doWork02() {
Person p1;
cout << (int*)&p1 << endl;
return p1;//返回时不直接返回p而是通过拷贝构造函数,拷贝一份返回给外面。当然,也有存在被编译器优化的情况
//这个时候就不会调用拷贝构造函数
}
void test02() {
Person p = doWork02();
cout << (int*)&p << endl;
//cout << p.getAge() << endl;
}
}四、构造函数调用规则
1.默认情况下,c++编译器至少给一个类添加3个函数
- 默认构造函数(无参,函数体为空)
- 默认析构函数(无参,函数体为空)
- 默认拷贝构造函数,对属性值进行拷贝
2.如果我们提供了有参构造函数,编译器就不会提供默认构造函数,但会提供默认拷贝构造函数
3.如果我们提供了拷贝构造函数,编译器就不会提供其他构造函数
五、深拷贝与浅拷贝
1.浅拷贝:简单的赋值拷贝操作 2.深拷贝:在堆区重新申请空间,进行拷贝操作
namespace test_deepcopy
{
class Person
{
public:
Person(int age,int height);
Person(const Person& p);
~Person();
int m_Age;
int* m_Height;
};
Person::Person(int age,int height)
{
m_Age = age;
m_Height = new int(height);//在堆区申请一块内存空间用于存储身高
cout << "调用构有参造函数" << endl;
}
Person::Person(const Person& p)
{
m_Age = p.m_Age;
//m_Height = p.m_Height;//这段代码就是浅拷贝操作
m_Height = new int(*p.m_Height);//这段代码就是在堆区另申请内存空间,存储赋值过来的身高值
}
Person::~Person()
{
if (m_Height != NULL)
{
delete m_Height;
m_Height = NULL;//避免野指针出现置空
}
cout << "调用析构函数" << endl;
}
void test()
{
Person p(18, 180);
cout << "person年龄:" << p.m_Age << "身高:" << *p.m_Height << endl;
// 为测试浅拷贝与深拷贝写如下代码
Person p1(p);//在没有写拷贝构造函数中的申请内存空间情况下,程序会报错,原因是程序是浅拷贝,导致第二次调用析构函数的时候报错
cout << "person年龄:" << p1.m_Age << "身高:" << *p1.m_Height << endl;
}
}结果如下:

六、初始化列表
1.作用
用于初始化属性
2.语法

namespace test_init
{
class Person
{
public:
//初始化列表
//Person() :m_A(10), m_B(20), m_C(30) { }
Person(int a,int b,int c) :m_A(a), m_B(b), m_C(c) { }
~Person() {}
int m_A;
int m_B;
int m_C;
};
void test() {
Person p(10, 20, 30);
cout << "m_A:" << p.m_A << endl;
cout << "m_B:" << p.m_B << endl;
cout << "m_C:" << p.m_C << endl;
}
}七、类对象作为类成员
1.类中的成员可以是另一个类的对象,我们称该成员为对象成员
2.类对象作为类成员时,其构造顺序和声明顺序一致,析构顺序和构造相反
八、静态成员
1.静态成员变量
- 所有对象共享同一份数据
- 在编译阶段分配内存
- 类内声明,类外初始化
2.静态成员函数
- 所有对象共享同一个函数
- 静态成员函数只能访问静态成员变量
namespace test_static
{
class Person
{
public:
### 继承
### 多态
### 类
将数据结构和操作该数据结构的函数捆绑在一起形成一个类。
### 在类中使用缺省函数
需要注意避免二义性:

## 构造函数
### 类中为什么需要构造函数

### 构造函数在数组中的使用
```cpp
class A{
int a;
public:
A(){std::cout<<"hello\n";}//1
A(int b){std::cout<<"value: "<<b<<std::endl;}//2
}
int main(){
A arr[2] = {1};
}上面的语句就调用了第1,2个构造函数,首先数据里的1会调用2,而数组的第二个是空值那么就会调用第1个。
复制构造函数-copy constructor
函数名与类名相同,参数为A(A& a)或A(const A& a)(二选一)。
三种情况下复制构造函数起作用
- 同类对象a,b,将a的值初始化b;
- A a; A b(a);
- 将类当作参数传入函数;
- 将类作为返回值;
注意:对象之间的复制是不会导致复制构造函数的
转换构造函数
什么是转换构造函数

示例代码:
 在上面的例子当中,
在上面的例子当中,c1 = 9;会被自动转换为调用转换构造函数,如果不想让这样的事情发生,可以在转换构造函数前面加上修饰字段 explicit,这样再次使用c1 = 9;时程序会报错。
析构函数-destructors
这里补充几点,一个类只能有一个析构函数;
析构函数与数组:
数组成员的每一次结束时都会调用析构函数,假设类A数组array[2],则生命周期结束时会调用两次析构函数。
析构函数什么时候被调用呢?
class CMyclass {
public:
~CMyclass() { cout << "destructor" << endl; }
};
CMyclass obj;
CMyclass fun(CMyclass sobj ) { //参数对象消亡也会导致析
//构函数被调用
return sobj; //函数调用返回时生成临时对象返回
}
int main(){
obj = fun(obj); //函数调用的返回值(临时对象)被
return 0; //用过后,该临时对象析构函数被调用
}上面结果输出三个destructor,在fun(CMyclass sobj)参数对象消亡调用析构函数(具体可以联想复制构造函数),会调用一次析构函数;当函数返回赋值给obj后,再次调用析构函数;整个程序结束再次调用析构函数。

this指针

静态成员函数中可以直接使用this指针来代表指向该函数作用的对象的指针
示例1:
class Complex {
public:
double real, imag;
void Print() { cout << real << "," << imag ; }
Complex(double r,double i):real(r),imag(i)
{ }
Complex AddOne() {
this->real ++; //等价于 real ++;
this->Print(); //等价于 Print
return * this;
}
};
int main() {
Complex c1(1,1),c2(0,0);
c2 = c1.AddOne();//调用AddOne函数后内部this指针变为c1,所以是c1中的read++
return 0;
} //输出 2,1
示例2:
class A
{
int i;
public:
void Hello() { cout << i << "hello" << endl; }
}; // 翻译为void Hello(A * this ) { cout << this->i << "hello"<< endl; }
int main()
{
A * p = NULL;
p->Hello(); //翻译为Hello(p);
} //编译报错
报错的原因是p指针式一个空指针,它并不指向任何A的对象,所以编译到 this->i 会报错。
静态成员变量和函数
基本特点:
- 普通成员变量每个对象有各自的一份,而静态成员变量一共就一份,为所有对象共享。
- 普通成员函数必须具体作用于某个对象,而静态成员函数并不具体作用于某个对象。因此静态成员不需要通过对象就能访问。
对第二句话的理解,如下代码示例:
class Dog {
public:
// 普通成员函数
void bark() {
std::cout << "Woof!" << std::endl;
}
// 静态成员函数
static std::string getSpecies() {
return "Canine";
}
};要调用bark我们需要先创建一个Dog的类对象,然后通过 . 调用,也就是非静态成员作用于对象的意思,但是对于 getSpecies 就不需要,可以直接 Dog::getSpecies调用。
如何访问静态成员?
-
类名::成员名 CRectangle::PrintTotal();
-
对象名.成员名 CRectangle r; r.PrintTotal();
-
指针->成员名 CRectangle * p = &r; p->PrintTotal();
-
引用.成员名 CRectangle & ref = r; int n = ref.nTotalNumber;
设置静态成员变量的目的是什么?
设置静态成员这种机制的目的是将和某些类紧密相关的全局变量和函数写到类里面,看上去像一个整体,易于维护和理解。比如,考虑一个需要随时知道矩形总数和总面积的图形处理程序,可以用全局变量来记录总数和总面积,用静态成员将这两个变量封装进类中,就更容易理解和维护。
注意事项:
- 必须在定义类的文件中对静态成员变量进行一次说明或初始化。否则编译能通过,链接不能通过。
- 在静态成员函数中,不能访问非静态成员变量,也不能调用非静态成员函数。
成员对象和封闭类
- 有成员对象的类叫 封闭(enclosing)类。
- 任何生成封闭类对象的语句,都要让编译器明白,对象中的成员对象,是如何初始化的。具体的做法就是:通过封闭类的构造函数的初始化列表。
封闭类的复制构造函数:
class A
{
public:
A() { cout << "default" << endl; }
A(A & a) { cout << "copy" << endl;}
};
class B { A a; };
int main()
{
B b1,b2(b1);//b2调用自生默认复制构造函数,而内部的A a也会调用默认的复制构造函数
return 0;
}友元
- 友元函数: 一个类的友元函数可以访问该类的私有成员。
- 可以将一个类的成员函数(包括构造、析构函数)说明为另一个类的友元。
- 友元类: 如果A是B的友元类,那么A的成员函数可以访问B的私有成员。
- 友元类之间的关系不能传递,不能继承。
常量成员
常量成员函数:内部不能改变属性的值,也不能调用非常量成员函数。
**注意:**如果一个成员函数中没有调用非常量成员函数,也没有修改成员变量的值,那么,最好将其写成常量成员函数。 mutable成员变量 可以在const成员函数中修改的成员变量
class CTest
{
public:
bool GetData() const
{
m_n1++;//这个值更可以更改
return m_b2;
}
private:
mutable int m_n1;
bool m_b2;
};运算符重载函数
浅拷贝与深拷贝:
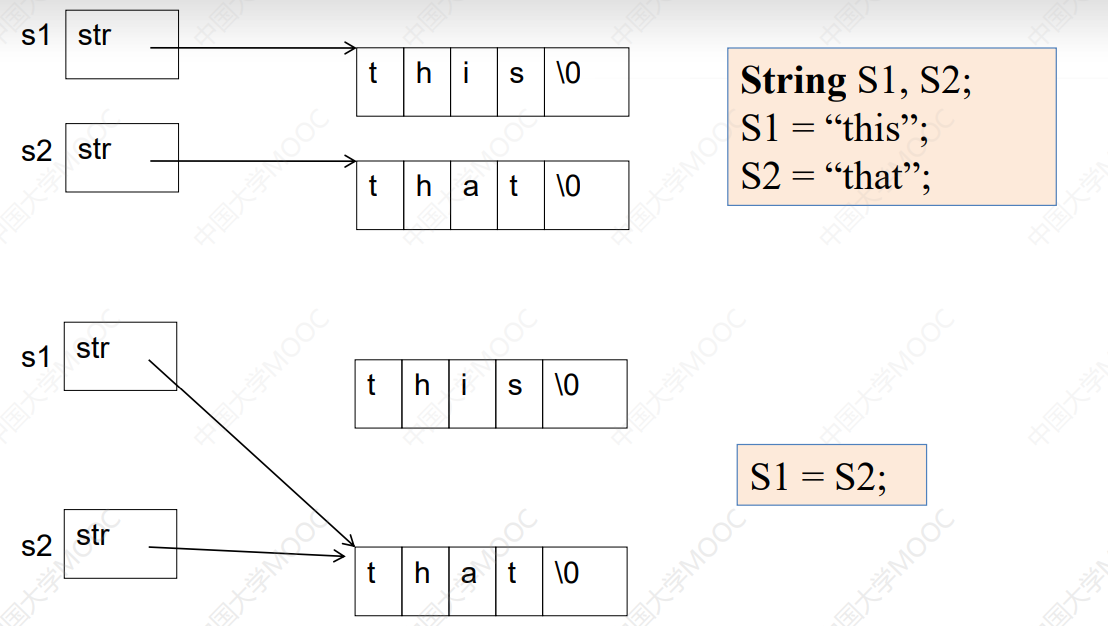
为解决这个问题,我们需要修改赋值运算符重载:
String & operator = (const String & s){
if( this == & s)
return * this;
delete [] str;
str = new char[strlen(s.str)+1];
strcpy( str,s.str);
return * this;
}自增自减运算法重载
class CDemo {
private :
int n;
public:
CDemo(int i=0):n(i) { }
CDemo & operator++(); //用于前置形式
CDemo operator++( int ); //用于后置形式
operator int ( ) { return n; }
friend CDemo & operator--(CDemo & );
friend CDemo operator--(CDemo & ,int);
}operator int ( ) {return n;}
这里,int 作为一个类型强制转换运算符被重载, 此后
Demo s;
(int) s ; //等效于 s.int();
类型强制转换运算符被重载时不能写返回值类型,实际上其返回值类型就是该类型强制转换运算符代表的类型。
继承和派生
**注意:**在派生类的各个成员函数中,不能访问基类中的private成员。
派生类的内存空间

类之间的关系
继承:“是”关系。
- 基类 A,B是基类A的派生类。
- 逻辑上要求:“一个B对象也是一个A对象”。
复合:“有”关系。
- 类C中“有”成员变量k,k是类D的对象,则C和D是复合 关系
- 一般逻辑上要求:“D对象是C对象的固有属性或组成部 分”
复合关系的示例:

基类与派生类名字重名的情况
一般来说,基类和派生类不定义同名成员变量。但如果要方位可以使用基类::基类成员来访问。
访问权限
• 基类的private成员:可以被下列函数访问
- 基类的成员函数
- 基类的友元函数
• 基类的public成员:可以被下列函数访问
- 基类的成员函数
- 基类的友元函数
- 派生类的成员函数
- 派生类的友元函数
- 其他的函数
• 基类的protected成员:可以被下列函数访问
- 基类的成员函数
- 基类的友元函数
- 派生类的成员函数可以访问当前对象和其它对象的基类的保护成
举一个例子:
class Father {
private: int nPrivate; //私有成员
public: int nPublic; //公有成员
protected: int nProtected; // 保护成员
};
class Son :public Father{
void AccessFather () {
nPublic = 1; // ok;
nPrivate = 1; // wrong
nProtected = 1; // OK,访问从基类继承的protected成员
Son f;
f.nProtected = 1; //ok,派生类的成员函数可以访问当前对象和其它对象的基类的保护成
}
};
int main(){
Father f;
Son s;
f.nPublic = 1; // Ok
s.nPublic = 1; // Ok
f.nProtected = 1; // error,因为只能在派生类(或友元类)中访问
f.nPrivate = 1; // error
s.nProtected = 1; //error
s.nPrivate = 1; // error
return 0;
}派生类构造函数中包含成员变量时该如何写?
class Bug {
private :
int nLegs; int nColor;
public:
int nType;
Bug ( int legs, int color);
void PrintBug (){ };
};
class Skill {
public:
Skill(int n) { }
};
class FlyBug: public Bug {
int nWings;
Skill sk1, sk2;
public:
FlyBug( int legs, int color, int wings);
};
FlyBug::FlyBug( int legs, int color, int wings):
Bug(legs,color),sk1(5),sk2(color) ,nWings(wings) { }//注意这种写法。
private 和 protected的继承
• protected继承时,基类的public成员和protected成员成为派生类的protected成员。 • private继承时,基类的public成员成为派生类的private成员,基类的protected成员成 为派生类的不可访问成员。 • protected和private继承不是“是”的关系。
问题:
即便基类指针指向的是一个派生类的对象,也不能通过基类指针访问基类没有,而派生类中有的成员。
解决办法:
通过强制指针类型转换,可以把ptrBase转换成Derived类的指针
Base * ptrBase = &objDerived;
Derived *ptrDerived = (Derived * ) ptrBase;程序员要保证ptrBase指向的是一个Derived类的对象,否则很容易会出错。
虚函数和多态
多态的表现形式
- 派生类的指针(或引用)可以给基类赋值。
- 当指针指向基类时调用,基类的函数,当指针指向派生类时,调用调用派生类的函数,这叫做多态。
- 另外,在非虚函数和非构造、析构函数中调用虚函数,也叫做多态。
例子:

如果在构造、析构函数中调用虚函数,那么会怎么样呢?
如果这么做,那么编译器只会调用当前的虚函数,如果当前没有重写虚函数,则会从基类中找进行调用,为什么要这么做呢?其实这是为了防止未初始化就调用派生类的虚函数的情况。
你想想啊,一类的初始化先从基类的构造函数开始,如果这个时候构造函数具有多态性,那么此时将调用派生类的对应虚函数,但是派生类这个时候都还没有初始化。
例子:
 `
`
- 补充:在上面的图例子中,派生类写了与基类虚函数相同的名字,但是没有在前面加修饰符virtual,这种情况编译器认为是虚函数。
多态的作用
在面向对象的程序设计中使用多态,能够增强程序的可扩充性,即程序需要修改或增加功能的时候,需要改动和增加的代码较少。
虚函数的访问权限

动态联编的实现机制
“多态”的关键在于通过基类指针或引用调用一个虚函数时,编译时不确定到底调用的是基类还是派生类的函数,运行时才确定 —- 这叫“动态联编”。
每一个有虚函数的类(或有虚函数的类的派生类)都有一个虚函数表,该类的任何对象中都放着虚函数表的指针。虚函数表中列出了该类的虚函数地址。多出来的4个字节就是用来放虚函数表的地址的。
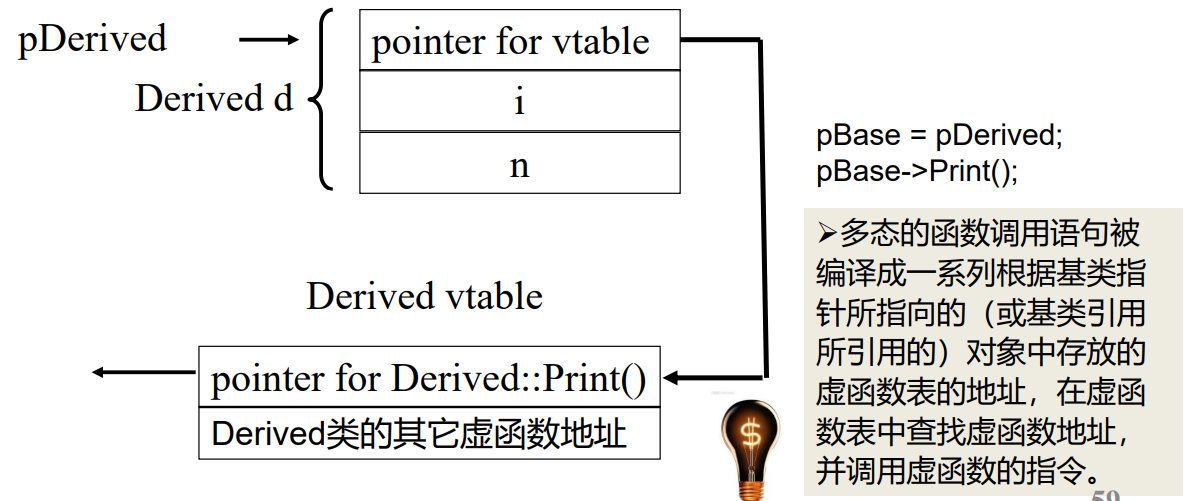
下面一段代码将验证,对象的首地址是存了虚函数表的地址的:
#include <iostream>
using namespace std;
class A {
public: virtual void Func() { cout << "A::Func" << endl; }
};
class B:public A {
public: virtual void Func() { cout << "B::Func" << endl; }
};
int main() {
A a;
A * pa = new B();
pa->Func();
//64位程序指针为8字节
long long * p1 = (long long * ) & a;
long long * p2 = (long long * ) pa;
* p2 = * p1;
pa->Func();
return 0;
}纯虚函数和抽象类
- 纯虚函数:没有函数体的虚函数
- 抽象类:有纯虚函数的类
注意:
- 包含纯虚函数的类叫抽象类
- 抽象类只能作为基类来派生新类使用,不能创建独立的抽象类的对象
- 抽象类的指针和引用可以指向由抽象类派生出来的类的对象
A a ; // 错,A 是抽象类,不能创建对象
A * pa ; // ok,可以定义抽象类的指针和引用
pa = new A ; //错误, A 是抽象类,不能创建对象
- 在抽象类的成员函数内可以调用纯虚函数,但是在构造函数或析构函数内部不能调用纯虚函数。
- 如果一个类从抽象类派生而来,那么当且仅当它实现了基类中的所有纯虚函数,它才能成为非抽象类。
13.从C到C++
指针
指针的声明:
数组
数组的范围必须是常量表达式,同时如果需要变化的范围可以做如下定义:
2.字符串文字量
指的是用 ““括起来的字符串。
- 长字符串编写:

- 带有L的字符是宽字符,如L"sddsf”,类型是const wchar_t.
3.指向数组的指针
4.常量

5.指针和常量
使用一个指针时涉及到两个对象:该指针本身和被它所指的对象。将一个指针的声明用cons“预先固定”将使那个对象而不是使这个指针成为常量。要将指针本身而不是被指对象声明为常量,我们必须使用声明运算符*const,而不能只用简单的const。
定义常量指针的声明运算符是const。并没有cons** 声明符,所以出现在之前的conr是作为基础类型的一部分。例如
// 到char的hconst指针
char *const cp;
char const* pc;
// 到const char的指针
const char* pc2;
//到const char的指针
有人发现从右向左读这种定义很有帮助。例如,“cp是一个conse指针到char”,以及“pe2是一个指针措到const chor”
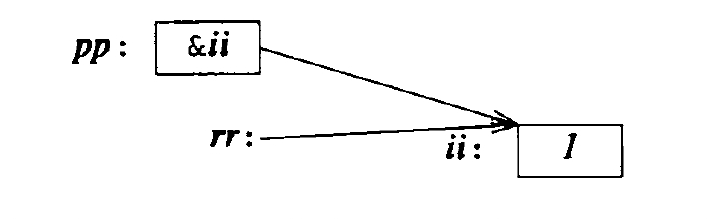
引用
void f(){
int ii=1;
int &rr = ii;
rr++;//实际上是ii++,rr不能像指针一样操作。
int *pp = ⅈ
}
12.其他库的介绍
为什么需要哈希函数?
哈希函数在计算机科学中扮演着重要的角色,其主要作用包括:
-
数据检索:哈希函数可以将键(key)映射到哈希表中的一个位置,从而快速检索数据。这是哈希表(如 C++ 中的
std::unordered_map和std::unordered_set)的基础。 -
快速比较:在数据库和各种数据结构中,哈希函数可以快速比较字符串或对象,常用于检查两个字符串是否相等。
-
数据分布:在分布式系统中,哈希函数可以将数据均匀地分布到多个节点上,以实现负载均衡。
-
密码学应用:在密码学中,哈希函数用于生成数据的摘要,用于数据完整性验证和数字签名。
-
缓存实现:哈希函数可以用于实现缓存机制,通过快速定位缓存中的数据。
-
负载均衡:在网络流量管理中,哈希函数可以用于将请求分配到不同的服务器上。
C++ 库中哈希函数的实现和底层逻辑
在 C++11 及以后的版本中,标准库提供了一个专门的哈希函数库 <functional>,其中包含了 std::hash 模板类。std::hash 为基本数据类型(如 int、double、std::string 等)提供了特化版本。
实现底层逻辑:
-
整数类型:对于整数类型,
std::hash直接返回数值本身或其变体。例如,对于int类型,std::hash<int>()(10)可能直接返回 10 或者 10 的一个简单变换。 -
浮点类型:对于浮点类型,
std::hash通常会将浮点数的位表示转换为整数,然后应用整数的哈希函数。 -
字符串类型:对于字符串,
std::hash通常会遍历字符串中的每个字符,将每个字符的哈希值组合起来,生成最终的哈希值。这可以通过位操作和数学函数(如乘法、加法、异或等)来实现。 -
自定义类型:对于自定义类型,如果需要使用
std::hash,则需要为该类型提供自定义的哈希函数。 -
组合哈希:对于复合类型(如结构体或类),哈希函数需要将各个成员的哈希值组合起来。这通常通过将成员的哈希值进行某种形式的数学运算(如加权求和、异或等)来实现。
-
均匀分布:一个好的哈希函数应该能够产生均匀分布的哈希值,以减少哈希冲突。
-
确定性:哈希函数应该是确定性的,即对于同一个输入总是产生相同的哈希值。
-
快速计算:哈希函数的计算应该尽可能快,以减少对性能的影响。
在 C++ 中,std::hash 的实现可能因编译器和平台而异,但基本原理是相似的。正确实现哈希函数对于哈希表的性能至关重要,因为它直接影响到哈希表的冲突率和检索效率。
hash function-哈希函数
如果要自己给自己的数据写一个哈希函数,那又该怎么写呢?能否基于这些数据计算出hash code的呢?
编写模版规范
#include <functional>
namespace test_hash_function
{
class Customer {
private:
string fname;
string lname;
int on;
public:
Customer( string fn, string ln, int id) : fname(fn), lname(ln), on(id) {}
bool operator==(const Customer& other) const {//需要重载==
return fname == other.fname && lname == other.lname && on == other.on;
}
friend class CustomerHash;
};
class CustomerHash {
public:
std::size_t operator()(const Customer& c) const {
return ...;
}
};
unordered_set<Customer, CustromerHash> custsct;
} #include <functional>
namespace test_hash_function
{
template <typename T>
inline void hash_combine(size_t& seed, const T& val) {
seed ^= hash<T>()(val) +
0x9e3779b9 +
(seed << 6) +
(seed >> 2);
}
template <typename T>
inline void hash_val(size_t& seed, const T& val) {
hash_combine(seed, val);
}
template <typename T, typename... Types>
inline void hash_val( size_t& seed,
const T& val,
const Types&... args)
{
hash_combine(seed, val);
hash_val(seed, args...);
}
template <typename... Types>
inline size_t hash_val(const Types&... args) {
size_t seed = 0;
hash_val(seed, args...);
return seed;
}
class Customer {
private:
string fname;
string lname;
int on;
public:
Customer( string fn, string ln, int id) : fname(fn), lname(ln), on(id) {}
bool operator==(const Customer& other) const {
return fname == other.fname && lname == other.lname && on == other.on;
}
friend class CustomerHash;
};
class CustomerHash {
public:
size_t operator()(const Customer& c) const {
return hash_val(c.fname, c.lname, c.on);
}
};
void test() {
unordered_set<Customer, CustomerHash> s;
s.insert(Customer("Asd", "dfw", 1L));
s.insert(Customer("Dfg", "kjt", 2L));
s.insert(Customer("VVB", "ert", 3L));
s.insert(Customer("TgR", "uik", 4L));
s.insert(Customer("Gdf", "pii", 5L));
s.insert(Customer("Gdf", "pii", 6L));
s.insert(Customer("Gdf", "pii", 7L));//8
cout << s.bucket_count() << endl;
CustomerHash hh;
cout << hh(Customer("Asd", "dfw", 1L)) % 8 << endl;//4
cout << hh(Customer("Dfg", "kjt", 2L)) % 8 << endl;//0
cout << hh(Customer("VVB", "ert", 3L)) % 8 << endl;//3
cout << hh(Customer("TgR", "uik", 4L)) % 8 << endl;//7
cout << hh(Customer("Gdf", "pii", 5L)) % 8 << endl;//2
cout << hh(Customer("Gdf", "pii", 6L)) % 8 << endl;//7
cout << hh(Customer("Gdf", "pii", 7L)) % 8 << endl;//4
for (unsigned i = 0; i < s.bucket_count(); i++) {
cout << "bucked #" << i << "has" << s.bucket_size(i) << "element\n";
}
}
}
// bucked #0has1element
// bucked #1has0element
// bucked #2has1element
// bucked #3has1element
// bucked #4has2element
// bucked #5has0element
// bucked #6has0element
// bucked #7has2element
#include <functional>
namespace test_hash_function
{
class Customer {
private:
string fname;
string lname;
int on;
public:
Customer( string fn, string ln, int id) : fname(fn), lname(ln), on(id) {}
bool operator==(const Customer& other) const {//需要重载==
return fname == other.fname && lname == other.lname && on == other.on;
}
friend class CustomerHash;
};
class CustomerHash {
public:
size_t customer_hash_func(const Customer& c) const {
return ...;
}
};
unordered_set<Customer, size_t(*)(const Custromer&)> custsct(20,customer_hash_func);//注意与类型1的不同写法
}第三种方式是对类里面的hash进行偏特化,比如你使用了unordered_set那么对于它的Hash,可以单独进行偏特化。

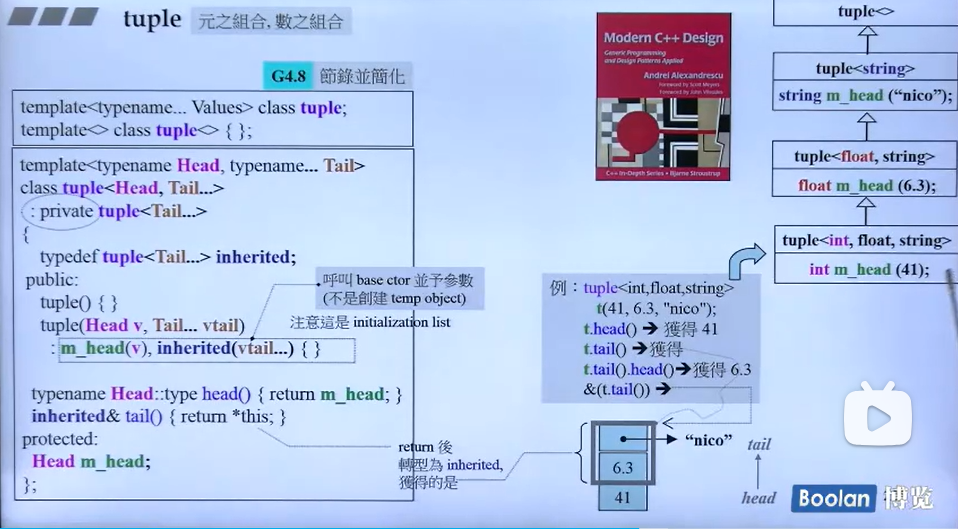
tuple
在C++中,tuple 是一个标准库模板类,它提供了一种方式来存储不同类型数据的集合。tuple 类似于一个固定大小的数组,但是数组中的每个元素可以是不同的类型。这个特性使得 tuple 非常灵活,可以用于多种场景。
11.STL库学习之适配器
整体框架的回顾
存在多种适配器-adapters
一个人理解,要将适配器理解透彻,我们需要先从别的组件入手,这里以vector容器为例,我们都知道该容器需要迭代器,也就是一些智能指针来确定容器的头尾,以及内容位置,目的是方便后续的算法的怎删改查等操作,假设算法现在要做拿到位置8的数据,那么vector的指针要怎么移动呢?已知指针移动上,vector是随机访问指针,也就是前后都可以跑,而这个操作实际上是迭代器的其中一个内容,而这一内容就需要一个适配器去做适配。
下面做一个模拟问答,来加以了解:
—c 模拟问答 算法:你好,vector的迭代器,我需要知道你的迭代器类别,这样我才能正确地进行操作。
vector的迭代器:好的,我先问一下我的适配器。
vector的迭代器:适配器,算法想知道 iterator_traits<InputIterator>::iterator_category 是什么类型的迭代器?
vector_iterator的适配器:你好,我们这里是随机访问迭代器(Random Access Iterator)。
算法:太好了,随机访问迭代器可以让我进行更高效的操作。那么,如果我想访问第8个元素,我该怎么做?
vector_iterator的适配器:很简单,你可以直接通过加上偏移量来访问第8个元素。比如,如果你有一个指向第一个元素的迭代器 first,那么 first + 7(因为迭代器是从0开始计数的)就会给你第8个元素的迭代器。
算法:明白了,那我可以直接使用 *(first + 7) 来获取第8个元素的值了。
vector_iterator的适配器:是的,完全正确。
算法:如果我需要反向迭代器,或者插入迭代器,你们能提供吗?
vector_iterator的适配器:当然可以。我们 vector 提供了多种迭代器适配器,包括反向迭代器(reverse_iterator)、插入迭代器(insert_iterator)等,以满足不同的需求。
算法:那太好了,这样我可以更灵活地处理 vector 中的数据了。谢谢你的帮助!
STL中适配器的重要特性
对于容器、迭代器和仿函数它们第二次迭代器都有一个重要的特性,就是适配器会包含(也有继承)对应的类,比如stack包含了deque,然后使用了deque的某些功能,屏蔽了deque的某些某能,实现了先进后出的功能。
仿函数适配器
binder2nd适配器
该适配器是用于绑定的,比如对于一个容器,需要操作比88小于数,这使用可以用binder2nd,第一个参数可以传入比较大小的less仿函数,第二个传入比较的数值x,本质上在binder2nd中,less的第二个参数传入就是x,这样就达到比较的目的了。
 小结:把A类和数值a传入另一个类B中,在B中再操作A和a.这样就实现了绑定。
小结:把A类和数值a传入另一个类B中,在B中再操作A和a.这样就实现了绑定。
not1
对结果取反

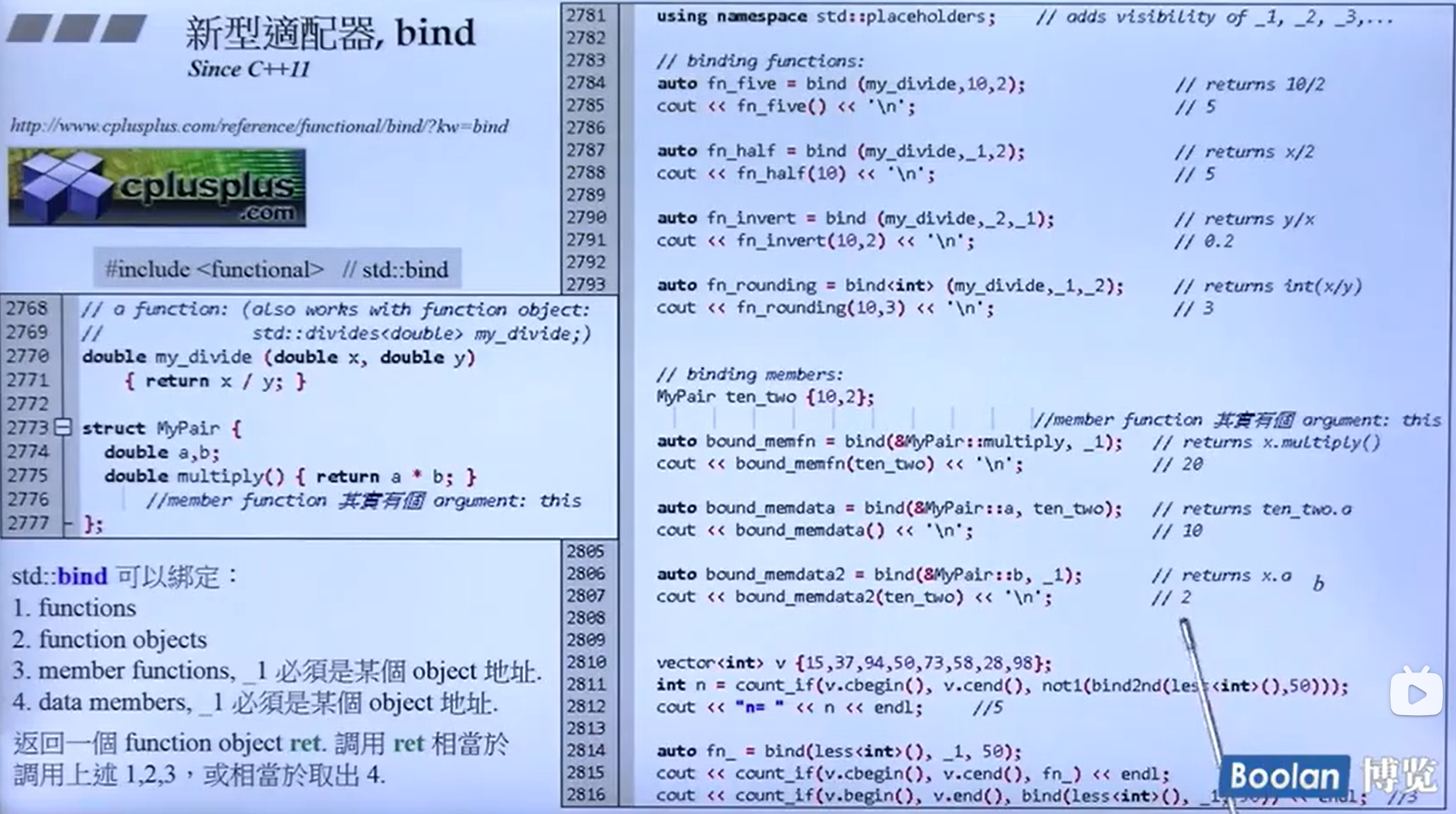
一些新的适配器

bind
迭代器适配器
reverse——iterator
三个细节:
- 1.begin=rend,end=rbigin
- 2.取值是取后一个,所以内部实现的*是做–操作;
- 3.operate ++()操作重载后内部实现为–,operate –()重载后内部实现++操作。
具体图下图所示

insert_iterator
在下面的案例中copy(bar.begin(),bar.end(),inserter(foo,it));欲将list的bar数据从it指向的位置
开始插入,但是foo的空间不够,为什么还能成功?
设计的小技巧,当传入copy中时,因为inserter对operate =()做了重载,重载中调用了insert()该函数能决绝以上问题,
因此不会因为foo的内存不足导致插入失败。

ostream_iterator
下面通过一个案例说明该迭代器的一些特性和使用方法:
1.当执行初始化操作std::ostream_iterator
istream_iterator
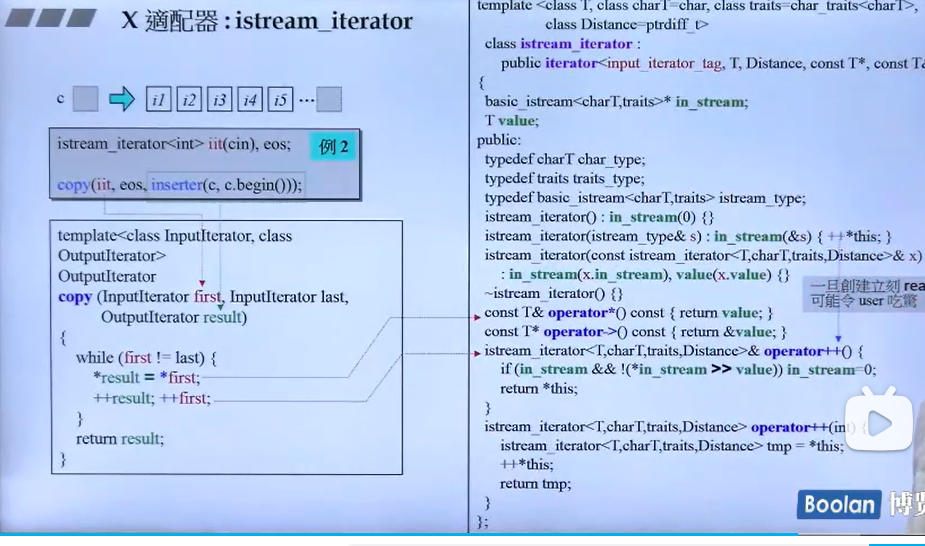
下面也是两个例子说明istream_iterator的特性:
1.std::istream_iterator<double> iit(std::cin);时同样会调用对应的构造函数,并且此处会调用operate ++()重载,在该重载中,*in_stream接收按键输入的一个值,也就是说才定义时,就已经在准备接收一个值,如果此时在该语句下写一段打印操作没见无法看到输出!

2.下面是copy操作,对于这个操作,我们可以观察是否有对*和=的操作符进行重载,对于=的重载上述已经介绍, *的重载是将value返回,也就是 *first的操作取得的是容器中的值。
10.STL库学习之仿函数
仿函数的个人理解
仿函数是行为类似函数的一个类,比较明显的特征是仿函数重载了operate(),比如你写了一个struct,并在里面重载了operate(),当调用这个类的()时就会返回响应的数据。
你的理解是正确的,仿函数(functor)是 C++ 中的一个概念,它指的是那些可以像函数一样被调用的对象。这些对象通常重载了函数调用操作符 operator(),使得对象可以被当作函数来使用。以下是对你描述的一些补充说明:
仿函数的特点
-
重载
operator():仿函数类必须重载函数调用操作符operator(),这样对象就可以被像函数那样调用。 -
可以携带状态:与普通函数不同,仿函数可以拥有成员变量,这意味着它们可以携带状态。这些状态可以是私有的,也可以是公开的,取决于仿函数的设计。
-
可以进行重载:仿函数可以重载
operator(),以接受不同数量和类型的参数。 -
可以定义在类中:仿函数可以是类的成员函数,也可以是独立的类。
-
可以有返回值:当仿函数被调用时,可以返回一个值,就像普通函数那样。
-
可以作为参数传递:由于仿函数可以像函数一样被调用,它们可以作为参数传递给接受函数作为参数的函数。
仿函数的应用
-
算法的参数:仿函数经常用作 STL 算法的参数,例如
std::sort和std::find_if,因为这些算法需要一个可以被调用的实体来比较元素或测试条件。 -
回调函数:在事件驱动的编程中,仿函数可以作为回调函数,响应特定的事件。
-
策略模式:在设计模式中,仿函数可以用于实现策略模式,允许算法的行为在运行时动态改变。
-
简化代码:通过使用仿函数,可以减少函数指针和全局函数的使用,使得代码更加简洁和易于管理。
示例代码
struct Max {
// 重载()操作符,使其可以被调用
int operator()(int a, int b) const {
return (a > b) ? a : b;
}
};
int main() {
Max max_functor;
int result = max_functor(10, 20); // 使用仿函数对象调用
std::cout << "Max value: " << result << std::endl;
return 0;
}在这个例子中,Max 是一个仿函数,它重载了 operator() 来比较两个整数并返回最大值。然后,我们可以像调用函数一样调用 max_functor 对象。
仿函数内部一般设计什么?
仿函数一般重载operate()后,会在内部设计运算操作,如算数、逻辑、相对关系等运算。如下图所示。
 从上面一张图也可以发现,plus,minus,logical_and,equal_to,less类都集成了binary_function,该类的作用是什么呢?
从上面一张图也可以发现,plus,minus,logical_and,equal_to,less类都集成了binary_function,该类的作用是什么呢?
std::binary_function 的主要作用是:
- 泛型框架:提供一个泛型框架,允许函数对象接受任意类型的参数。
- 类型转换:允许参数类型和返回类型的转换,使得函数对象可以用于不同的数据类型。
- 模板编程:支持模板编程,使得可以创建通用的算法和函数。
- 原型
std::binary_function 的原型如下:
template <class Arg1Type, class Arg2Type, class ResultType>
struct binary_function {
typedef Arg1Type first_argument_type;
typedef Arg2Type second_argument_type;
typedef ResultType result_type;
};-
Arg1Type:第一个参数的类型。 -
Arg2Type:第二个参数的类型。 -
ResultType:函数返回值的类型。 -
继承和使用
函数对象如 std::plus, std::minus, std::logical_and, std::equal_to, std::less 等都继承自 std::binary_function。这意味着这些函数对象都定义了 first_argument_type, second_argument_type, 和 result_type 这三个类型别名,它们分别表示函数对象接受的第一个参数类型、第二个参数类型和返回值类型。
关于 std::binary_function的具体细节在适配器一节会重点讲到。
下图是是否继承binary_function的一些示例,如果不继承会怎么样呢?以我个人的理解,继承会让仿函数的扩展性更高,它将来可以扩展出更好的功能。如下图所示。

除了上面讲到的binary_function还有unary_function,该类是针对单个变量的操作,比如取反,加加。如下图:

关于binary_function的细节此处先不介绍,下一节将着重说明。
对于仿函数,鲜明的特点就是对operate()做了重载,这样的类创建出来的对象叫仿函数对象,具有函数的行为。如果要对重载做更多操作需要结合一些仿函数适配器,比如相面讲到的binary_function和unary_funtion。
9.STL库学习之迭代器与算法
标准库常用算法
迭代器
迭代器-的分类
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag:public input_iterator_tag{};
struct bidirectional_iterator_tag:public forward_iterator_tag{};
struct random_access_tag:public bidirectional_iterator_tag {};以上5中迭代器的继承关系,如下图所示。
1.Input Iterator(输入迭代器): 输入迭代器是最基本的迭代器类型,支持单向遍历,只能向前移动。
用法示例:
std::vector<int> vec = {1, 2, 3, 4, 5};
std::input_iterator<int> it = vec.begin();
while (it != vec.end()) {
std::cout << *it << " ";
++it;
}2.Forward Iterator(前向迭代器): 前向迭代器支持双向遍历,可以向前和向后移动。
用法示例:
std::list<int> lst = {1, 2, 3, 4, 5};
std::forward_iterator<int> it = lst.begin();
while (it != lst.end()) {
std::cout << *it << " ";
++it;
}3.Output Iterator(输出迭代器): 输出迭代器允许对容器中的元素进行写操作,但不支持读操作。
用法示例:
std::vector<int> vec;
std::back_insert_iterator<std::vector<int>> it(vec);
*it = 1; // 写操作
++it;
*it = 2; // 写操作
4.Bidirectional Iterator(双向迭代器): 双向迭代器支持双向遍历,可以向前和向后移动。
用法示例:
std::list<int> lst = {1, 2, 3, 4, 5};
std::bidirectional_iterator<int> it = lst.end();
while (it != lst.begin()) {
--it;
std::cout << *it << " ";
}5.Random Access Iterator(随机访问迭代器): 随机访问迭代器支持任意位置的快速访问,类似于指针操作。
用法示例:
std::vector<int> vec = {1, 2, 3, 4, 5};
std::random_access_iterator<int> it = vec.begin();
it += 2; // 随机访问
std::cout << *it << " ";各种容器的迭代器类型
测试代码:
#include <iterator>
namespace test_iterator_category
{
template <typename T>
void display_category(T itr) {
typename iterator_traits<T>::iterator_category cagy; // 使用 std::iterator_traits 获取迭代器类别
// 这里不需要递归调用 display_iterator 函数
cout << typeid(cagy).name() << endl;
}
void test() {
cout << "\ntest_iterator_category....................\n";
display_category(array<int, 10>::iterator());
display_category(vector<int>::iterator());
display_category(list<int>::iterator());
display_category(forward_list<int>::iterator());
display_category(deque<int>::iterator());
display_category(set<int>::iterator());
display_category(map<int, int>::iterator());
display_category(multiset<int>::iterator());
display_category(multiset<int, int>::iterator());
display_category(istream_iterator<int>());
display_category(ostream_iterator<int>(cout,""));
}
}此处可以参考一下display_category(array<int, 10>::iterator());中传递array<int, 10>::iterator()的方法。
测试结果:
test_iterator_category....................
struct std::random_access_iterator_tag
struct std::random_access_iterator_tag
struct std::bidirectional_iterator_tag
struct std::forward_iterator_tag
struct std::random_access_iterator_tag
struct std::bidirectional_iterator_tag
struct std::bidirectional_iterator_tag
struct std::bidirectional_iterator_tag
struct std::bidirectional_iterator_tag
struct std::input_iterator_tag
struct std::output_iterator_tag迭代器对算法的影响
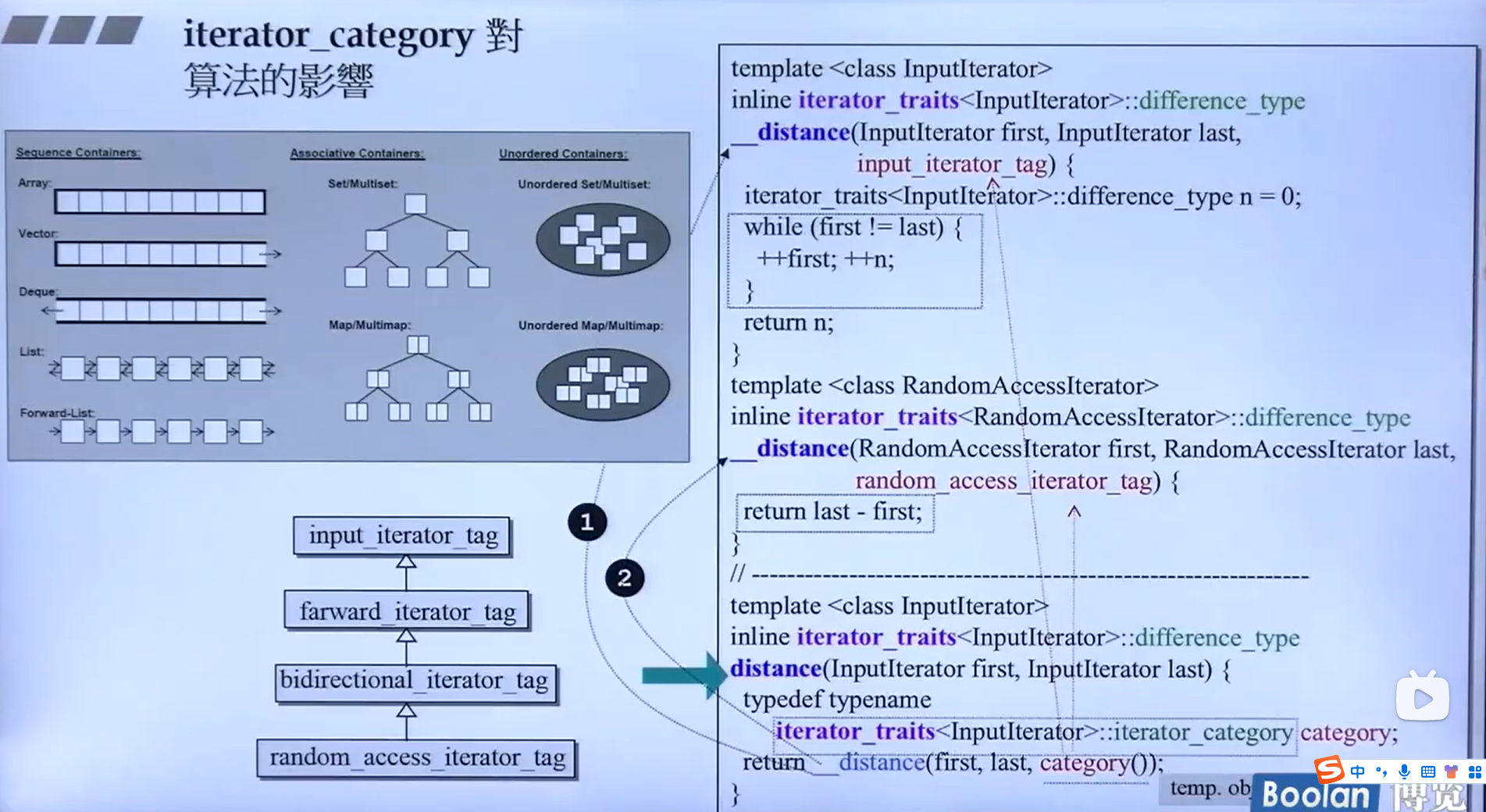
例子1-distance
迭代器如何计算容器元素之间的距离呢?当调用迭代器时,迭代器是如何操作以协助算法完成后续的增删改查的?
在计算距离方面,我们可以看到调用接口需要传入容器的头,以及容器尾部,接着使用:
...
typedef typename iterator_traits<InputIterator>::itrerator_category category;
return __distance(first,last, category);typedef typename iterator_traits<InputIterator>::itrerator_category category;这一句会判断迭代器的类型,进而执行加操作或一步一步加操作。详细如下图所示。
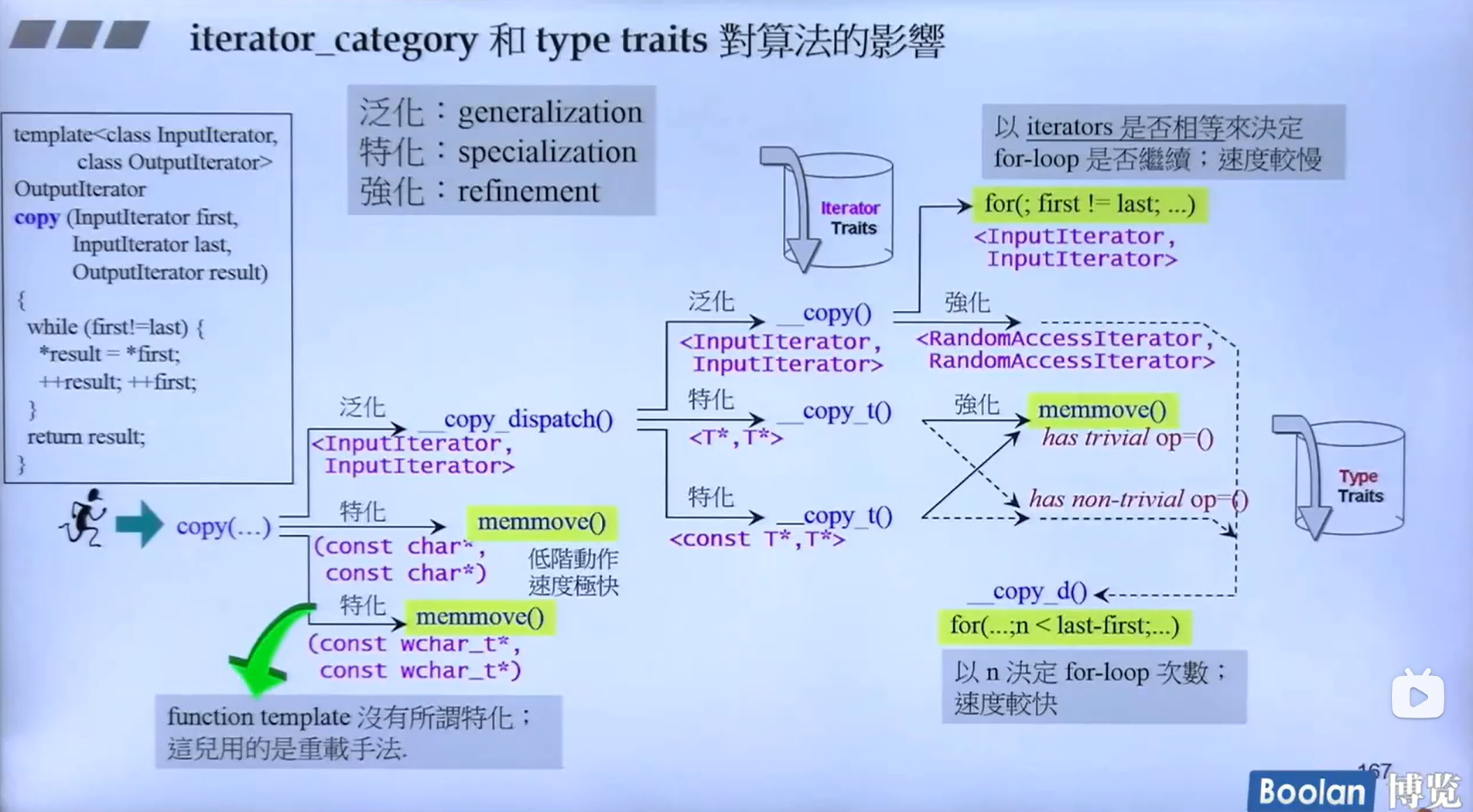
例子2-copy
copy的动作也不仅仅是对迭代器类型的判断,还做了许多特化、偏特化。如下图所示。
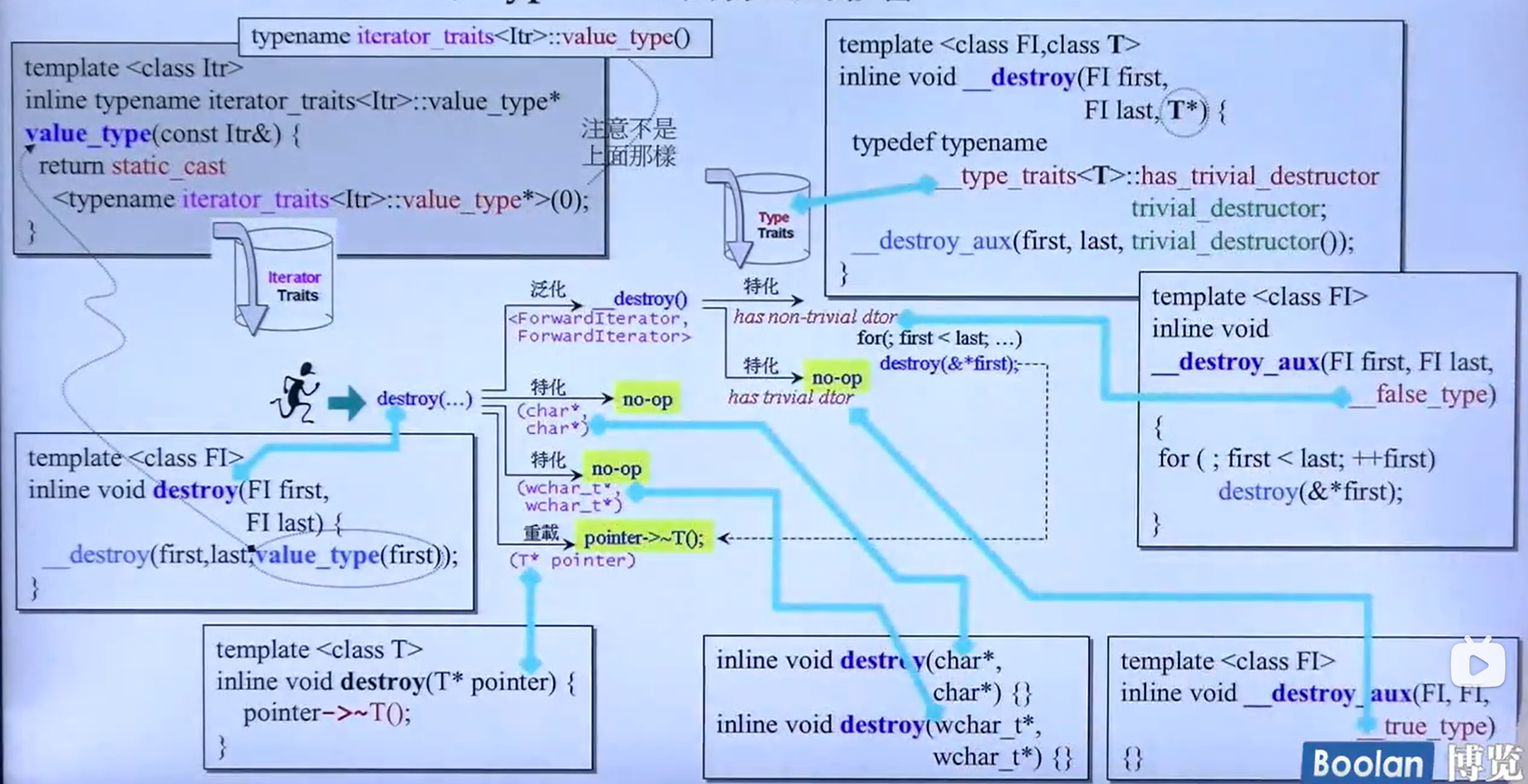
例子3-destroy
例子4-__unique_copy

对传入的迭代器类型的暗示
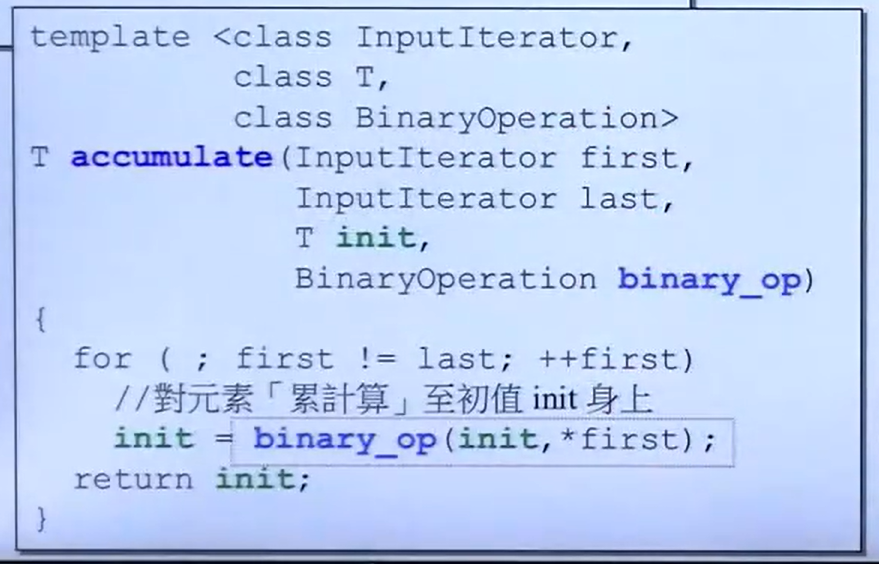
在调用一些需要传入迭代器的函数时,从函数的形参名可以判断传入的迭代器类型,如InputIterator,由于forward_iterator_tag、bidirection_iterator_tag、random_asccess_iterator_tag与input_iterator的继承关系可知,前三者都可以传入,以此类推如果形参是forward_iterator_tag那么除了其本身,bidirection_iterator_tag、random_asccess_iterator_tag也可传入。
算法源码剖析
accumulate-累计
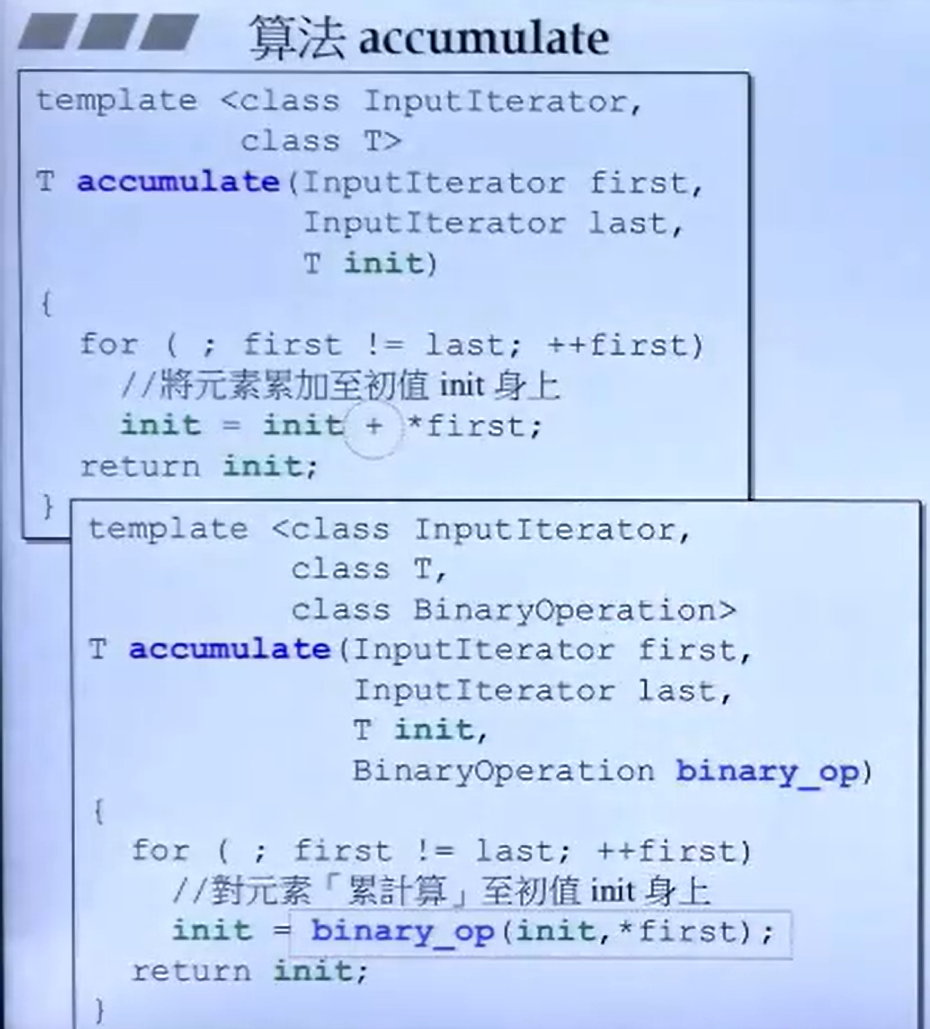
测试用例:
#include <functional>//std::minus
#include <numeric>//std::accumulate
namespace test_accumulate
{
int myfcn(int x, int y) { return x + 2 * y; }
struct myclass {
int operator()(int x, int y) { return x + 3 * y; }
} myobj;
}
void test(){
int init = 10;
int nums[] = {10,10,10};
cout << accumulate(nums, nums + 3, init)<<endl;//40
cout << accumulate(nums, nums + 3, init, test_accumulate::myfcn)<<endl;//70
cout << accumulate(nums, nums + 3, init, test_accumulate::myobj) << endl;//100
}for_each
拿到每一个元素时都对该元素执行某一操作。

测试用例:
namespace test_for_each
{
void myfcn(int i) { cout<<i<<"-"; }
struct myclass {
void operator()(int i) { cout << "[" << i<<"] "; }
} myobj;
void test() {
vector<int> c;
c.push_back(10);
c.push_back(20);
c.push_back(30);
for_each(c.begin(), c.end(), test_for_each::myfcn);//10-20-30-
cout << "\n";
for_each(c.begin(), c.end(), test_for_each::myobj);//[10] [20] [30]
}
}replace,replace_if,rreplace_copy
replace用于将新值替换为旧值,例如将数组中所有的8替换为9.详细源码如下图所示。

replace、replace_if 和 replace_copy 是 C++ 标准库中的算法,它们用于在容器或数组中替换元素。这些函数属于 <algorithm> 头文件。下面是每个函数的详细介绍和作用:
1. replace
replace 函数用于将容器中所有满足特定条件的元素替换为另一个值。这个函数直接在原容器上操作,不创建新的容器。
函数原型:
void replace(ForwardIterator first, ForwardIterator last, const T& old_value, const T& new_value);first,last:定义了要替换元素的范围。old_value:要被替换的值。new_value:替换后的值。
示例:
vector<int> v = {1, 2, 3, 4, 3, 2};
replace(v.begin(), v.end(), 2, 5);
// v 变为 {1, 5, 3, 4, 3, 5}
2. replace_if
replace_if 函数用于将容器中满足特定条件的元素替换为另一个值。与 replace 不同,replace_if 需要一个谓词(条件函数),只有满足这个条件的元素才会被替换。这个函数也直接在原容器上操作。
函数原型:
void replace_if(ForwardIterator first, ForwardIterator last, Predicate pred, const T& new_value);first,last:定义了要替换元素的范围。pred:一个谓词函数,返回true表示替换,false表示不替换。new_value:替换后的值。
示例:
vector<int> v = {1, 2, 3, 4, 3, 2};
replace_if(v.begin(), v.end(), [](int i) { return i == 2; }, 5);
// v 变为 {1, 5, 3, 4, 3, 5}
3. replace_copy
replace_copy 函数用于将容器中所有满足特定条件的元素复制到另一个容器中,并替换为另一个值。这个函数不会改变原容器,而是创建一个新的容器,其中包含替换后的元素。
函数原型:
template <class InputIterator, class OutputIterator>
OutputIterator replace_copy(InputIterator first, InputIterator last, OutputIterator result, const T& old_value, const T& new_value);first,last:定义了要替换元素的范围。result:指向目标容器的迭代器,用于存储替换后的元素。old_value:要被替换的值。new_value:替换后的值。
示例:
vector<int> v = {1, 2, 3, 4, 3, 2};
vector<int> v2(v.size());
replace_copy(v.begin(), v.end(), v2.begin(), 2, 5);
// v 保持不变,v2 变为 {1, 5, 3, 4, 3, 5}
count,count_if
源代码如下:

小结:

find,find_if

sort

binary_search
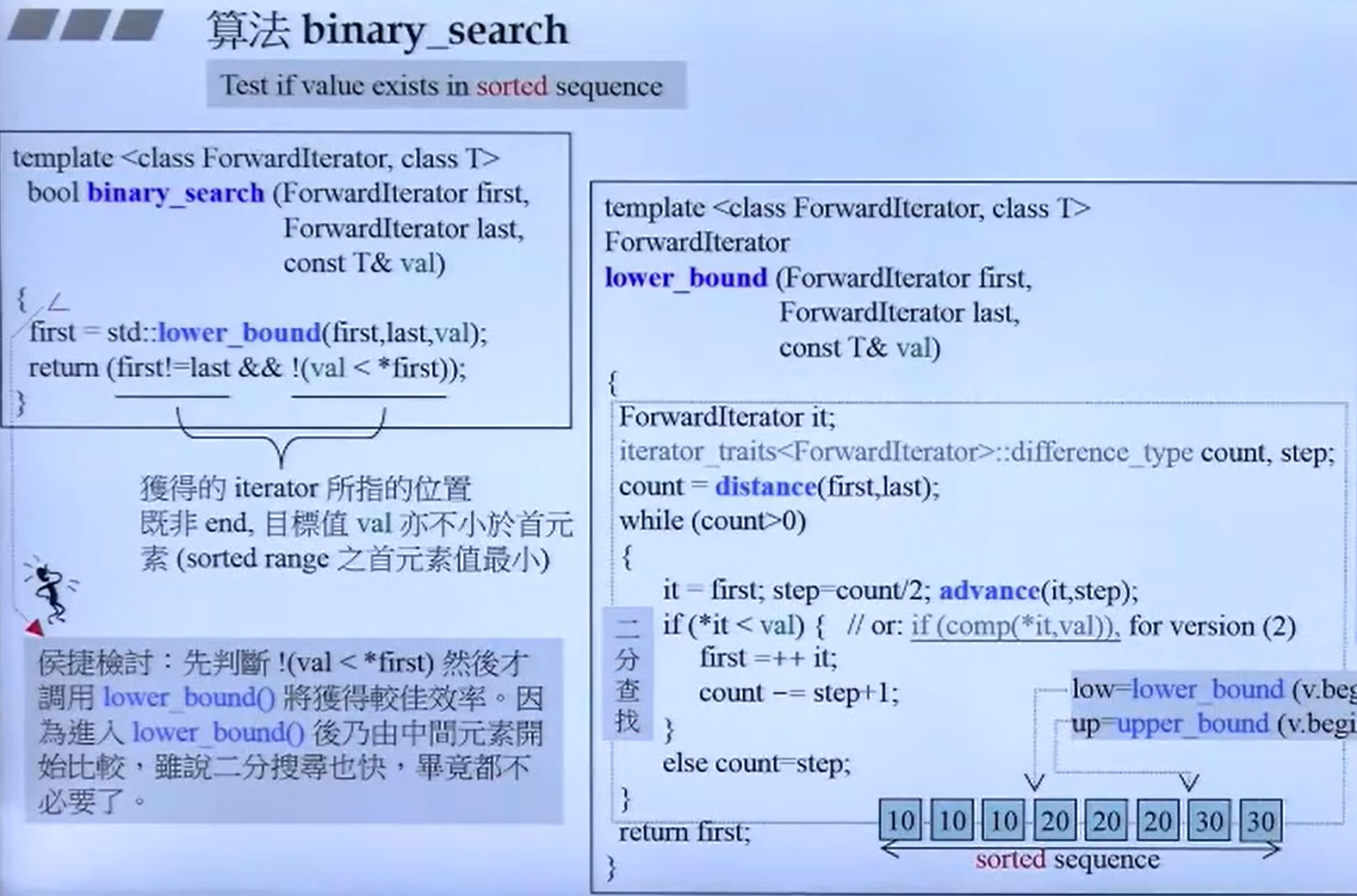
算法原理:
二分查找的基本思想是将一个有序序列分为两半,通过比较中间元素和目标值来缩小搜索范围。如果中间元素正好是目标值,则查找成功;如果目标值小于中间元素,则在序列的左半部分继续查找;如果目标值大于中间元素,则在右半部分继续查找。这个过程不断重复,直到找到目标值或搜索范围为空。
函数原型:
binary_search 的函数原型如下:
template <class ForwardIterator, class T>
bool binary_search(ForwardIterator first,
ForwardIterator last,
const T& value);first,last:定义了要搜索的范围,first是序列的开始迭代器,last是序列的结束迭代器(指向序列末尾的下一个位置)。value:要查找的值。
返回值:
- 如果在序列中找到
value,则返回true。 - 如果没有找到,则返回
false。
示例代码:
#include <algorithm>
#include <vector>
#include <iostream>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5, 6, 7, 8, 9};
int target = 5;
bool found = std::binary_search(data.begin(), data.end(), target);
if (found) {
std::cout << "Element found in the array." << std::endl;
} else {
std::cout << "Element not found in the array." << std::endl;
}
return 0;
}注意事项:
- 有序序列:
binary_search要求序列必须是有序的,否则查找结果将不可预测。 - 效率:二分查找的时间复杂度为 O(log n),其中 n 是序列中的元素数量。这使得它比线性查找(O(n))更高效,尤其是在大数据集上。
- 稳定性:如果存在多个相同的目标值,
binary_search将返回第一个匹配的位置。如果需要找到所有匹配项,可能需要使用其他方法。
8.STL库学习之容器
list
vector
deque
deque的迭代器
deque实现中间插入值的做法:如果欲插入值在最前端(最尾端)调用push_front()(push_back()),否则借助insert_aux()迭代器,实现如果欲插入位置靠近前端使用,就让前端的数据往前挪,否则往后挪。
deque中+=的实现:1.先计算+=后是否超过缓冲区,如果没有则直接+=,否则需要判断需要跨几个缓冲区,然后再去确定前进几个缓冲区。

Vector的内存扩充:
std::vector 在需要更多空间时,通常会将容量增加到当前大小的两倍(这是最常见的增长策略,但不是唯一的,具体实现可能有所不同)。
当发生扩充时,std::vector 会分配一个新的更大的内存块,然后将所有元素从旧内存块复制到新内存块,最后释放旧内存块。
Deque的内存扩充:
std::deque(双端队列)的内存管理机制与 std::vector 不同。std::deque 是一个使用多个固定大小的内存块来存储元素的容器,这些内存块被称为“chunks”或“maps”。
当 std::deque 需要更多空间时,它可能会在已有的内存块之后添加新的内存块,或者在前面添加,这取决于哪个方向上的空间更紧张。 std::deque 不会像 std::vector 那样将所有元素复制到一个新的连续内存块中,而是在多个内存块之间分配元素。
stack和queue
stack和queue默认使用deque的功能来分别实现先进后出和先进先出的功能,除此之外还可以使用list,stack还可以使用vector,但是deque就不能用vector,以我的理解,是因为vector不提供后端操作。
Rb-tree
在C++中,set和map的底层实现都是基于红黑树(RB-tree)。红黑树是一种自平衡的二叉搜索树,能够保证在最坏情况下,插入、删除和查找操作的时间复杂度均为O(log n)。
template < int key,
int value,
identity<int>,
less<int>,
alloc
>
class rb_tree;set 和 map 的区别:
set:set中的元素是唯一的键值,即Key和Value是同一个。插入时使用insert_unique()方法,确保键值不重复。
map:map中的元素是键值对(Key-Value),键值用于索引,值表示与索引相关联的数据。插入时使用insert_equal()方法,允许键值重复。
红黑树的结构:
红黑树的结构包括节点、根节点、最左节点和最右节点等。根节点通过header.parent保存,最左节点通过header.left保存,最右节点通过header.right保存。
- 插入操作
- set:插入操作调用insert_unique(),确保键值唯一。
- map:插入操作调用insert_equal(),允许键值重复。
- 迭代器
- set:迭代器是RB-tree的const_iterator,不允许修改元素值。
- map:迭代器也是RB-tree的const_iterator,但允许修改元素的值(因为值部分不是键)。
set和multiset
set与map的底层实现基本可以参考下面的源码图,

需要说明的一点是,在不允许更改键值上,二者的设计还是有区别,主要体现在set使用const_iterator,这样迭代器指向的键值就无法更改,而map在设计上在传进来的Key设置为const,确保键值不会被更改。
hashtable-哈希表
在C++中,hash_set、hash_map、hash_multiset和hash_multimap等数据结构的底层实现确实采用了哈希表的思想。具体来说,这些数据结构的设计核心是通过哈希函数将键(key)映射到数组的索引位置,从而实现高效的插入、删除和查找操作。
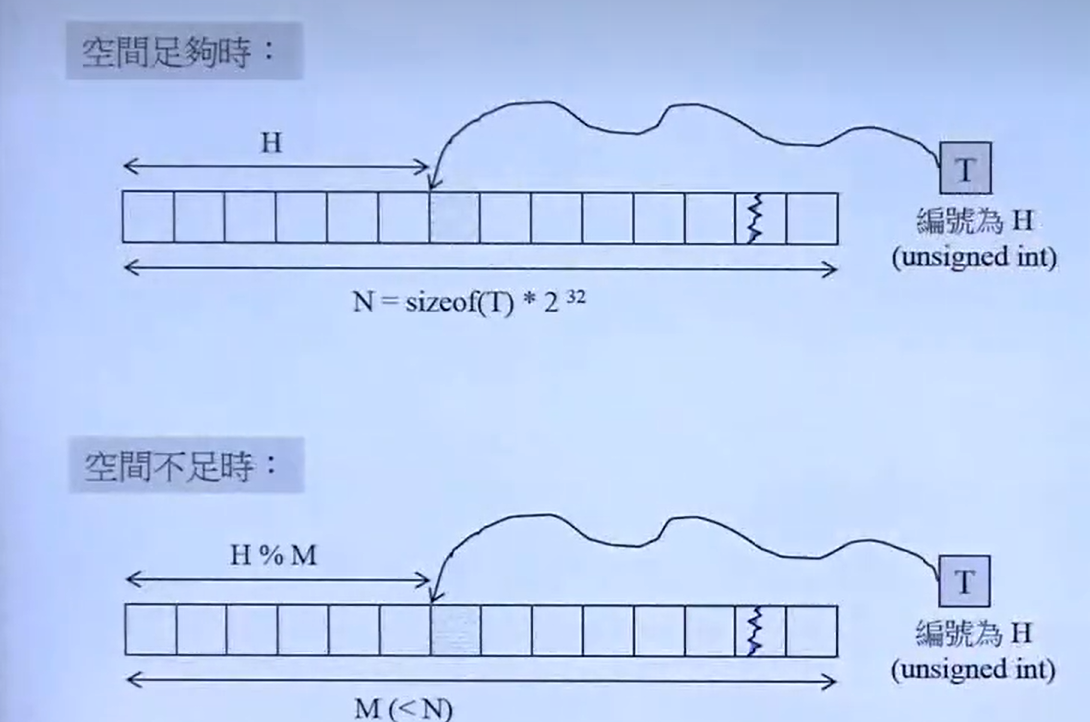
数据存储的设计思想
每个键值通过一个哈希函数计算出一个哈希值。这个哈希值通常是一个整数,用于确定键值在数组中的存储位置。例如,对于一个整数键值12,哈希函数可能会直接返回12,这样12就会被存储在数组的第12个位置。
哈希表的核心是一个数组(通常是一个vector),数组的每个元素(即每个位置)可以存储一个指针。这个指针指向一个单向链表的头节点。如果多个键值通过哈希函数计算出相同的哈希值,它们会被存储在同一个位置的链表中。参考下图:
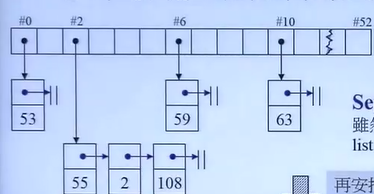
 当多个键值映射到同一个哈希值时,这些键值会被存储在一个链表中。链表的每个节点包含一个键值和指向下一个节点的指针。这种设计允许在发生哈希冲突时,通过遍历链表来查找或插入特定的键值。
当多个键值映射到同一个哈希值时,这些键值会被存储在一个链表中。链表的每个节点包含一个键值和指向下一个节点的指针。这种设计允许在发生哈希冲突时,通过遍历链表来查找或插入特定的键值。
 为了保持高效的性能,哈希表通常会有一个动态扩容机制。当哈希表中的元素数量超过一定阈值时,哈希表会自动重新分配更大的数组,并重新计算所有键值的哈希值,以减少链表的长度,从而提高查找效率。
为了保持高效的性能,哈希表通常会有一个动态扩容机制。当哈希表中的元素数量超过一定阈值时,哈希表会自动重新分配更大的数组,并重新计算所有键值的哈希值,以减少链表的长度,从而提高查找效率。
在实际应用中,哈希函数可能会导致不同的键值计算出相同的哈希值,这种现象称为哈希冲突。常见的解决策略包括链地址法(即使用链表存储冲突的元素)和开放地址法(即在数组中寻找下一个空闲位置)。
具体实现过程
- 当插入一个新键值时,首先通过哈希函数计算出其哈希值,然后根据哈希值找到对应的数组位置。如果该位置已经有元素(即发生冲突),则将新元素插入到该位置的链表中。
- 查找操作同样通过哈希函数计算出键值的哈希值,然后根据哈希值找到对应的数组位置。如果该位置有元素,则遍历链表,直到找到匹配的键值或链表结束。
- 删除操作首先通过哈希函数计算出键值的哈希值,然后根据哈希值找到对应的数组位置。如果该位置有元素,则遍历链表,找到并删除匹配的键值。
实现代码
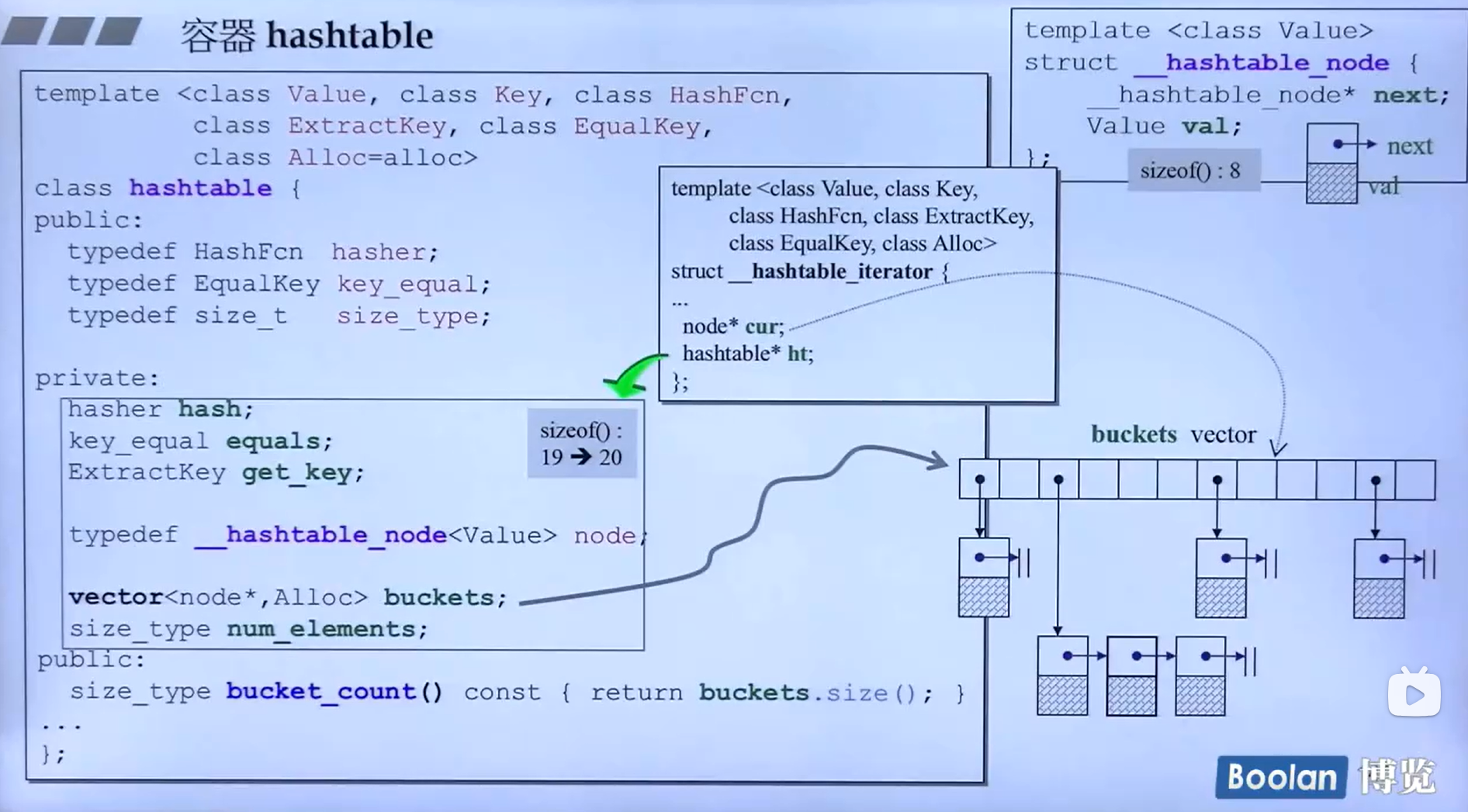
hashtable类的实现提供了六个模板参数。
template <class value,
class key,
class hashFcn,//计算编号
class extractKey,//取出键值
class EqualKey,//判断类型是否相等
class Alloc=alloc
>
如果要自己使用这个哈希表,需要写hashFcn()的重载,对齐进行偏特化等操作,如下图:

如果传入的是字符串,那么字符串的编号计算可以参考下图计算方法:

7.STL库学习之分配器
分配器源代码位置:xmemory.h
除了array和vector外,其他容器的适配器必须是一个类,
6.STL库学习之筑基概要
STL程序源代码位置
了解自身编译器STL程序源代码位置。
OOP 与 GP
面向对象编程(OOP):
面向对象编程是一种编程范式,它将数据和处理这些数据的方法封装在对象中。这种方法强调了数据和函数的捆绑,使得代码更加模块化,易于理解和维护。对象可以包含属性(数据)和方法(函数),它们一起工作来模拟现实世界的行为。
补充说明:OOP 通过类(Class)来定义对象的蓝图,支持继承、封装和多态等特性,从而提高代码的重用性和灵活性。例如list中有自己的sort()函数,专门为list而设计,比::sort()的算法更优。
泛型编程(GP):
泛型编程是一种编程范式,它允许开发者定义操作类型数据结构的函数和类,而不需要在编译时指定具体的数据类型。这种方法强调了数据和处理方法的分离,提供了更高的代码复用性和类型安全性。
补充说明:GP 通过模板(Templates)或泛型容器(如 std::vector、std::map)来实现,允许开发者写出与数据类型无关的代码,从而在不同的数据类型间共享相同的算法逻辑。例如vector和deque没有为自身设计sort(),在做排序操作时,需要调用::sort()来实现。
操作符重载
STL源码程序中会包含很多的操作符重载,一般你会看到operate修饰符,后面就紧跟着操作符。注意:::、.、.*和 :?不能进行操作符重载。
在我看来操作符重载是一个重要的特性,它可以让你实现任何类的运算法则,这些法则有你自己规定,操作空间还是比较宽泛。
模版-template
最常见的写法如下:
template <typename T>
class FOO{
...
}类模板
最常见的写法如下:
template <class T>
class FOO{
...
}成员模版
泛化、特化和偏特化
以我个人的理解,泛化是为了应对大部分的情况,特化是为了应对特殊的情况,或使用单独的方法处理对某些情况而言更好,偏特化比偏特化更近一步,把处理的手段限定在一定范围内,举个简单的例子,假设为设计计算两种情况的相加做如下定义:
1.泛化
泛化编程在C++中通过模板实现。以下是一个泛化编程的示例,其中 AND 类是一个模板类,可以处理任何类型的数据。
template <class T,class U>
class AND{
...
}2.特化
特化是对模板类或函数的特定实例化。以下是特化的示例,其中 AND 类被特化为处理 string 和 Text 类型:
template <class T, class U>
class AND {
// ... 类的泛型实现
};
template <>
class AND<string, Text> {
// ... 类的特化实现
};3.偏特化
偏特化允许对模板类的部分参数进行特化。以下是偏特化的示例,其中 AND 类被偏特化为处理第一个类型为 int 的情况:
template <class T, class U>
class AND {
// ... 类的泛型实现
};
template <class U>
class AND<int, U> {
// ... 类的偏特化实现
};5.STL库之观其大略
一下主要讲STL组件的测试用例,特别是容器的测试
学习资料
- CPLusPlus.com
- CppReference.com
- gcc.gnu.org
- 《STL源码剖析》
STL六大组件
- 容器-Containers,申请内存用于存储数据
- 分配器-Allocators,配合容器分配内存
- 算法- Algorithms,处理某一数据的最优办法
- 迭代器- Iterators,指针的泛型,本质与指针类似
- 适配器- Adapters,
- 仿函数-Functors,类似函数。
六者的关系
begin()和end()
以迭代器为例,begin()指向迭代器的首地址,而end()指向迭代器尾地址的下一位,可以用前闭后开区间来表示,即**[ )**
容器的分类
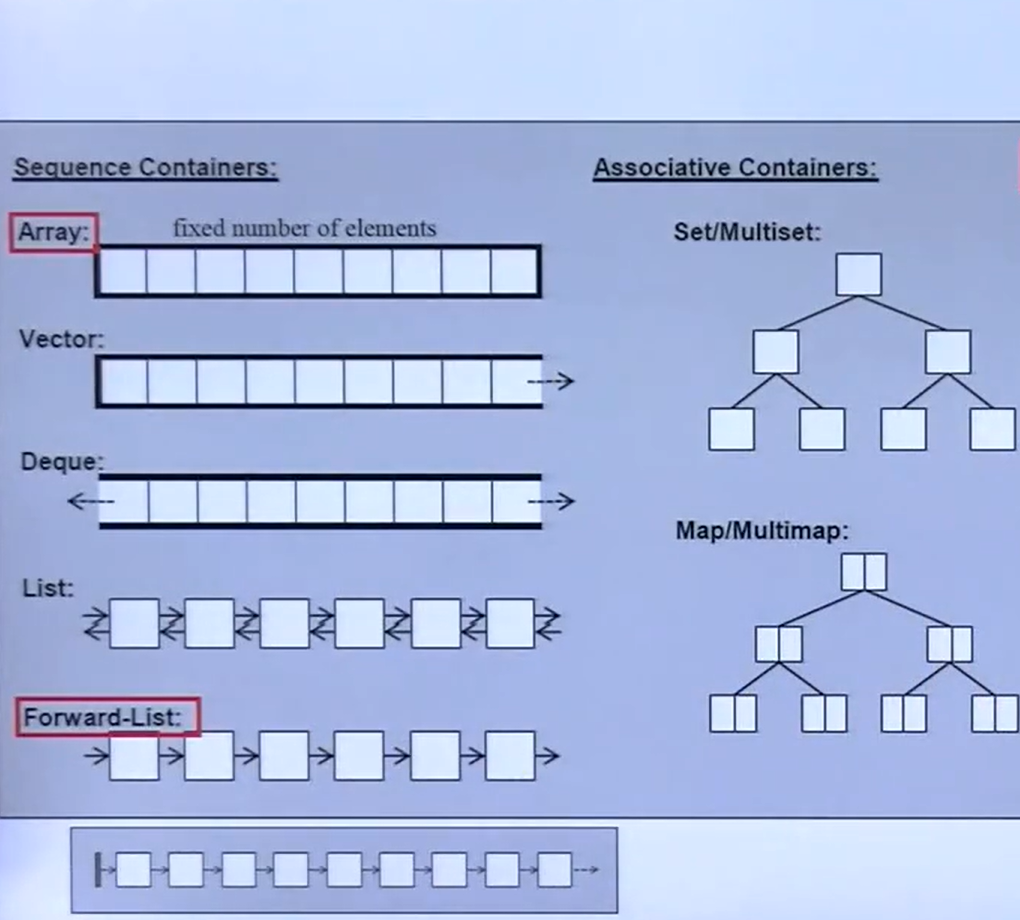

数组容器的使用
array 的使用
示例1
#ifndef __AUXFUN__
#define __AUXFUN__
#include <iostream>
#include <string>
#define RAMD_MAX 32767
using namespace std;
long get_a_target_long()
{
long target = 0;
cout << "target (0--" << RAMD_MAX << "):";
cin >> target;
return target;
}
//将数值转为string,这样可以测试类似object的情况
string get_a_target_string()
{
long target = 0;
char buf[10];
cout << "target (0--" << RAMD_MAX << "):";
cin >> target;
snprintf(buf, 10, "%d", target);
return string(buf);
}
int compareLongs(const void* a, const void* b)
{
return (*(long*)a - *(long*)b);
/*
1.类型转换:因为参数是const void* 类型,你需要将它们转换为具体的数据类型指针(在这个例子中是long* ),以便可以解引用并获取它们的值。
2.解引用:在转换之后,通过在类型转换的结果前使用* 操作符来获取指针指向的实际值。
3.强制转换的结果:* (long*)a实际上是一个long值,它是通过解引用转换后的指针得到的。*/
}
int compareString(const void* a, const void* b)
{
if (*(long*)a > *(long*)b)
return 1;
else if (*(long*)a < *(long*)b)
return -1;
else
return 0;
}
#endif // !__ENTRY__
#include "TestHeardFiles/AuxFun.h"
#include <ctime>
#include <cstdlib>//qsort()、 bsearch()、 NULL
#include <array>
const size_t ASIZE = 50000;
namespace t01
{
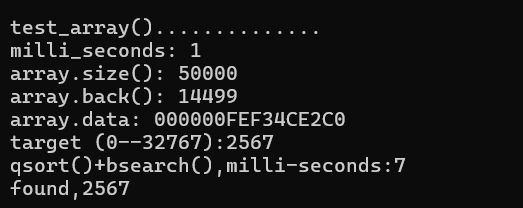
void test_array()
{
cout << "\ntest_array().............. \n";
array<long, ASIZE> c;//使用数组容器
clock_t timeStart = clock();
for (long i = 0; i < ASIZE; ++i)
{
c[i] = rand();//可以产生随机数的函数
}
cout << "milli_seconds: " << (clock() - timeStart) << endl;
cout << "array.size(): " << c.size() << endl;//返回数组大小
cout << "array.back(): " << c.back() << endl;//返回数组最后一个数
cout << "array.data: " << c.data() << endl;//返回第一个数的地址
long target = get_a_target_long();
timeStart = clock();//clock()返回毫秒数
qsort(c.data(), ASIZE, sizeof(long), compareLongs);//数组排序
long* pItem = (long*)bsearch(&target, (c.data()), ASIZE, sizeof(long), compareLongs);//数组查找
cout << "qsort()+bsearch(),milli-seconds:" << clock() - timeStart << endl;
if (pItem != NULL)
{
cout << "found," << *pItem << endl;
}
else
cout << "Not found!" << endl;
}
}
int main() {
t01::test_array();
}
vector 的使用
vector是一种向后自动以2次方增加的内存的容器,一般使用push_back向后添加数据;
vector也有一定的缺点,假设我只需要5个内存空间,但是vector分配的是8个,剩下的3个后面如果不使用就会浪费。
示例2
#include <vector>
#include <stdexcept> //obort()
#include <cstdio> //snprintf()
#include <algorithm>//sort()
namespace t02
{
void test_vector(long& value) {
cout << "\ntest_vector()..............\n";
vector<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.push_back(string(buf));//将随机数转为string类型,并使用push_back()将数据存入容器尾部,这是vector的特性
//同时值得注意,当空间不足时,内存会自动增加,怎么加方式是2的平方
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "vector.size(): " << c.size() << endl;
cout << "vector.front(): " << c.front() << endl;
cout << "vector.back(): " << c.back() << endl;
cout << "vector.data(): " << c.data() << endl;
cout << "vector.capacity(): " << c.capacity() << endl;//返回的是向量当前分配的存储空间可以容纳的元素个数
string target = get_a_target_string();//获取输入的数字,并转为string类型返回
//使用算法find查找
{
timeStart = clock();
auto pItem = ::find(c.begin(), c.end(), target);//返回类型是:使用全局::find()寻找目标,这是循环寻找
cout << "::find(),milli-seconds: " << (clock() - timeStart) << endl;
//判断有没有找到
if (pItem != c.end()) {
cout << "found," << *pItem << endl;
}
else
{
cout << "Not fount!" << endl;
}
}
//进行排序后使用bsearch查找。
{
timeStart = clock();
sort(c.begin(), c.end());//该算法将任何类型进行排序,需要提供相应的比较函数
string* pItem = (string*)bsearch(&target, (c.data()), c.size(), sizeof(string), compareString);
cout << "sort()+bsearch(),milli-seconds: " << (clock() - timeStart) << endl;
if (pItem != NULL) {
cout << "found," << *pItem << endl;
}
else
{
cout << "Not fount!" << endl;
}
}
}
}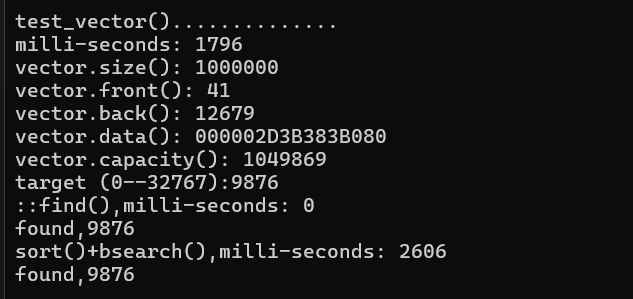
从上面的结果来看,排序后使用二分查找反而比循环查找慢,原因在于排序话费了很多时间,因为string类型是一个object,其本身大小比较大,所以面对一个object进行查找时不建议使用排序后二分查找。
在实际应用中,选择排序加二分查找还是直接线性查找,需要根据具体情况来决定:
- 如果容器已经排序,或者数据量不大,直接使用二分查找可能更简单、更快。
- 如果容器未排序,且数据量很大,那么可能需要考虑是否值得为了一次查找而进行排序,或者是否可以通过其他方式(如使用更高效的数据结构,如哈希表)来提高查找效率。
- 如果查找操作非常频繁,而插入和删除操作不频繁,那么维护一个已排序的容器可能是合理的,这样每次查找都可以利用二分查找的效率。
总之,选择哪种方法取决于具体的应用场景和性能要求。在某些情况下,可能需要通过实验或性能分析来确定最佳的策略。
链表容器-list
std::list 是 C++ 标准库中的一个容器,它提供了双向链表的实现。
std::list 容器的特点:
- 双向链表结构:std::list 由一系列节点组成,每个节点包含一个元素和两个指针,分别指向前一个节点和后一个节点。
- 动态内存分配:std::list 中的每个节点都是独立分配内存的。这意味着当你添加或删除元素时,std::list 会为新元素分配内存,或释放不再使用的元素所占用的内存。
- 内存空间利用:由于 std::list 的元素是单独分配的,因此不存在像 std::vector 那样的连续内存块,也就不会有额外的内存浪费。每个元素恰好占用它所需的空间,加上一些指针存储开销。
查询操作效率:
- 查询效率较低:与 std::vector 或 std::array 这样的随机访问容器相比,std::list 的查询操作通常较慢。这是因为 std::list 没有提供快速的随机访问能力。
- 顺序访问:在 std::list 中,要访问一个特定位置的元素,你需要从头开始遍历,直到到达那个位置。这意味着访问时间与列表的大小成正比,最坏情况下的时间复杂度为 O(n)。
- 没有跳跃访问:与数组或 std::vector 不同,std::list 没有提供直接跳到任意位置的能力。在数组中,你可以通过简单的指针算术来访问任意位置的元素,而在 std::list 中,你必须遍历链表。
测试代码:
示例3
#include <list>
namespace t03
{
void test_list(long& value)
{
cout << "\ntest_list()..............\n";
list<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.push_back(string(buf));//将随机数转为string类型,并使用push_back()将数据存入容器尾部,这是vector的特性
//同时值得注意,当空间不足时,内存会自动增加,怎么加方式是2的平方
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "list.size(): " << c.size() << endl;
cout << "list.max_size(): " << c.max_size() << endl;
cout << "list.front(): " << c.front() << endl;
cout << "list.back(): " << c.back() << endl;
string target = get_a_target_string();//获取输入的数字,并转为string类型返回
//使用算法find查找
{
timeStart = clock();
auto pItem = ::find(c.begin(), c.end(), target);//返回类型是:使用全局::find()寻找目标,这是循环寻找
cout << "::find(),milli-seconds: " << (clock() - timeStart) << endl;
//判断有没有找到
if (pItem != c.end()) {
cout << "found," << *pItem << endl;
}
else
{
cout << "Not fount!" << endl;
}
}
//测试排序花费的时间
{
timeStart = clock();
c.sort();//使用list自带的排序函数,当然也可以用全局的sort,一般如果容器自带,则选择自带的。
cout << "list.sort(),milli-seconds: " << (clock() - timeStart) << endl;
}
}
} How much memory space you need: 1000000
test_list()..............
milli-seconds: 1073
list.size(): 1000000
list.max_size(): 329406144173384850
list.front(): 41
list.back(): 12679
target (0--32767):12345
::find(),milli-seconds: 4
found,12345
list.sort(),milli-seconds: 1611总结: std::list 的优点在于它的灵活性和高效的插入/删除操作,这些操作可以在 O(1) 时间内完成,因为它们只需要修改几个指针。然而,这种灵活性的代价是牺牲了快速随机访问的能力。因此,如果你的应用场景中需要频繁地在序列中间插入或删除元素,而不太关心随机访问性能,std::list 是一个很好的选择。反之,如果随机访问是一个关键操作,那么可能需要考虑使用其他类型的容器。
链表容器-forward_list
std::forward_list 是 C++ 标准库中的一个容器,它提供了单向链表的实现。
std::forward_list 容器的特点:
- 单向链表结构:std::forward_list 由一系列节点组成,每个节点包含一个元素和一个指向下一个节点的指针。
- 内存分配:与 std::list 类似,std::forward_list 的元素也是动态分配内存的。但是,由于它是单向链表,所以只能从链表的前端(头部)开始进行内存分配。
- 操作限制:由于 std::forward_list 的单向特性,它只提供了 push_front() 和 pop_front() 操作来在链表的前端添加或删除元素。不支持快速的随机访问,也不支持在链表的中间或末尾进行插入和删除操作。
内存使用效率:
- 无尾插法:std::forward_list 没有 push_back() 方法,只能使用 push_front() 在链表的头部插入元素。这意味着,如果你需要在链表的末尾添加元素,你将不得不遍历整个链表以到达末尾,这在大型数据集中可能效率较低。
- 节省空间:与 std::list 相比,std::forward_list 每个节点只需要存储一个指向下一个节点的指针,因此它的内存开销比 std::list 小。
适用场景:
- 空间敏感的应用:如果你的应用对内存使用非常敏感,且需要从链表的前端进行频繁的插入和删除操作,std::forward_list 是一个不错的选择。
- 单向遍历:如果你的应用只需要从链表的前端开始遍历元素,那么 std::forward_list 可以提供良好的性能。
测试代码
示例3
#include <forward_list>
namespace t04
{
void test_forward_list(long& value)
{
cout << "\nforward_list()..............\n";
forward_list<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.push_front(string(buf));//将随机数转为string类型,并使用push_frond()将数据存入容器头部,forward_list没有push_back()
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "forward_list.max_size(): " << c.max_size() << endl;
cout << "forward_list.front(): " << c.front() << endl;
//cout << "forward_list.back(): " << c.back() << endl; 没有该函数
//cout << "forward_list.size(): " << c.size() << endl; 没有该函数
string target = get_a_target_string();//获取输入的数字,并转为string类型返回
//使用算法find查找
{
timeStart = clock();
auto pItem = ::find(c.begin(), c.end(), target);//返回类型是:使用全局::find()寻找目标,这是循环寻找
cout << "::find(),milli-seconds: " << (clock() - timeStart) << endl;
//判断有没有找到
if (pItem != c.end()) {
cout << "found," << *pItem << endl;
}
else
{
cout << "Not fount!" << endl;
}
}
//测试排序花费的时间
{
timeStart = clock();
c.sort();//使用forward_list自带的排序函数,当然也可以用全局的sort,一般如果容器自带,则选择自带的。
cout << "forward_list.sort(),milli-seconds: " << (clock() - timeStart) << endl;
}
}
} How much memory space you need: 1000000
forward_list()..............
milli-seconds: 965
forward_list.max_size(): 384307168202282325
forward_list.front(): 12679
target (0--32767):12345
::find(),milli-seconds: 3
found,12345
forward_list.sort(),milli-seconds: 1595值得注意的是: std::forward_list 专为高效的前端插入和删除操作设计,std::forward_list 没有 push_back() 是因为它是单向链表, 只能高效地从前面操作。它没有 size() 函数,因为计算链表长度需要遍历整个链表,这与它优化前端操作的设计目标不符。
总结:
std::forward_list 是一个轻量级的容器,它在内存使用上比 std::list 更为高效,但在功能上也更为有限。它适合于那些只需要单向遍历和操作的场景。由于其单向链表的特性,std::forward_list 在进行元素插入和删除时,只能从链表的前端进行,这限制了它的使用场景。在选择 std::forward_list 时,需要根据应用的具体需求来权衡其优势和局限性。
链表容器-slist
slist容器与forward_list容器一样,只是slis容器存在于ext\slist头文件中。
测试代码:
示例3
#include <forward_list>
namespace t04
{
void test_forward_list(long& value)
{
cout << "\nforward_list()..............\n";
forward_list<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.push_front(string(buf));//将随机数转为string类型,并使用push_frond()将数据存入容器头部,forward_list没有push_back()
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "forward_list.max_size(): " << c.max_size() << endl;
cout << "forward_list.front(): " << c.front() << endl;
//cout << "forward_list.back(): " << c.back() << endl; 没有该函数
//cout << "forward_list.size(): " << c.size() << endl; 没有该函数
string target = get_a_target_string();//获取输入的数字,并转为string类型返回
//使用算法find查找
{
timeStart = clock();
auto pItem = ::find(c.begin(), c.end(), target);//返回类型是:使用全局::find()寻找目标,这是循环寻找
cout << "::find(),milli-seconds: " << (clock() - timeStart) << endl;
//判断有没有找到
if (pItem != c.end()) {
cout << "found," << *pItem << endl;
}
else
{
cout << "Not fount!" << endl;
}
}
//测试排序花费的时间
{
timeStart = clock();
c.sort();//使用forward_list自带的排序函数,当然也可以用全局的sort,一般如果容器自带,则选择自带的。
cout << "forward_list.sort(),milli-seconds: " << (clock() - timeStart) << endl;
}
}
} How much memory space you need: 1000000
forward_list()..............
milli-seconds: 965
forward_list.max_size(): 384307168202282325
forward_list.front(): 12679
target (0--32767):12345
::find(),milli-seconds: 3
found,12345
forward_list.sort(),milli-seconds: 1595双向容器-deque

std::deque(双端队列)是一种容器,它允许在序列的前端和后端快速插入和删除元素。尽管从概念图上看, std::deque 似乎是一个连续的存储空间,但实际上它并不是连续的。std::deque 的实现通常是由一个或多个固定大小的连续内存块 (通常称为“节点”或“块”)组成的,这些块通过指针连接在一起。
以下是对您提供内容的整理:
- 存储机制:std::deque 由多个指针组成,每个指针指向一个具有一定容量的连续内存块。这些内存块被组织在一起,形成一个能够从两端快速增长的容器。
- 内存管理:当 std::deque 中的一个内存块满了,需要更多的空间时,它会“自动跳转”到下一个空闲的内存块的开始位置。如果所有现有的内存块都已满,std::deque 会分配一个新的内存块,并更新指针以指向这个新的块。
- 内存效率:使用固定容量的内存块可以减少内存浪费。例如,如果每个内存块的大小为8个元素,那么即使只存储一个元素,也只会浪费7个元素的空间(因为第一个块始终被使用)。这与 std::vector 相比,后者可能会因为频繁的内存重新分配而导致更多的内存浪费。
- 动态增长:当 std::deque 需要更多内存时,它会动态地增加新的内存块。这种设计使得 std::deque 能够在不牺牲太多内存的情况下,提供快速的插入和删除操作。
- 连续性:尽管 std::deque 在内部不是完全连续的,但它提供了随机访问的能力,这意味着你可以像访问 std::vector 或数组一样,通过索引来访问 std::deque 中的任何元素。
总的来说,std::deque 是一个灵活且高效的容器,适用于需要在序列的两端进行频繁插入和删除操作的场景。它的设计既考虑了性能, 也考虑了内存使用效率。
测试代码:
示例3
#include <deque>
namespace t05
{
void test_deque(long& value)
{
cout << "\ntest_deque()..............\n";
deque<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.push_back(string(buf));//将随机数转为string类型,并使用push_back()将数据存入容器尾部
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "deque.max_size(): " << c.max_size() << endl;
cout << "deque.front(): " << c.front() << endl;
cout << "deque.back(): " << c.back() << endl;
cout << "deque.size(): " << c.size() << endl;
string target = get_a_target_string();//获取输入的数字,并转为string类型返回
//使用算法find查找
{
timeStart = clock();
auto pItem = ::find(c.begin(), c.end(), target);//返回类型是:使用全局::find()寻找目标,这是循环寻找
cout << "::find(),milli-seconds: " << (clock() - timeStart) << endl;
//判断有没有找到
if (pItem != c.end()) {
cout << "found," << *pItem << endl;
}
else
{
cout << "Not fount!" << endl;
}
}
//测试排序花费的时间
{
timeStart = clock();
sort(c.begin(), c.end());//使用全局的sort,deque没有自己的sort。
cout << "deque.sort(),milli-seconds: " << (clock() - timeStart) << endl;
}
}
} How much memory space you need: 1000000
test_deque()..............
milli-seconds: 1055
deque.max_size(): 461168601842738790
deque.front(): 41
deque.back(): 12679
deque.size(): 1000000
target (0--32767):12345
::find(),milli-seconds: 4
found,12345
deque.sort(),milli-seconds: 3838特殊容器-stack和queue
std::stack(栈)
定义:
std::stack 是一个遵循后进先出(LIFO,Last In First Out)原则的容器适配器。它只能在序列的一端(栈顶)进行添加(push)和移除(pop)操作。
主要操作:
- push():在栈顶添加一个元素。
- pop():移除栈顶元素。
- top():返回栈顶元素的引用,不移除它。
特点:
- 只能单端操作,即只能在栈顶进行操作。
- 没有提供直接的迭代器支持,但提供了 top() 方法来访问栈顶元素。
std::queue(队列)
定义:
std::queue 是一个遵循先进先出(FIFO,First In First Out)原则的容器适配器。它只能在序列的一端(队尾)进行添加(push)操作,在另一端(队首)进行移除(pop)操作。
主要操作:
- push():在队尾添加一个元素。
- pop():移除队首元素。
- front():返回队首元素的引用,不移除它。
- back():返回队尾元素的引用,不移除它。
特点:
- 双端操作,即在队首进行移除操作,在队尾进行添加操作。
- 提供了迭代器支持,允许遍历队列中的所有元素。
与 std::deque 的不同.
- 操作限制:std::stack 和 std::queue 限制了操作的位置,而 std::deque 允许在两端自由操作。
- 迭代器支持:std::stack 不支持迭代器,std::queue 支持迭代器但只能访问队列中的元素,而 std::deque 提供了随机访问迭代器,可以高效地访问序列中的任何位置。
- 使用场景:如果你需要一个简单的后进先出或先进先出的数据结构,std::stack 或 std::queue 可能更适合。如果你需要一个能够在两端快速操作且支持随机访问的容器,std::deque 是更好的选择。
测试代码:
示例4
#include <stack>
namespace t06
{
void test_stack(long& value)
{
cout << "\ntest_stack()..............\n";
stack <string> c;//stack又叫栈,特点是先进后出
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.push(string(buf));//将随机数转为string类型,并使用push()将数据压入容器
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "stack.size(): " << c.size() << endl;
cout << "stack.top(): " << c.top() << endl;
c.pop();
cout << "stack.size(): " << c.size() << endl;
cout << "stack.top(): " << c.top() << endl;
//与前面的容器不同,stack不可以进行查找操作
}
} #include <queue>
namespace t07
{
void test_queue(long& value)
{
cout << "\ntest_queue()..............\n";
queue <string> c;//queue又叫队列,特点是先进先出
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.push(string(buf));//将随机数转为string类型,并使用push()将数据压入容器
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "queue.size(): " << c.size() << endl;
cout << "queue.front(): " << c.front() << endl;
cout << "queue.back(): " << c.back() << endl;
c.pop();
cout << "queue.size(): " << c.size() << endl;
cout << "queue.front(): " << c.front() << endl;
cout << "queue.back(): " << c.back() << endl;
//与前面的容器不同,queue也不提供查找操作
}
} How much memory space you need: 1000000
test_stack()..............
milli-seconds: 1050
stack.size(): 1000000
stack.top(): 12679
stack.size(): 999999
stack.top(): 17172
test_queue()..............
milli-seconds: 1027
queue.size(): 1000000
queue.front(): 21384
queue.back(): 1461
queue.size(): 999999
queue.front(): 10793
queue.back(): 1461红黑树-multiset容器
multiset容器结构类似二叉树,准确说是红黑树,这种结构的的查找会快很多,但是插入则会耗费一定时间,这些时间都花费在了排序上。
测试代码:
示例8
#include <set>
namespace t08
{
void test_multiset(long& value)
{
cout << "\ntest_multiset()..............\n";
multiset <string> c;//multiset结构式红黑树
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));//将随机数转为string类型,并使用insert()将数据存入容器
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "multiset.size(): " << c.size() << endl;
cout << "multiset.max_size(): " << c.max_size() << endl;
string target = get_a_target_string();
{
timeStart = clock();
auto pItem = ::find(c.begin(), c.end(), target);//使用全局::fingd()查找
cout << "::find(),milli-seconds: " << (clock() - timeStart) << endl;
if (pItem != c.end()) {
cout << "found, " << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
{
timeStart = clock();
auto pItem = c.find(target);//使用multiset自身的fingd()查找
cout << "c.find(),milli-seconds: " << (clock() - timeStart) << endl;
if (pItem != c.end()) {
cout << "found, " << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
} #include <map>
namespace t09
{
void test_multimap(long& value)
{
cout << "\ntest_multimap()..............\n";
multimap <long,string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.insert(pair<long,string>(i,buf));//此处使用了pair设置键值对
//值得注意,multimap不可以用[]做insert,这一点可以结合map容器理解,
//另外key是不会重复的,因为接收的是0-1000000,而值可能会重复,因为值是通过随机数函数rand()产生,范围为0-32767
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "multimap.size(): " << c.size() << endl;
cout << "multimap.max_size(): " << c.max_size() << endl;
long target = get_a_target_long();
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(),milli-seconds: " << (clock() - timeStart) << endl;
if (pItem != c.end()) {
cout << "found, (" << (*pItem).first <<", " <<pItem->second<<")" << endl;
}
else
{
cout << "not found!" << endl;
}
}
} How much memory space you need: 1000000
test_multiset()..............
milli-seconds: 3235
multiset.size(): 1000000
multiset.max_size(): 256204778801521550
target (0--32767):23456
::find(),milli-seconds: 59
found, 23456
c.find(),milli-seconds: 0
found, 23456
test_multimap()..............
milli-seconds: 1843
multimap.size(): 1000000
multimap.max_size(): 230584300921369395
target (0--32767):23456
c.find(),milli-seconds: 1
found, (23456, 31622)从测试结果看,因为不会抛弃重复的值,multiset的元素个数与大小相等,且存值会话费很多时间。 相比之下multimap存值时间会话费少一些。
unordered_multiset和unordered_multimap
std::unordered_map 和 std::unordered_set 是 C++ 标准库中的两种容器,它们基于哈希表实现。这两种容器提供平均时间复杂度为 O(1) 的快速访问,插入和删除操作。下面简单解释它们的概念图,包括桶和负载因子的说明。
概念图简述:
桶(Buckets):
在 std::unordered_map 和 std::unordered_set 中,哈希表被分为多个“桶”。 每个桶存储指向一个链表的指针(在 std::unordered_map 的情况下)或直接存储元素(在 std::unordered_set 的情况下)。 当元素被插入时,它们的哈希值决定了它们将被存储在哪个桶中。
链表(Chaining):
如果多个元素具有相同的哈希值(哈希冲突),它们将被存储在同一个桶中,并通过链表连接起来。 在 std::unordered_map 中,每个桶可能包含一个链表,链表中的每个节点存储一个键值对。 在 std::unordered_set 中,每个桶可能包含一个链表,链表中的每个节点存储一个元素。
负载因子(Load Factor):
负载因子是哈希表中已存储元素数量与桶数量的比率。 负载因子影响哈希表的性能。较高的负载因子可能导致更多的哈希冲突,从而增加链表的长度,降低性能。 当负载因子超过一个预设的最大值时,哈希表可能会进行重新哈希(rehashing),即增加桶的数量并重新分配所有元素到新的桶中。
概念图说明:
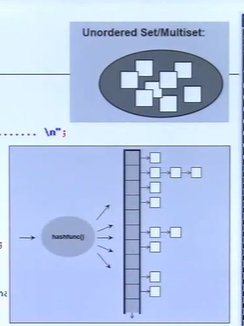
- 桶:哈希表被分为多个桶,每个桶可以存储一个链表的头部指针。
- 指针:在 std::unordered_map 中,每个指针指向一个链表节点,该节点包含一个键值对。在 std::unordered_set 中,每个指针直接指向存储的元素。
- 元素:链表中的元素,可能是键值对或单个值。
负载因子说明:
重新哈希(Rehashing):当负载因子超过 max_load_factor() 时,哈希表会进行重新哈希,增加桶的数量,并将所有元素重新分配到新的桶中。 动态调整:这种动态调整机制使得 std::unordered_map 和 std::unordered_set 能够根据元素数量的变化自动调整大小,以保持操作的性能。 通过这种结构,std::unordered_map 和 std::unordered_set 能够在大多数情况下提供快速的访问和修改操作,但需要注意,极端情况下(如所有元素哈希到同一个桶中)性能可能会退化到 O(n)。
测试代码:
示例9
#include <unordered_set>
namespace t10
{
void test_unordered_multiset(long& value)
{
cout << "\ntest_unordered_multiset()..............\n";
unordered_multiset <string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));//将随机数转为string类型,并使用insert()将数据存入容器
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "unordered_multiset.max_size(): " << c.max_size() << endl;// 打印 unordered_multiset 能存储的最大元素数量
cout << "unordered_multiset.bucket_count(): " << c.bucket_count() << endl;// 打印 unordered_multiset 中桶的数量,即存储指向一定长度链表的指针的个数
cout << "unordered_multiset.max_load_factor(): " << c.max_load_factor() << endl;// 打印 unordered_multiset 可以使用的最大负载因子,它影响桶中链表的最大长度
cout << "unordered_multiset.max_bucket_count(): " << c.max_bucket_count() << endl;// 打印 unordered_multiset 可以使用的最大桶的数量,这个值通常由桶的增长策略和哈希表的容量决定
for (unsigned i = 0; i < 20; i++) {
cout << "bucket # " << i << " has " << c.bucket_size(i) << " element.\n";
}
string target = get_a_target_string();
{
timeStart = clock();
auto pItem = ::find(c.begin(), c.end(), target);//使用全局::fingd()查找
cout << "::find(),milli-seconds: " << (clock() - timeStart) << endl;
if (pItem != c.end()) {
cout << "found, " << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
{
timeStart = clock();
auto pItem = c.find(target);//使用multiset自身的fingd()查找
cout << "c.find(),milli-seconds: " << (clock() - timeStart) << endl;
if (pItem != c.end()) {
cout << "found, " << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
} How much memory space you need: 1000000
test_unordered_multiset()..............
milli-seconds: 1867
unordered_multiset.max_size(): 329406144173384850
unordered_multiset.bucket_count(): 1048576
unordered_multiset.max_load_factor(): 1
unordered_multiset.max_bucket_count(): 1152921504606846975
bucket # 0 has 0 element.
bucket # 1 has 0 element.
bucket # 2 has 0 element.
bucket # 3 has 0 element.
bucket # 4 has 0 element.
bucket # 5 has 0 element.
bucket # 6 has 0 element.
bucket # 7 has 0 element.
bucket # 8 has 0 element.
bucket # 9 has 0 element.
bucket # 10 has 0 element.
bucket # 11 has 0 element.
bucket # 12 has 0 element.
bucket # 13 has 0 element.
bucket # 14 has 0 element.
bucket # 15 has 0 element.
bucket # 16 has 0 element.
bucket # 17 has 0 element.
bucket # 18 has 0 element.
bucket # 19 has 0 element.
target (0--32767):12345
::find(),milli-seconds: 108
found, 12345
c.find(),milli-seconds: 0
found, 12345 #include <unordered_map>
namespace t11
{
void test_unordered_multimap(long& value)
{
cout << "\ntest_unordered_multimap()..............\n";
multimap <long, string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try
{
snprintf(buf, 10, "%d", rand());
c.insert(pair<long, string>(i, buf));
}
catch (exception& p)
{
cout << "i=" << i << " " << p.what() << endl;
abort();//发生异常使用该函数退出程序
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "unordered_multimap.size(): " << c.size() << endl;
cout << "unordered_multimap.max_size(): " << c.max_size() << endl;
long target = get_a_target_long();
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(),milli-seconds: " << (clock() - timeStart) << endl;
if (pItem != c.end()) {
cout << "found, (" << (*pItem).first << ", " << pItem->second << ")" << endl;
}
else
{
cout << "not found!" << endl;
}
}
} How much memory space you need: 1000000
test_unordered_multimap()..............
milli-seconds: 1942
unordered_multimap.size(): 1000000
unordered_multimap.max_size(): 230584300921369395
target (0--32767):12345
c.find(),milli-seconds: 0
found, (12345, 5839)set和map容器
测试代码:
示例10
namespace t12
{
void test_set(long& value){
cout << "\ntest-set()............................\n" << endl;
set<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i) {
try
{
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));
}
catch (exception& p)
{
cout << "i = " << i << p.what() << endl;
abort();
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "set.max_size() " << c.max_size() << endl;
cout << "set.size() " << c.size() << endl;
string target = get_a_target_string();
{
timeStart = clock();
auto pItem = ::find(c.begin(), c.end(), target);
cout << "::find(), milli-seconds: " << (clock() - timeStart) << endl;
if (pItem != c.end()) {
cout << "found, " << *pItem << endl;
}
else
cout << "not fount!" << endl;
}
{
timeStart = clock();
auto pItem = c.find(target);
cout << "find(), milli-seconds: " << (clock() - timeStart) << endl;
if (pItem != c.end()) {
cout << "found, " << *pItem << endl;
}
else
cout << "not fount!" << endl;
}
}
} namespace t13
{
void test_map(long& value) {
cout << "\ntest_map()............................\n" << endl;
map<long,string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i) {
try
{
snprintf(buf, 10, "%d", rand());
c[i] = string(buf);//注意这种使用方式
}
catch (exception& p)
{
cout << "i = " << i << p.what() << endl;
abort();
}
}
cout << "milli-seconds: " << (clock() - timeStart) << endl;
cout << "map.max_size() " << c.max_size() << endl;
cout << "map.size() " << c.size() << endl;
long target = get_a_target_long();
{
timeStart = clock();
auto pItem = c.find(target);
cout << "::find(), milli-seconds: " << (clock() - timeStart) << endl;
if (pItem != c.end()) {
cout << "found value, " << pItem->second << endl;
}
else
cout << "not fount value!" << endl;
}
}
} How much memory space you need: 1000000
test-set()............................
milli-seconds: 2133
set.max_size() 256204778801521550
set.size() 32768
target (0--32767):12345
::find(), milli-seconds: 1
found, 12345
find(), milli-seconds: 0
found, 12345
test_map()............................
milli-seconds: 1937
map.max_size() 230584300921369395
map.size() 1000000
target (0--32767):12345
::find(), milli-seconds: 0
found value, 5839分配器测试程序
4.C++2.0特性的使用
VS 2022的设置
首先你可以先用下面的代码测试使用可以执行:
#include <iostream>
void printTypes() {
}
template <typename T, typename... U>
void printTypes(const T& t, const U&... u) {
std::cout << t << std::endl;
printTypes(u...);
}
int main() {
printTypes('a', 1.5, 'b');
}如果报错了,如typename…未定义,那么请你按照如下步骤操作,
- C++语言标准选择
预览 - 最新 C++ 工作草案中的功能 (/std:c++latest) - 启用实验性C++标准库模块–
是 - 生成ISO C++23标准库模块 –
是
const补充
| const 参数 | non-const 参数 | |
|---|---|---|
| const 函数 | 可执行 | 可执行 |
| non-const 函数 | 报错 | 可执行 |
使用const需要注意两个问题,参数是否需要修改,参数进入函数内后数据是都会修改。解决这两个问题,在需要的地方加上const
还有一种情况,
template<typename T>
class foo {
public:
T fooTo(T str) const { return str; };
T fooTo(T str) {return str;};
};
int main() {
foo < char > f;
const char x = 'a';
char y = 'c';
std::cout << f.fooTo(x) << std::endl;
std::cout << f.fooTo(y) << std::endl;
}运行结果如下:
 在这个例子中,带const的参数只会执行带const的函数,而不带const的参数会只会执行不带const的函数,这就是带const和不带const函数出现时的情况。
但是这个结果我并不是很满意,应为我试着在不带const函数内部修改传入的参数,代码执行时将不会以我上面说的结论出现。或许还需要在研究研究……
在这个例子中,带const的参数只会执行带const的函数,而不带const的参数会只会执行不带const的函数,这就是带const和不带const函数出现时的情况。
但是这个结果我并不是很满意,应为我试着在不带const函数内部修改传入的参数,代码执行时将不会以我上面说的结论出现。或许还需要在研究研究……
3.导读
书籍推荐
- 《C++ Premier》
- 《C++ Programming Language》
- 《Effective Modern C++》
- 《Efficient C++》
- 《The C++ standard library》
- 《STL C++》
- 《STL源码剖析》
- 《算法+数据结构=程序》
- “网站CPLusPlus”
- “网站CppReference”
- “网站gcc.gnu”
学习路线
conversion function-转换函数
接下来以一个分数的代码例子说明转换函数。
情况1:让值转为其他类型
class Fraction
{
private:
int m_num, m_den;
public:
Fraction(int num, int den = 1)
: m_num(num),m_den(den){}
opertaor double() const {
return (double)(m_num/m_den);
}
};
//使用示例:
Fraction f(2,5);
double d = 4+f;在上述的示例中,d = 4+f;程序会先判断有没有写opertaor +,如果没有会试着将f通过opertaor double()转为double类型。
情况2:non-explicit-one-argument-ctor,不带explicit的一个参数的构造函数,将其他类型转为预所写类的类型
class Fraction
{
private:
int m_num, m_den;
public:
Fraction(int num, int den = 1)
: m_num(num),m_den(den){}
opertaor double() const {
return (double)(m_num/m_den);
}
};
//使用示例:
Fraction f1(2,5);
Fraction f2 = 4+f1;同样在这个地方会先将4转为Fraction,然后在进行相加,转换函数使用的是构造函数,构造函数默认第二个参数是1,也就一个参数时也可用,但这个意思并不是说f1(2)你不写第二个参数。
虽然向上面的情况可行,但是当你把两个情况结合在一起时,就会报错,例如你如下写:
class Fraction
{
private:
int m_num, m_den;
public:
Fraction(int num, int den = 1)
: m_num(num),m_den(den){}
opertaor double() const {
return (double)(m_num/m_den);
}
Fraction operator + (const Fraction& f){
return Fraction(……);
}
};情况3:explicit-one-argument-ctor,带explicit的一个参数的构造函数 这个时候再使用刚才的例子,程序就会报错,因为此时是两种情况的结合,意味着两种情况都可以实现,编译器此时就不知道该使用哪个方法,为了解决这个问题,你可以使用关键字explicit来约束构造函数,让其他类型如法转为所写类,这个时候编译器会报错说无法将double类型转为Fraction。如下:
class Fraction
{
private:
int m_num, m_den;
public:
explicit Fraction(int num, int den = 1)
: m_num(num),m_den(den){}
opertaor double() const {
return (double)(m_num/m_den);
}
Fraction operator + (const Fraction& f){
return Fraction(……);
}
};
//示例
Fraction f1(2,5);
Fraction f2 = 4+f1;编写的类大两个大方向
智能指针


伪函数
这样的类会像函数一样接收参数,返回某一类型的值通常会看到类中重载operate() (……){……}函数。
特化
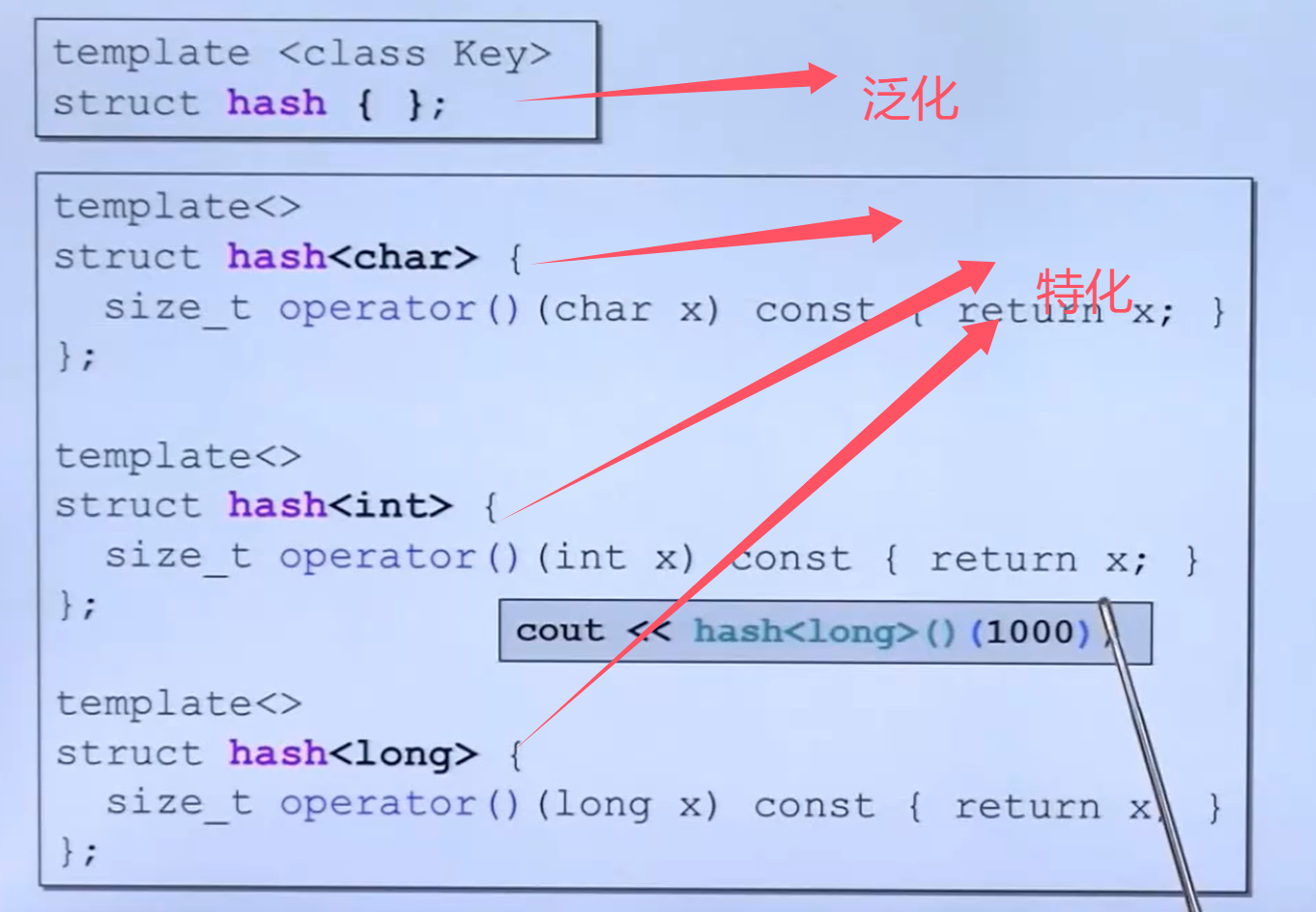
偏特化–对应泛化
- 个数上的偏
以我的理解就是假设原先设计的模版为
template <typename a, typename b……>
class A
{……}现在我使用偏特化,写为
template <typename b>
class A<bool, typename b……>
{……}也就是第一个参数已经确定是bool类型了。(大概先这么理解吧:smile: :smile: :smile:)
- 范围上的偏特化
一般我们的类模版你可以任意指定类型,但是现在我想写一个用指针指向的类模板,那么他就被限制在一定的范围内了
template <typename a>
class A
{……}
//范围偏特化
template <typename a>
class A<typename* a>
{……}模板模板类
假设我要创建一个容器,并指定这个容器内容的类型,这个时候可以使用模版模版类,详细看下图:
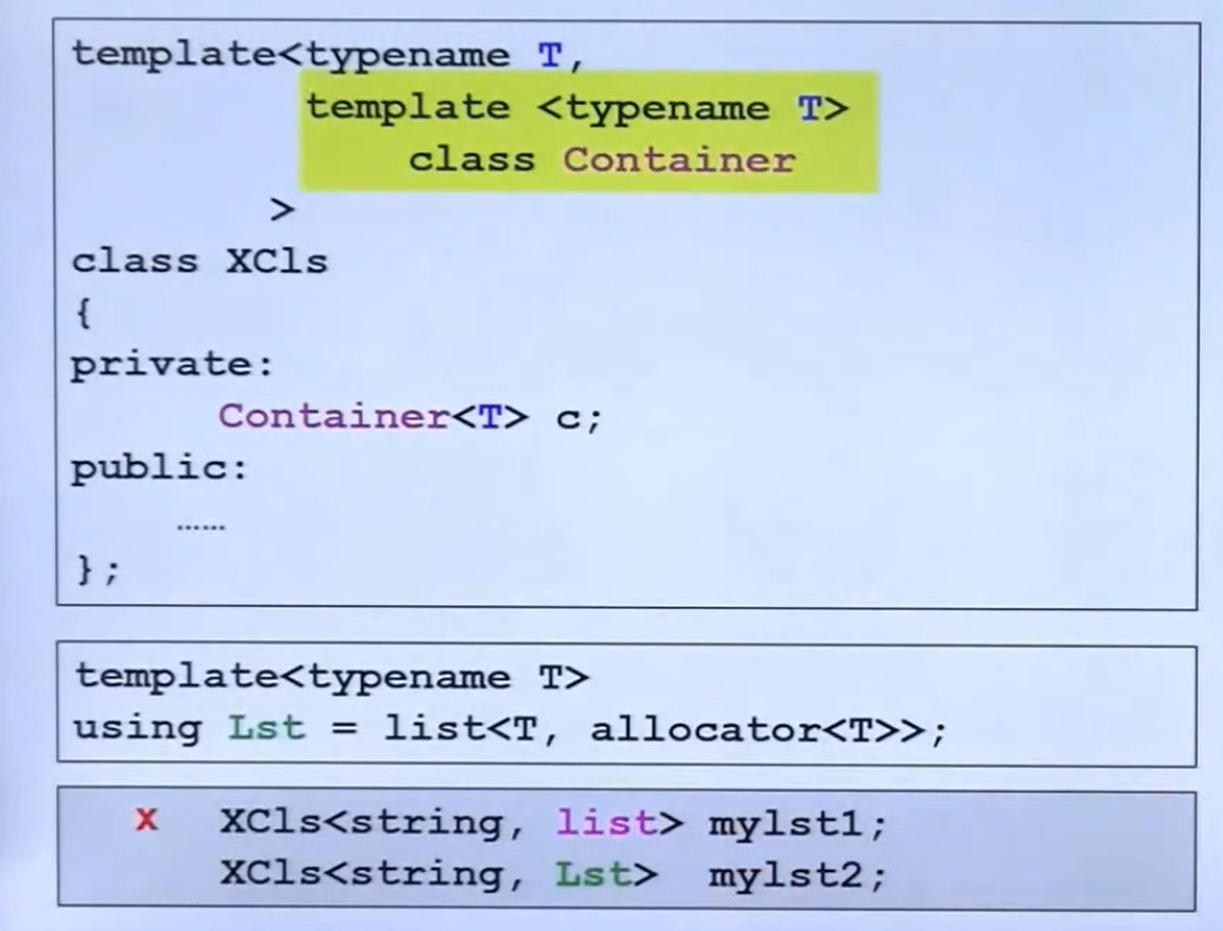
2.组合与继承
类与类的三种关系
Composition-复合
以我个人的理解,复合就是一个类中包含有另外一个类,使用到另一个类的内容。复合的类他们的构造和析构函数运行次序是,构造函数有内到外依次运行,析构函数则相反。可以使用下图表示这种关系
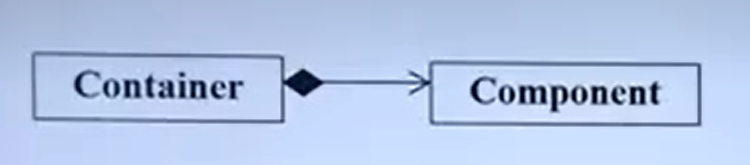
delegation-委托
当一个类欲用一个指针指向另一个类,以达到想使用时就指向这个类的这种关系就叫delegation,假设我要实现一个计算,此时指针指向这个函数,让函数去做这个计算。这有些类似于复合,但是这里重点在于指针的使用。在写一些功能的时候也建议使用这种关系的特性,因为这样就将两者隔开,起到一定的保护作用。参考下图:

Inheritance-继承
在C++有三种继承方式,其中public是常用的一种,继承表示从一个类中集成某些属性成为 另外一种 类。

Inheritance关系的两个类它们的构造函数与析构函数执行次序与之前描述复合时一样。如下图是这种关系的表示方法:
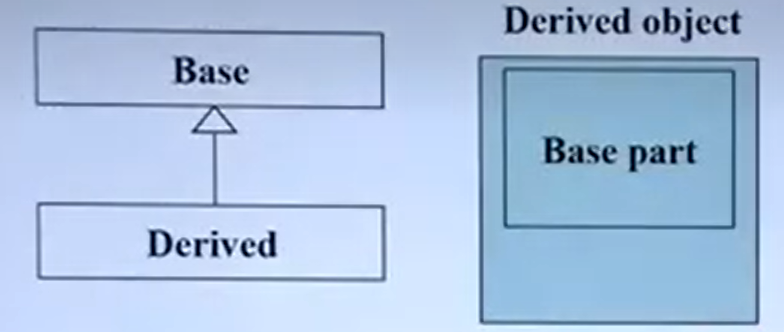
- 构造函数(constructor):由内到外,代码表示为
SunFunction::SunFunction(…):base(){…}; - 析构函数(destructor):由外到内,代码表示为
SunFunction::SunFunction(…){……~base();};
值得注意的是,如果一个类将来可能是父类,那么需要在析构函数前加virtual关键字,否则会报错undefine behavior。
设计模式
**参考书籍:**Design PatternsExplained Simply
1.代码编写规范
如何写一个标准的.h文件
以下内容来自B站。
接下来将以复数的库文件为例来回答这个问题,下面是一段参考复数库文件代码:
class complex
{
private:
/* data */
double re,im;
friend complex& __doapl (complex*,const complex&);
public:
complex (double r,double i)
:re(r),im(i) //这是一个构造函数,这种写法意思是初始化变量
{};
complex& operator += (complex operator&);
double read () const {return re;} //这里需要加const 意思就是修饰函数的返回值,不允许改变返回值类型
double imag () const {return im;}
};构造函数的特性
这一点需要关注下面的代码:
complex (double r,double i)
:re(r),im(i) //这是一个构造函数,这种写法意思是初始化变量
{};关于const修饰符
如上面说到的,函数返回最好是加const,这样可以应付下面情况的发生。
const的使用
double read () const {return re;}
double imag () const {return im;}此时做如下两种使用都是正确的
complex com1(1,2);
cout<<com1.real()<<endl; const complex com1(1,2);
cout<<com1.real()<<endl; double read () {return re;}
double imag () {return im;}此时做如下两种使用只有第一种可以被执行,第二种会报错。
complex com1(1,2);
cout<<com1.real()<<endl; const complex com1(1,2);
cout<<com1.real()<<endl;函数传递和返回值的两种方式
pass by values:传值。在传输的事单字节或者字节数较少的情况下使用,比如传一个字符。
pass by reference:传引用。在C++中引用的底层逻辑就是传指针,也就是类似穿了地址,也就是只传输4个字节, 在这种情况下你可以使用const修饰符,迫使函数不能修改值,如果希望函数对值进行处理则可以不加
void re(const classname& cl){};//加了const
void re(classname cl){};//没有加const
对于返回值,我们可以返回值,也可以返回引用,但什么情况下返回的是引用呢?
在设计类中的函数时,可以先考虑返回类型适不适合引用,如果返回的是已经存在的地址,那么可以选择返回类型为引用,否则不使用。
inline complex&
__ap(complex * this ,const complex & c){
this->re += c.re;
this->im += c.im;
return *this;
}向上面的函数就是使用了引用返回。
操作符重载-1:成员函数

操作符重载-2:非成员函数
假设现在要计算复数的加减,如下:
complex com1(1,0);
complex com2(2,9);
complex com3;
com3 = com1 + com2;
com3 = com1 + 2;
com3 = 0 + com2;
……对于这段代码在库文件中,要对加法做非成员函数重载,以应付 不同的情况。
接下来在考虑一个问题,就是如果我们只是做cout<<com1;那么对于«函数返回值可以是void类,但是如果我们做的是cout<<com1<<com2<<endl;
这样的操作返回类型为void类型,那么当运行cout<<com1后就无法运行<<com2<<endl的代码.
很显然要让代码继续运行,我们还需要返回iostream类型,而且使用return by reference返回方法,也就是返回引用。如下图:

小结
通过以上的简单讲解,我们可以总结一下,再写一个类的时候,我们需要注意以下几点:
- 确定类的数据并写在private中;
- 对于构造函数要善于使用初始化数据方法;
- 对于函数要想一想,返回类型是否可以改变,要不要写const;
- 对于函数类型和返回值,要传值还是传引用,要返回值还是返回引用。
是否返回引用最最好的判断标准就是,值在经过函数运算后存储在函数外,或说是一个以存在的存储地址,否则不返回引用
接下来通过学习string.h库,进一步了解指针的使用
一般有指针的类需要写三个特殊函数拷贝构造、拷贝析构、拷贝赋值,
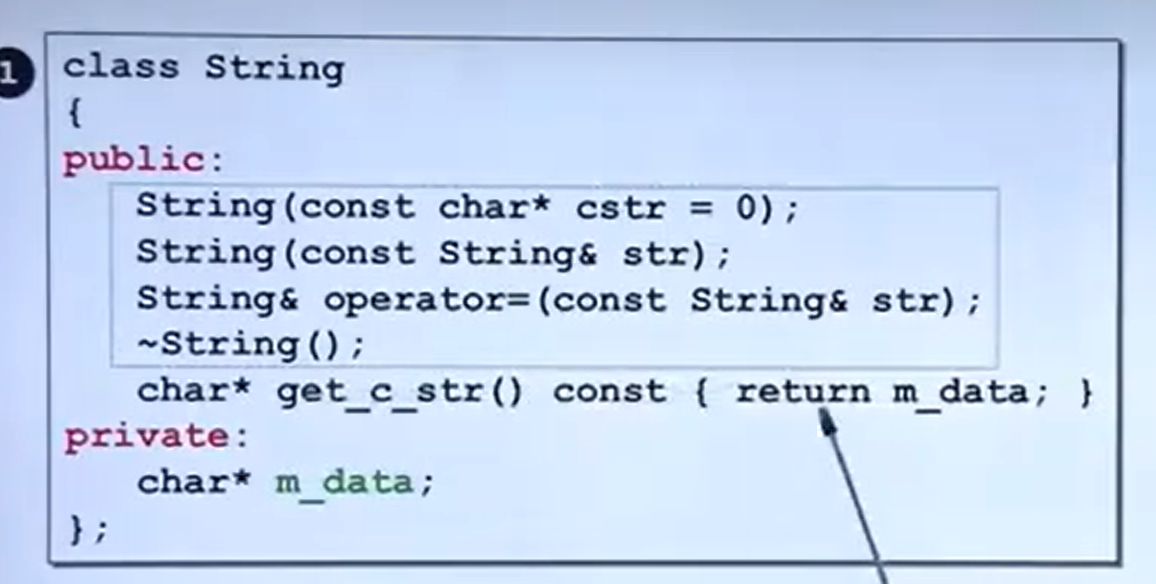
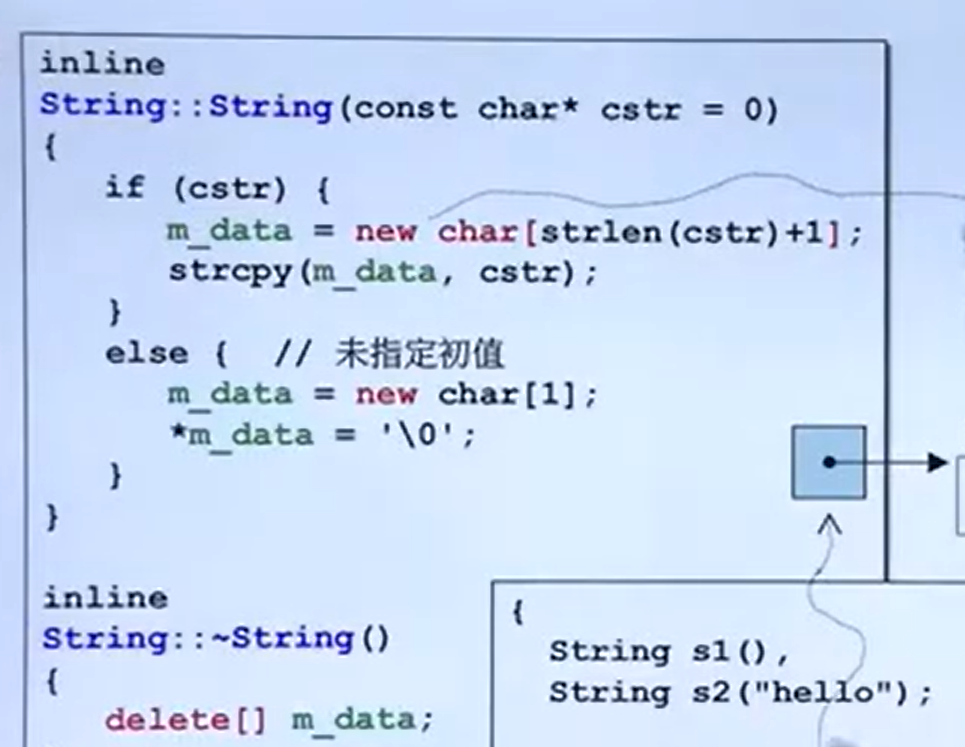

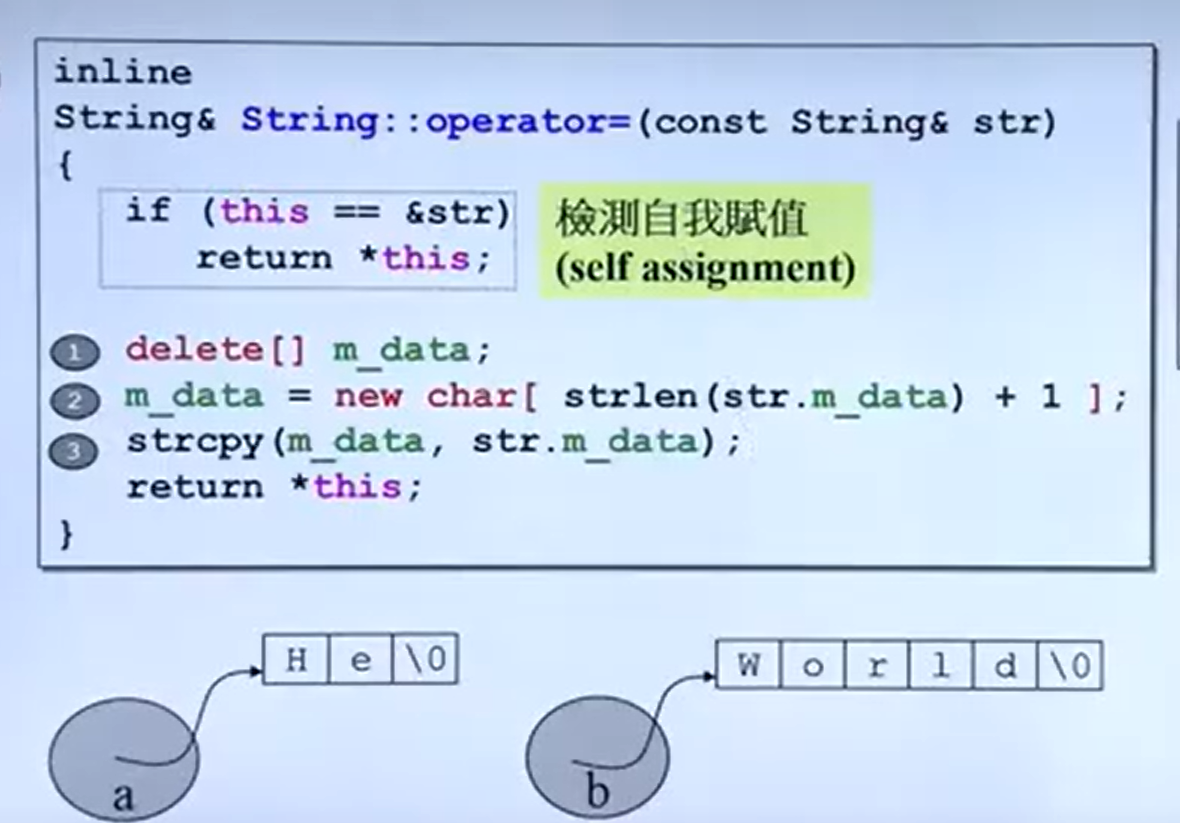
有时候还需要用到new 和 delete。
stack(栈)和heap(堆)
如下代码:
class String{……};
……
{
String str("hello");
String str1 = new String();
……
}上面的{}内的代码就是存储在stack中,而经过new的变量存在heap中;
stack object 的生命周期
在{}内的代码执行结束后,自动调用析构函数将变量清理掉,如下代码,
class String{……};
……
{
String str("hello");
……
}static local object 的生命周期
添加关键字static的变量成为静态变量,在作用于如下面代码的{}结束后不会被析构函数清理掉, 变量会存储直到程序结束。
class String{……};
……
{
static String str("hello");
……
}global objects 生命周期
全局变量在程序接收后才会被清理掉。
class String{……};
String str("hello");
……
{
……
}调用new和delete的过程
在使用new的地方需要使用delete清理内存,防止内存泄露。
调用new过程:
调用delete的过程:
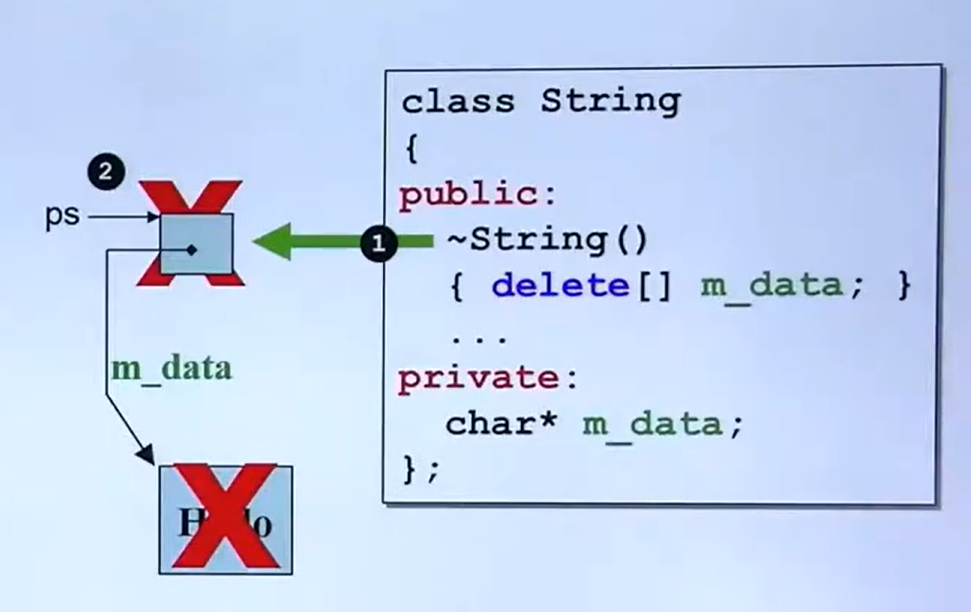
代码 分配内存大小左图是调试模式下的内存分配,右图是非调试模式下分配的内存

new与delete的搭配,在删除数组时需要加上[]否则编译器不知道你要删的是数组:
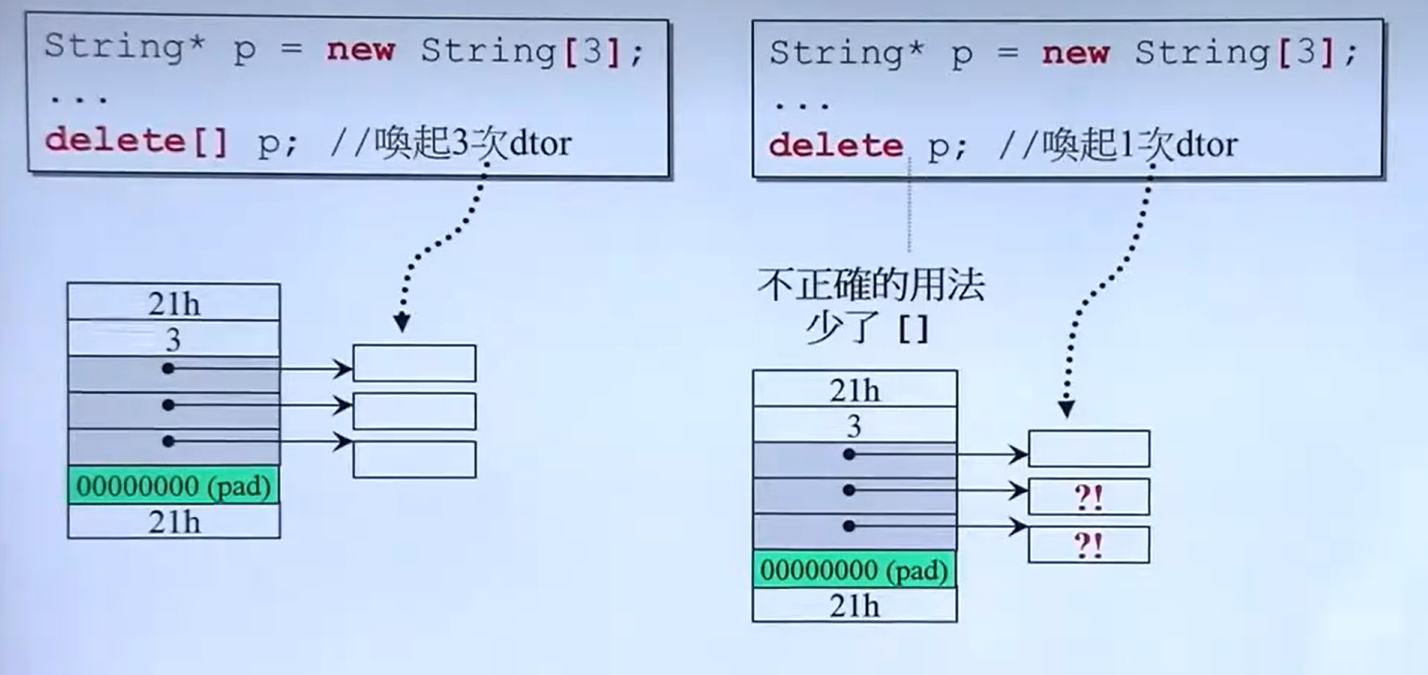
new和delete的补充
对new和delete的重载,用于设计内存管理,如内存池等操作。
重载::new,::delete
重载的函数中,new操作会接收一个大小,该大小由编译器传入,而delete传入的是一个指针,如下图;

如果不想使用类中的new和delete,可以在二者之前加上:,如::new,::delete,这样在调用函数时就不会调用类设计中的new和delete重载,而是全局的。
类中重载的new和delete
//类
class F{
...
public:
void* operate new(size_t);//1
void operate delete(void*,size_t);//2,size_t可不写
...
}
//代码段1的内部操作
try{
void* mem = operate new(size_t);
p = static_cast<F*>(mem);//类型转换
p->F::F();//构造函数
}
//代码段2的内部操作
p->~F();
operate delete(p);
// main函数调用示例
{
F* p = new F();
...
delete p;
}类中重载的new[]和delete[]
代码整体流程与上一个情况类似,区别在于new[]是申请数组内存,在销毁的时候如果不使用delete[]释放内存,delete只会执行一次,导致内存没有完全释放,详细代码如下:
//类
class F{
...
public:
void* operate new(size_t);//1
void operate delete(void*,size_t);//2,size_t可不写
...
}
//代码段1的内部操作
try{
void* mem = operate new(size_t*N + 4);//指针占4个字节
p = static_cast<F*>(mem);//类型转换
p->F::F();//构造函数
}
//代码段2的内部操作
p->~F();//析构函数
operate delete(p);
// main函数调用示例
{
F* p = new F[N];
...
delete[] p;
}new,delete使用示例
using namespace std;
class Foo
{
private:
int _id;//4个字节
long _data;//4个字节
string _str;//40个字节
public:
Foo() :_id(0) { cout << "default ctor.this = " << this << "id: " << _id << endl; };
Foo(int i) :_id(i) { cout << "ctor.this = " << this << "id: " << _id << endl; };
~Foo() { cout << "dtor.this = " << this << "id: " << _id << endl; };
static void* operator new(size_t size);
static void operator delete(void* p, size_t size);
static void* operator new[](size_t size);
static void operator delete[](void* p, size_t size);
};
void* Foo::operator new(size_t size)
{
Foo* p = (Foo*)malloc(size);
cout << "new size = " << size << endl;
return p;
}
void Foo::operator delete(void* p, size_t size)
{
cout << "delete size = " << size << endl;
free(p);
}
void* Foo::operator new[](size_t size)
{
Foo* p = (Foo*)malloc(size);
cout << "new[] size = " << size << endl;
return p;
}
void Foo::operator delete[](void* p, size_t size)
{
cout << "delete[] size = " << size << endl;
free(p);
}运行结果如下:
new size = 48
default ctor.this = 00000191EC67A460id: 0
dtor.this = 00000191EC67A460id: 0
delete size = 48
_____________________________________________
new[] size = 104
default ctor.this = 00000191EC673438id: 0
default ctor.this = 00000191EC673468id: 0
dtor.this = 00000191EC673468id: 0
dtor.this = 00000191EC673438id: 0
delete[] size = 104为什么new[]操作会多出8个字节呢?
我看课程视频,老师说new[]分配的内存块会在最前面存储计数量,占用4个字节,表示数组大小,但是我在电脑上运行会多出8个字节,查阅资料可能与系统、对齐方式、编译器等有关。
对new的分配额外内存
假设分配内存的同时需要额外分配一定的内存,可以参考下面的代码:

小结
对于包含有指针的类,在必要时写上拷贝构造、拷贝赋值、析构函数,如下代码
class String
{
private:
char* m_data;
public:
String(const char* cstr = 0); //构造函数
String(const String& str); //拷贝构造函数
String& operator= (const String& str); //拷贝赋值函数
~String(); //析构函数
char* get_c_str() const {return m_data;}
}; String::~String()
{
delete[] m_data;
} inline
String::String(const char* cstr = 0)
{
if (cstr)
{
m_data = new char[strlen(cstr)+1];
strcpy(m_data, cstr);
}else{
m_data = new char[1];
strcpy(m_data,'\0');
}
} inline
String::String(const String& cstr){
m_data = new char[strlen(cstr.m_data) + 1];
strcpy(m_data, cstr);
} inline
String& String::operator=(const String& str)
{
if(this == &str)
return *this;
delete[] m_data;
m_data = new char[strlen(str.m_data) + 1];
strcpy(m_data, str);
return *this;
}补充内容static
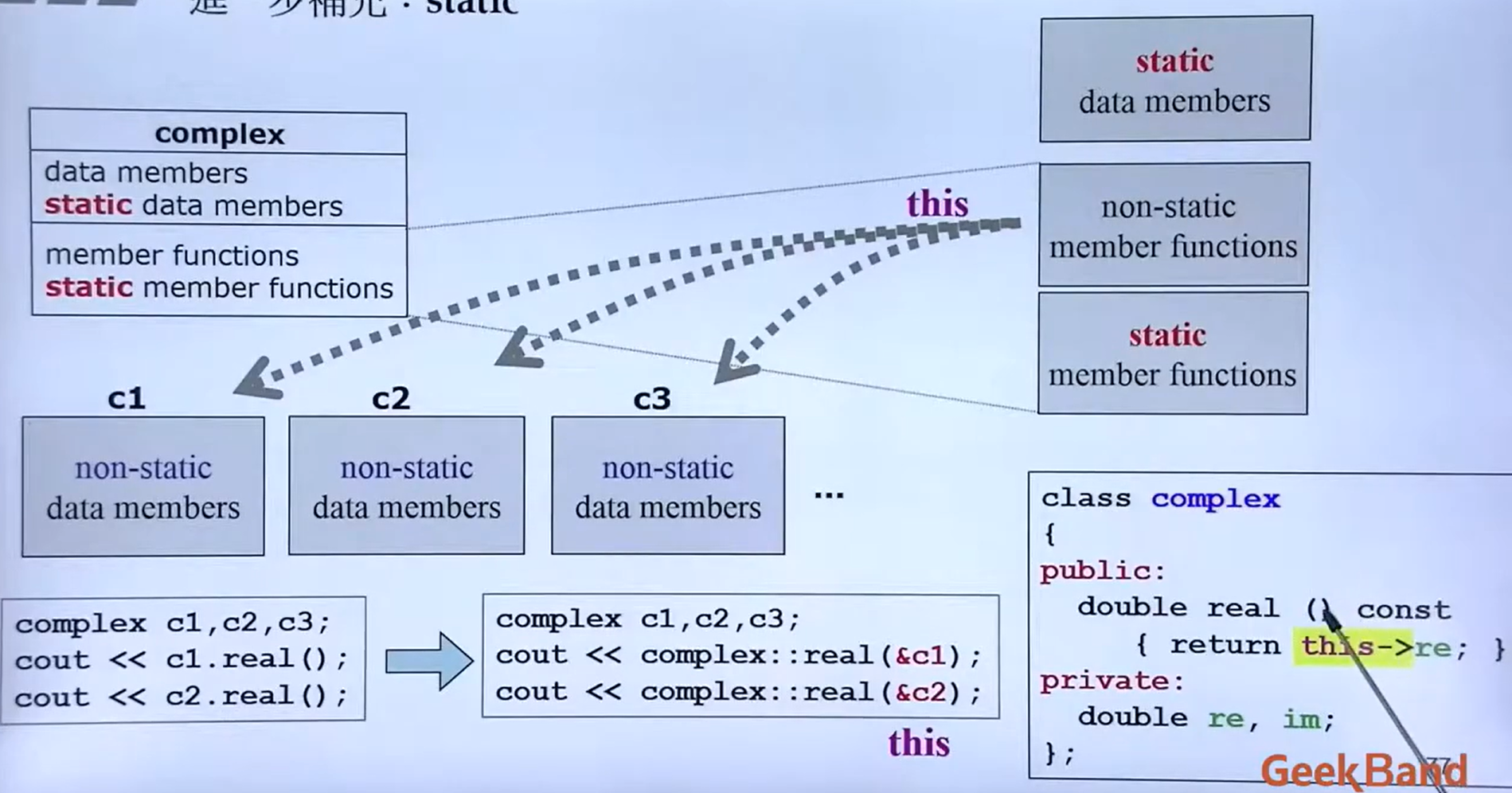
static在private中的使用例子


class template

function template
member template 成员模板
类模板中,还有类模板,通常是对构造函数的操作,如下图:

如下图代码

用意就是当一个指针指向父类时,初始化让他指向子类,那么此时需要实现上图类中的代码。
namespace(命令空间)
使用示例:
using namespace std;
{
……
}使用方法:
#include <iostream>
using namespace std;
int main()
{
cout<<……;
cin<<……;
return 0;
} #include <iostream>
using std::cout;
int main()
{
cout<<……;
std::cin<<……;
return 0;
}或者
#include <iostream>
int main()
{
std::cout<<……;
std::cin<<……;
return 0;
}21.C语言程序设计(含面试)
- 1.在线题库练习
网站
课程学习
- “书籍”
- “大学慕课” Github项目
- “C/C++面试总结项目”
- “书籍:Github项目”
- “C/C++面试总结”
- “系统设计”
题目笔记
1.
cahr *s = "AAAA"指针接受一个字符串(右值),当想通过s[0] = ‘B’修改时是无法修改成功的,因为"AAAA"只能读,不能写。 2.一般函数内如果返回char s[] = {“abcd”};那么一般会报错,因为这是一个局部变量,但s[]修改为*s就不会有问题。因为 *s指向的地址是固定的。 3.在自动类型转换中:
21.C语言程序设计(含面试) 的子部分
1.在线题库练习
网站
课程学习
- “书籍”
- “大学慕课” Github项目
- “C/C++面试总结项目”
- “书籍:Github项目”
- “C/C++面试总结”
- “系统设计”
题目笔记
1.cahr *s = "AAAA"指针接受一个字符串(右值),当想通过s[0] = ‘B’修改时是无法修改成功的,因为"AAAA"只能读,不能写。
2.一般函数内如果返回char s[] = {“abcd”};那么一般会报错,因为这是一个局部变量,但s[]修改为*s就不会有问题。因为 *s指向的地址是固定的。
3.在自动类型转换中:
unsiged int a = 9;
int b = 1;
printf("%d", b+a);此处会触发隐式转换——int类型转为uniged int 类型。
4.大端模式和小端模式的作用是什么,为什么会出现这两种模式?
作用: **大端模式:**在这种模式下,数据的高字节(最重要的字节)保存在内存的低地址处,而数据的低字节(最不重要的字节)保存在内存的高地址处。这种方式类似于人类读写数值的习惯,即从高位到低位 。 **小端模式:**在这种模式下,数据的低字节保存在内存的低地址处,而数据的高字节保存在内存的高地址处。这种方式在进行数据类型转换时不需要调整字节内容,直接截取低字节即可
测试代码:
#include <stdio.h>
int main(){
int i;
union test{
unsigned int n;
char arr[4];
};
union test num;
num.n = 0x12345678;//注意:12所在位置是高位
for(i = 0; i<4; i++){
printf("&arr[%d] = %p, arr[%d] = %#x\n",i,&num.arr[i],i,num.arr[i]);
}
return 0;
}
/*
代码解释:
代码中,%x表示输出16进制,x前加 # 标志表示,如果使用 %ox(八进制),
则输出的数前面会加上前缀 0;如果使用 %#x 或 %#X(十六进制),
则输出的数前面会加上前缀 0x 或 0X。这样做可以明确地表示数值的进制,
便于阅读和理解。
结果:
&arr[0] = 000000000062FE10, arr[0] = 0x78
&arr[1] = 000000000062FE11, arr[1] = 0x56
&arr[2] = 000000000062FE12, arr[2] = 0x34
&arr[3] = 000000000062FE13, arr[3] = 0x12
结论:
高位存储在高地址,所以是小端模式。
*/
5.printf的返回值类型是变量的字符个数。 6.#和##运算符的使用
#include <stdio.h>
#define T(x) printf(""#x" square is the ",(x)*(x))
#define TEST(n) X##n
int main(void){
T(4);
int TEST(0) = 10;
int TEST(1) = 20;
printf("%d",X1);
}结果:
4 square is the 16
X1 = 107.结构体中存储字符串时我们可以使用字符指针或者字符数组,但是一般推荐字符数组。选择字符数组还是字符指针取决于具体的应用场景和需求。如果字符串长度固定或较短,且对性能和内存连续性有要求,字符数组可能是更好的选择。如果需要灵活处理不同长度的字符串,或者字符串长度可能非常大,使用字符指针可能更合适,但需要更加小心地管理内存。
8.strlen()和strcpy()
strlen() 和 strcpy() 是 C 语言标准库中的两个常用函数,它们用于处理字符串。下面分别解释它们的用途和使用时需要注意的事项。
strlen() 函数
用途:
strlen() 函数用于计算一个以空字符('\0')结尾的字符串的长度。它返回字符串的长度,不包括最后的空字符。
函数原型:
size_t strlen(const char *str);使用注意事项:
- 参数必须是以空字符结尾的字符串:如果传入的参数不是以空字符结尾的字符串,
strlen()会一直读取内存直到遇到空字符,这可能导致程序读取到未分配的内存区域,造成越界错误。 - 返回值类型:
strlen()返回的是size_t类型,它是一个无符号整数类型,用于表示大小或长度。在比较时,需要注意不要与有符号整数类型进行比较,以避免潜在的负值问题。 - 效率问题:
strlen()需要遍历整个字符串直到找到空字符,因此对于非常长的字符串,可能会有一定的性能开销。
strcpy() 函数
用途:
strcpy() 函数用于将源字符串(包括空字符)复制到目标字符串中。它会覆盖目标字符串原有的内容。
函数原型:
char *strcpy(char *dest, const char *src);使用注意事项:
- 目标字符串必须足够大:在使用
strcpy()之前,必须确保目标字符串dest有足够的空间来存储源字符串src的内容,包括最后的空字符。否则,可能会导致缓冲区溢出,这是常见的安全漏洞。 - 不检查目标字符串大小:
strcpy()不会自动检查目标字符串的大小,如果目标字符串空间不足,会发生溢出。 - 不进行类型检查:
strcpy()不会对传入的参数类型进行检查,因此传入的参数必须是字符数组或字符指针。 - 返回值:
strcpy()返回目标字符串的指针,通常用于链式操作,但需要注意不要因此覆盖了重要的指针值。 - 安全性问题:由于上述原因,
strcpy()在很多情况下被认为是不安全的。在实际编程中,推荐使用strncpy()或其他更安全的字符串复制函数,这些函数允许指定最大复制的字符数,从而避免溢出。
9.修改字节对齐方式 :#pragma pack(n) //n表示字节对起数,如2,4,8,
10.不同位数电脑的字节对齐方式
解释代码含义:
#define offsetof(TYPE, MEMBER) ((size_t ) &((TYPE *)0)->MEMBER)(TYPE *)0:将0强制转换为TYPE类型指针,p = (TYPE *)0;((TYPE *)0)-> MEMNER:通过指针访问MEMBER成员,&((TYPE *)0)-> MEMNER:取得成员地址((size_t ) &((TYPE *)0)->MEMBER):将成员地址转为size_t类型 总结:该宏定义的作用是求出MEMBER成员变量在TYPE中的偏移量。
示例:
//#pragma pack(4)
#include <stdio.h>
#define offsetof(TYPE, MEMBER) ((size_t ) &((TYPE *)0)->MEMBER)
typedef struct s
{
/* data */
union {
int a;//4字节
char str[10];//10字节
};
struct s* next;
}S;
int main(){
printf("%ld",offsetof(S, next));
return 0;
}结果为16,因为电脑是64位的,所以以8字节对齐,联合体字节大小以最大的成员变量为准,故联合体的字节大小是10个字节
12.返回二进制数中1的个数(经典题目)

13.求2的n次方

14.操作符[]的重载,代码实现读和写。

15.与操作与位操作
#include <stdio.h>
int main(){
int a = 0;
a |= (1<<3);//将a的第3位设置为1
printf("%d\n",a);
a &= ~(1<<3);//将a的第3位设置为0
printf("%d\n",a);
return 0;
}知识点:
- 只要出现置1:或操作
- 只要出现置0:与操作

16.sizeof的使用
#include <stdio.h>
int main(){
int a = 10;
printf("%d\n",a);
printf("%d\n",sizeof(a++));
printf("%d\n",a);
return 0;
}结果为:10,4,10,为什么最后不是11呢?

17.指向地址的指针加一个整数
#include <stdio.h>
int main(){
unsigned char *p1 = (unsigned char *)0x08000010;//指向地址的指针
unsigned long *p2 = (unsigned long *)0x08000010;//指向地址的指针
printf("%#x\n",p1+5);
printf("%#x\n",p2+5);
return 0;
}结果是0x08000015和0x08000024,
- 对于前一个答案我们很清楚,因为一个unsigned char占一个字符,加5则是加5个字符;
- 后一个答案则是加5个long,一个long占4个字符,所以加5个long就是加20个字符,那么应该是0x08000030才对,为什么是0x08000024呢?因为使用的是16进制计算,20的十六进制就是14,所以是0x08000024。
18.volatile关键字
#include <stdio.h>
int squere(volatile int *pt){
//正确写法如下:
//int a = *pt;
//return a*a;
return (*pt)*(*pt);//这样写可能会出错,因为编译器可能会优化代码,认为*pt的值没有改变,所以直接返回上一次的值
}
int main(){
int a = 10;
printf("%d\n",squere(&a));
return 0;
}
19.假设有两个变量a,b,不借助第三个变量交换两个变量的值。
#include <stdio.h>
int main(){
a=2;b=3;
a=a^b;//0010^0011=0001
b=a^b;//0001^0011=0010
a=a^b;//0001^0010=0011
printf("%d,%d\n",a,b);
return 0;
}还可以使用减法的思想:
#include <stdio.h>
int main(){
a=2;b=3;
a=a+b;//a=5
b=a-b;//b=2
a=a-b;//a=3
printf("%d,%d\n",a,b);
return 0;
}20.左移右移运算符和条件运算符的优先级
#include <iostream>
using namespace std;
int main(){
int a = 99;
int b = 100;
cout<<(a>b)?a:b;
return 0;
}结果输出为0,因为条件运算符的优先级低于左移运算符,所以先执行了左移运算符,结果为0。
21.交换地址的高位和地位
#include <stdio.h>
void convert(unsigned int *);
int main(){
unsigned int a;
printf("请输入一个整数:");
scanf("%x",&a);
convert(&a);
printf("转换后的整数为:%x\n",a);
return 0;
}
void convert(unsigned int *a){
unsigned int temp;
temp = *a & 0x0f;
*a &= 0xf0;
*a = (*a >> 4) | (temp << 4);
}
结果:
```c
请输入一个整数:0x3A
转换后的整数为:0xa322.一级指针和二级指针

23.如果从数组x复制50个字节到数组y,最简单的方法是什么?
#include <stdio.h>
int main(){
char x[50] = "hello world";
char y[50];
memcpy(y,x,50);
printf("%s\n",y);
return 0;
}memcpy 是一个用于在内存中复制数据的函数,定义在 C 标准库中的 <string.h> 头文件中。它的原型如下:
void *memcpy(void *dest, const void *src, size_t n);参数说明
- dest:指向目标内存位置的指针,即数据将被复制到的位置。
- src:指向源内存位置的指针,即数据将从哪里复制。
- n:要复制的字节数。
返回值
返回指向目标内存位置的指针 dest。
用途
memcpy 函数主要用于在内存中复制数据块,常用于以下场景:
- 字符串复制:复制字符串内容。
- 结构体复制:复制结构体数据。
- 数组复制:复制数组元素。
使用注意事项
- 目标内存必须足够大:确保目标内存区域足够大,能够容纳从源内存复制过来的数据,否则会导致缓冲区溢出。
- 源和目标内存不能重叠:如果源和目标内存区域有重叠,memcpy 的行为是未定义的。如果需要处理重叠的情况,可以使用 memmove 函数。
- 类型安全:memcpy 是一个低级别的内存操作函数,不进行类型检查,因此在使用时需要确保数据类型的一致性。
- 性能考虑:memcpy 通常比手动循环复制更高效,因为它利用了底层硬件的优化。
24.将字符数字转为整形数字
思路:使用指针取出字符串中的每个字符,然后减去字符'0’的ASCII码值,即可得到对应的整形数字。 编写一个函数来实现这个操作,函数原型如下:
int ascii_to_integer(const char *str);其中,str 是一个指向字符数字字符串的指针,函数返回对应的整形数字。
#include <stdio.h>
int ascii_to_integer(const char *str){
int digit = 0;
while(*str >= '0' && *str <= '9'){
digit = digit * 10 + (*str - '0');
str++;
}
if(*str != '\0')
return 0;
return digit;
}
int main(int argc, char *argv[]){
// int digit = ascii_to_integer(argv[1]);//在Linux中可以尝试这样写
char str[100];
printf("请输入一串数字字符:");
scanf("%s",str);
printf("The digit is: %d\n", ascii_to_integer(str));
return 0;
}24.百钱买百鸡问题
解题思路如下图:

#include <stdio.h>
int main(){
int x, y, z;
int t;
for(t = 0;t<=4;t++){
x = 4 * t;
y = 25 - 7 * t;
z = 75 + 3 * t;
printf("cock:%d,hen:%d,chicken:%d-----sum:%d\n",x,y,z,x+y+z);
}
return 0;
}
结果:
cock:0,hen:25,chicken:75-----sum:100
cock:4,hen:18,chicken:78-----sum:100
cock:8,hen:11,chicken:81-----sum:100
cock:12,hen:4,chicken:84-----sum:10025.*和++运算符优先级 二者的运算优先级是一样的。
#include <stdio.h>
int main(){
int arr[10] = {1,2,3,4,5,6,7,8,9};
int *p = arr;
for (int i = 0; i < 3; i++){
printf("%d",*p++);
}
p = arr;
printf("\n-------------------------------------------\n");
for (int i = 0; i < 3; i++){
printf("%d",*++p);
}
p = arr;
printf("\n-------------------------------------------\n");
for (int i = 0; i < 3; i++){
printf("%d",++(*p));
}
return 0;
}26.函数指针类型

27.编写函数实现整数四舍五入 思路:对于正数我们可以加0.5,然后取整; 对于负数则减去0.5,然后取整。
#include <stdio.h>
int round(int num){
if(num >= 0){
return num + 0.5;
}else{
return num - 0.5;
}
}
int main(){
int num = 3.6;
printf("round(%d) = %d\n",num,round(num));
return 0;
}28.下图代码运行结果
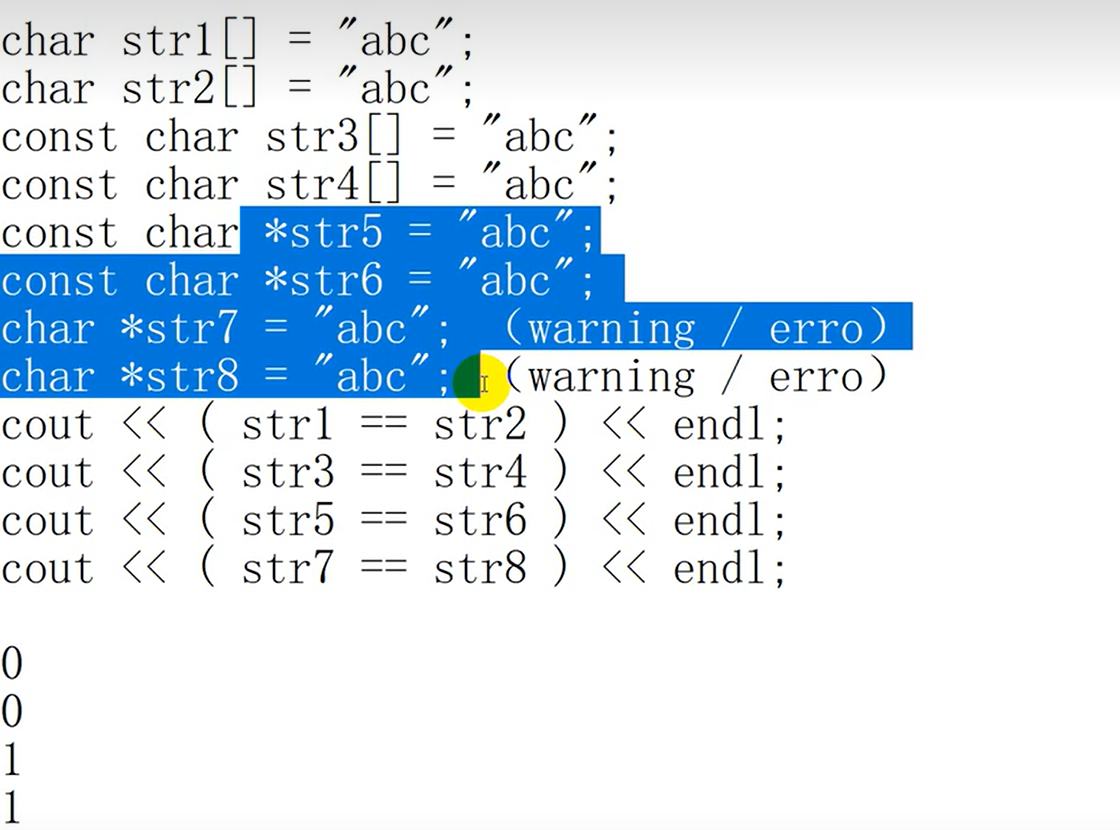
29.函数指针数组

20.C++面试
- 1.网络编程
网络编程
网络原理
数据库
C++基础
1.左值引用和右值引用
数据湖结构与算法
20.C++面试 的子部分
1.网络编程
网络编程
网络原理
数据库
C++基础
1.左值引用和右值引用
数据湖结构与算法
1.代码编写规范
如何写一个标准的.h文件
以下内容来自B站。
接下来将以复数的库文件为例来回答这个问题,下面是一段参考复数库文件代码:
class complex
{
private:
/* data */
double re,im;
friend complex& __doapl (complex*,const complex&);
public:
complex (double r,double i)
:re(r),im(i) //这是一个构造函数,这种写法意思是初始化变量
{};
complex& operator += (complex operator&);
double read () const {return re;} //这里需要加const 意思就是修饰函数的返回值,不允许改变返回值类型
double imag () const {return im;}
};构造函数的特性
这一点需要关注下面的代码:
complex (double r,double i)
:re(r),im(i) //这是一个构造函数,这种写法意思是初始化变量
{};关于const修饰符
如上面说到的,函数返回最好是加const,这样可以应付下面情况的发生。
const的使用
double read () const {return re;}
double imag () const {return im;}此时做如下两种使用都是正确的
complex com1(1,2);
cout<<com1.real()<<endl; const complex com1(1,2);
cout<<com1.real()<<endl; double read () {return re;}
double imag () {return im;}此时做如下两种使用只有第一种可以被执行,第二种会报错。
complex com1(1,2);
cout<<com1.real()<<endl; const complex com1(1,2);
cout<<com1.real()<<endl;函数传递和返回值的两种方式
pass by values:传值。在传输的事单字节或者字节数较少的情况下使用,比如传一个字符。
pass by reference:传引用。在C++中引用的底层逻辑就是传指针,也就是类似穿了地址,也就是只传输4个字节, 在这种情况下你可以使用const修饰符,迫使函数不能修改值,如果希望函数对值进行处理则可以不加
void re(const classname& cl){};//加了const
void re(classname cl){};//没有加const
对于返回值,我们可以返回值,也可以返回引用,但什么情况下返回的是引用呢?
在设计类中的函数时,可以先考虑返回类型适不适合引用,如果返回的是已经存在的地址,那么可以选择返回类型为引用,否则不使用。
inline complex&
__ap(complex * this ,const complex & c){
this->re += c.re;
this->im += c.im;
return *this;
}向上面的函数就是使用了引用返回。
操作符重载-1:成员函数

操作符重载-2:非成员函数
假设现在要计算复数的加减,如下:
complex com1(1,0);
complex com2(2,9);
complex com3;
com3 = com1 + com2;
com3 = com1 + 2;
com3 = 0 + com2;
……对于这段代码在库文件中,要对加法做非成员函数重载,以应付 不同的情况。
接下来在考虑一个问题,就是如果我们只是做cout<<com1;那么对于«函数返回值可以是void类,但是如果我们做的是cout<<com1<<com2<<endl;
这样的操作返回类型为void类型,那么当运行cout<<com1后就无法运行<<com2<<endl的代码.
很显然要让代码继续运行,我们还需要返回iostream类型,而且使用return by reference返回方法,也就是返回引用。如下图:

小结
通过以上的简单讲解,我们可以总结一下,再写一个类的时候,我们需要注意以下几点:
- 确定类的数据并写在private中;
- 对于构造函数要善于使用初始化数据方法;
- 对于函数要想一想,返回类型是否可以改变,要不要写const;
- 对于函数类型和返回值,要传值还是传引用,要返回值还是返回引用。
是否返回引用最最好的判断标准就是,值在经过函数运算后存储在函数外,或说是一个以存在的存储地址,否则不返回引用
接下来通过学习string.h库,进一步了解指针的使用
一般有指针的类需要写三个特殊函数拷贝构造、拷贝析构、拷贝赋值,
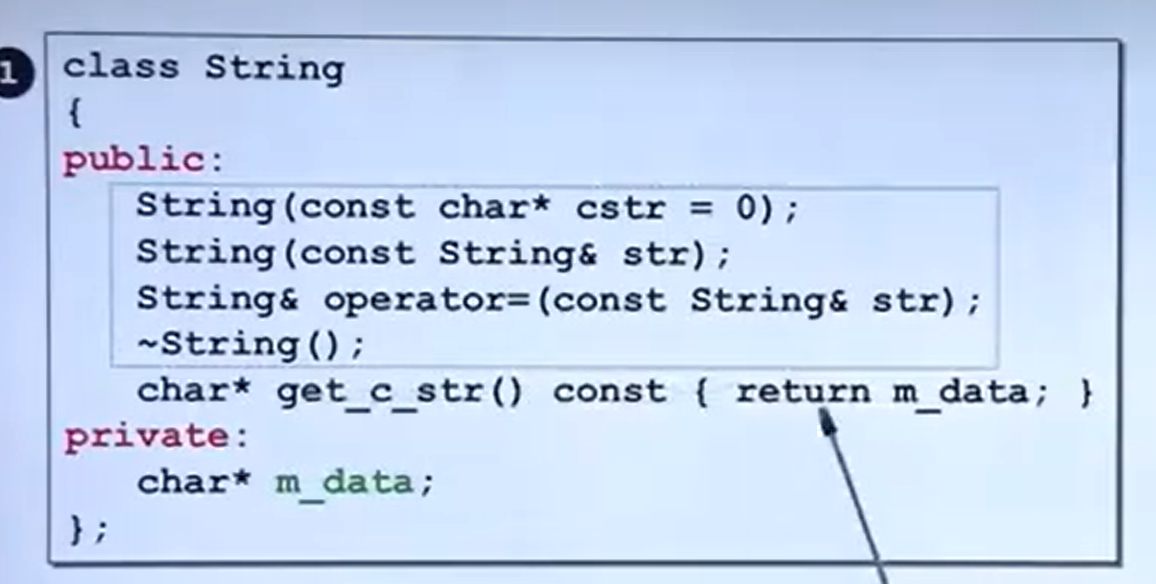
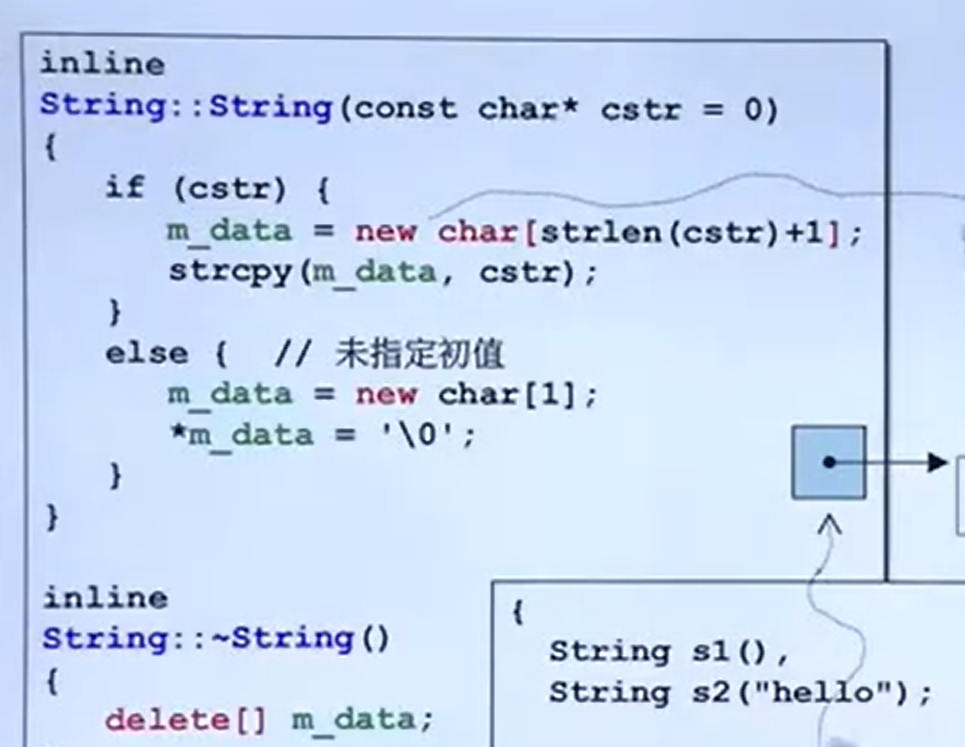

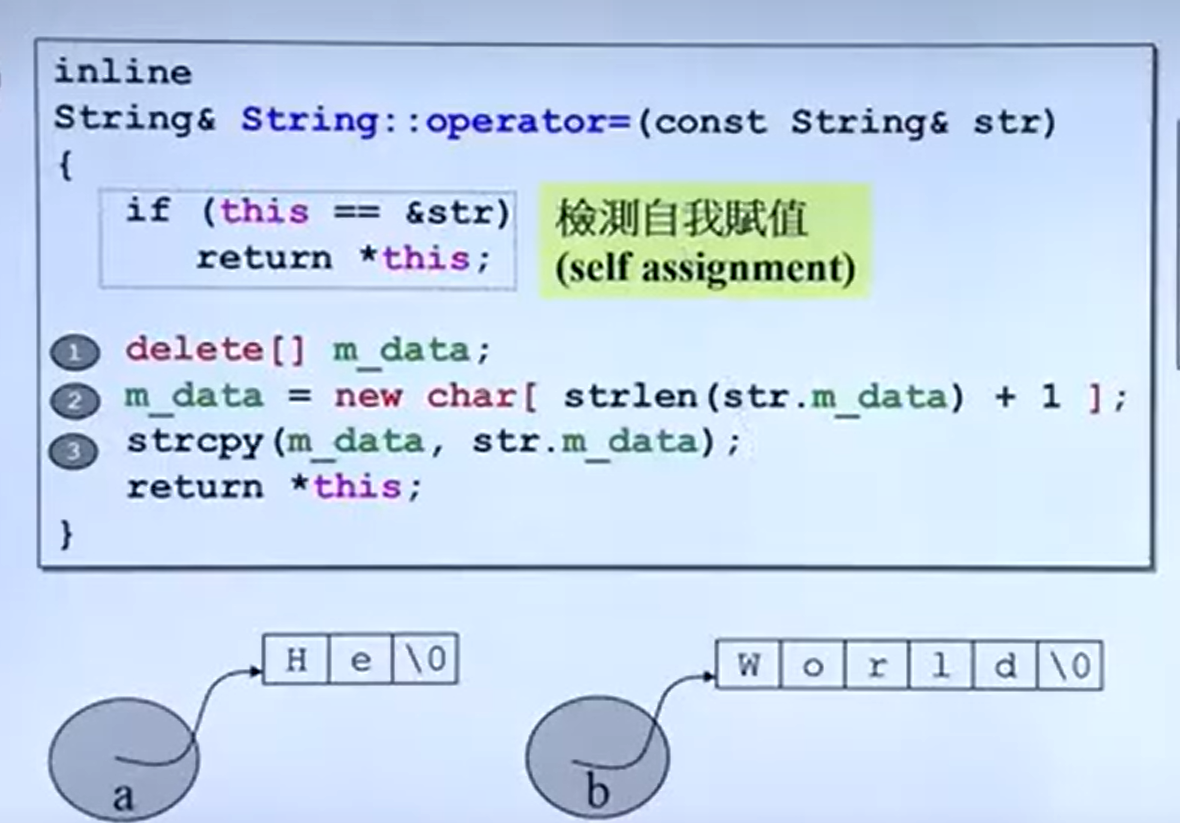
有时候还需要用到new 和 delete。
stack(栈)和heap(堆)
如下代码:
class String{……};
……
{
String str("hello");
String str1 = new String();
……
}上面的{}内的代码就是存储在stack中,而经过new的变量存在heap中;
stack object 的生命周期
在{}内的代码执行结束后,自动调用析构函数将变量清理掉,如下代码,
class String{……};
……
{
String str("hello");
……
}static local object 的生命周期
添加关键字static的变量成为静态变量,在作用于如下面代码的{}结束后不会被析构函数清理掉, 变量会存储直到程序结束。
class String{……};
……
{
static String str("hello");
……
}global objects 生命周期
全局变量在程序接收后才会被清理掉。
class String{……};
String str("hello");
……
{
……
}调用new和delete的过程
在使用new的地方需要使用delete清理内存,防止内存泄露。
调用new过程:
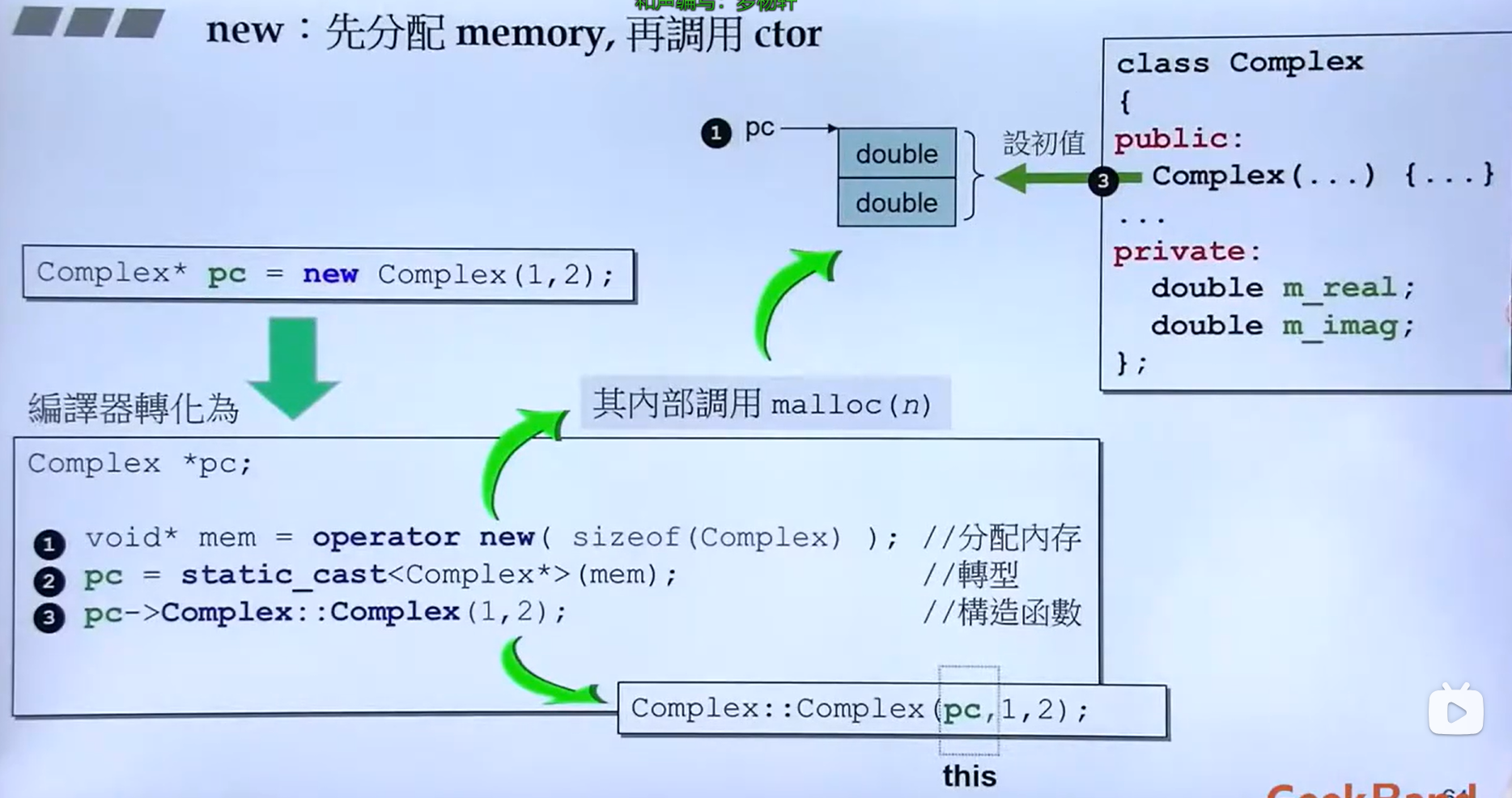
调用delete的过程:
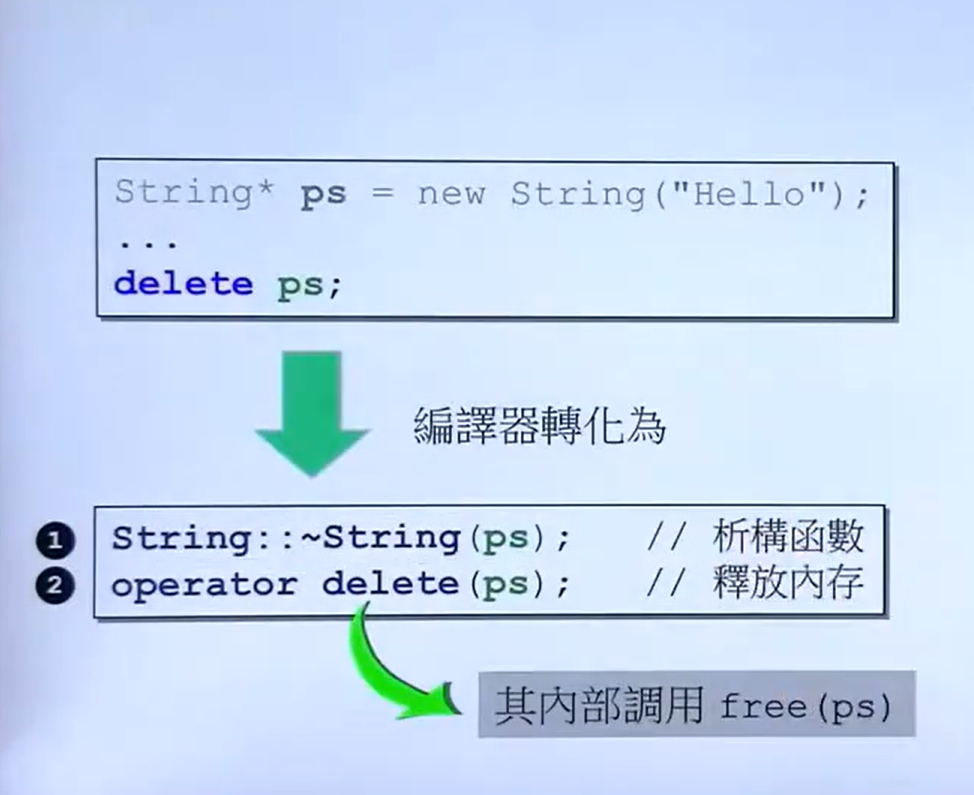
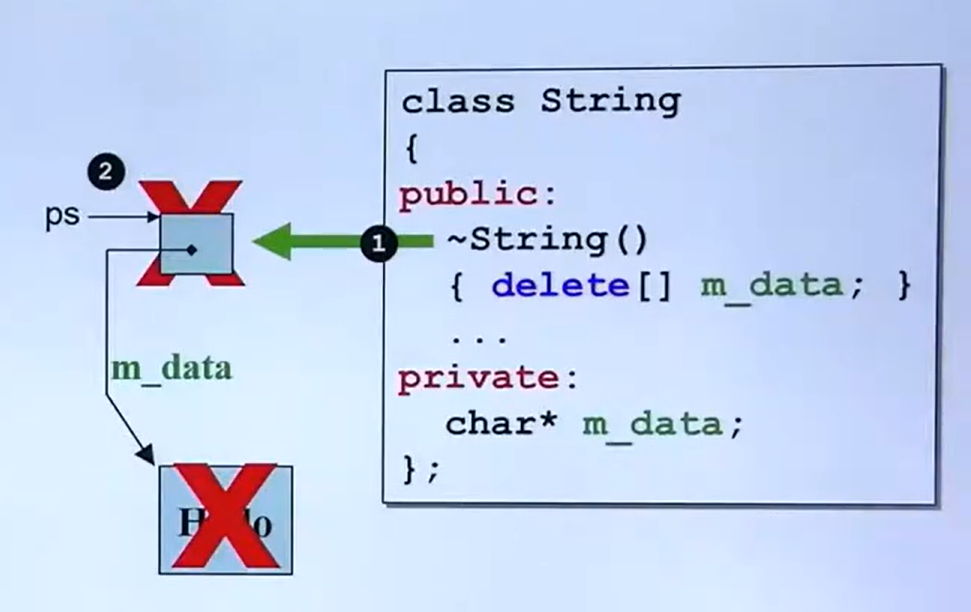
代码 分配内存大小左图是调试模式下的内存分配,右图是非调试模式下分配的内存

new与delete的搭配,在删除数组时需要加上[]否则编译器不知道你要删的是数组:
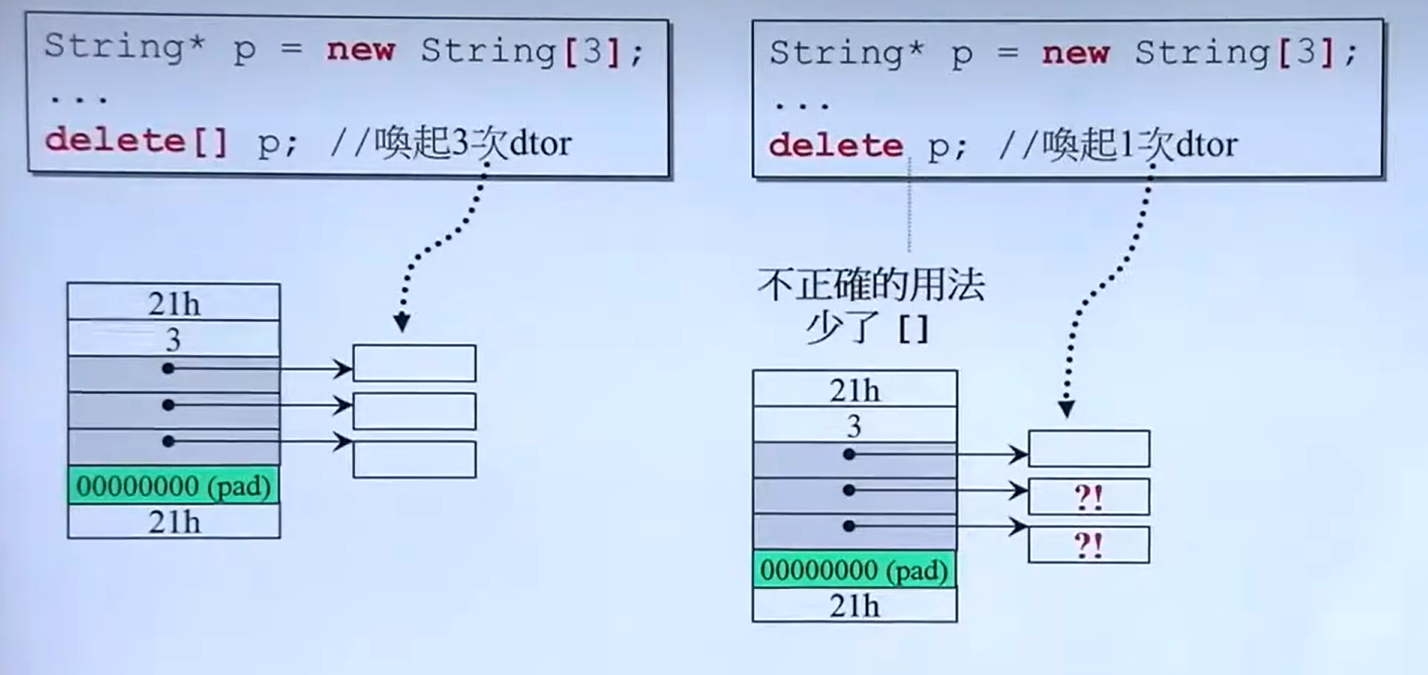
new和delete的补充
对new和delete的重载,用于设计内存管理,如内存池等操作。
重载::new,::delete
重载的函数中,new操作会接收一个大小,该大小由编译器传入,而delete传入的是一个指针,如下图;

如果不想使用类中的new和delete,可以在二者之前加上:,如::new,::delete,这样在调用函数时就不会调用类设计中的new和delete重载,而是全局的。
类中重载的new和delete
//类
class F{
...
public:
void* operate new(size_t);//1
void operate delete(void*,size_t);//2,size_t可不写
...
}
//代码段1的内部操作
try{
void* mem = operate new(size_t);
p = static_cast<F*>(mem);//类型转换
p->F::F();//构造函数
}
//代码段2的内部操作
p->~F();
operate delete(p);
// main函数调用示例
{
F* p = new F();
...
delete p;
}类中重载的new[]和delete[]
代码整体流程与上一个情况类似,区别在于new[]是申请数组内存,在销毁的时候如果不使用delete[]释放内存,delete只会执行一次,导致内存没有完全释放,详细代码如下:
//类
class F{
...
public:
void* operate new(size_t);//1
void operate delete(void*,size_t);//2,size_t可不写
...
}
//代码段1的内部操作
try{
void* mem = operate new(size_t*N + 4);//指针占4个字节
p = static_cast<F*>(mem);//类型转换
p->F::F();//构造函数
}
//代码段2的内部操作
p->~F();//析构函数
operate delete(p);
// main函数调用示例
{
F* p = new F[N];
...
delete[] p;
}new,delete使用示例
using namespace std;
class Foo
{
private:
int _id;//4个字节
long _data;//4个字节
string _str;//40个字节
public:
Foo() :_id(0) { cout << "default ctor.this = " << this << "id: " << _id << endl; };
Foo(int i) :_id(i) { cout << "ctor.this = " << this << "id: " << _id << endl; };
~Foo() { cout << "dtor.this = " << this << "id: " << _id << endl; };
static void* operator new(size_t size);
static void operator delete(void* p, size_t size);
static void* operator new[](size_t size);
static void operator delete[](void* p, size_t size);
};
void* Foo::operator new(size_t size)
{
Foo* p = (Foo*)malloc(size);
cout << "new size = " << size << endl;
return p;
}
void Foo::operator delete(void* p, size_t size)
{
cout << "delete size = " << size << endl;
free(p);
}
void* Foo::operator new[](size_t size)
{
Foo* p = (Foo*)malloc(size);
cout << "new[] size = " << size << endl;
return p;
}
void Foo::operator delete[](void* p, size_t size)
{
cout << "delete[] size = " << size << endl;
free(p);
}运行结果如下:
new size = 48
default ctor.this = 00000191EC67A460id: 0
dtor.this = 00000191EC67A460id: 0
delete size = 48
_____________________________________________
new[] size = 104
default ctor.this = 00000191EC673438id: 0
default ctor.this = 00000191EC673468id: 0
dtor.this = 00000191EC673468id: 0
dtor.this = 00000191EC673438id: 0
delete[] size = 104为什么new[]操作会多出8个字节呢?
我看课程视频,老师说new[]分配的内存块会在最前面存储计数量,占用4个字节,表示数组大小,但是我在电脑上运行会多出8个字节,查阅资料可能与系统、对齐方式、编译器等有关。
对new的分配额外内存
假设分配内存的同时需要额外分配一定的内存,可以参考下面的代码:

小结
对于包含有指针的类,在必要时写上拷贝构造、拷贝赋值、析构函数,如下代码
class String
{
private:
char* m_data;
public:
String(const char* cstr = 0); //构造函数
String(const String& str); //拷贝构造函数
String& operator= (const String& str); //拷贝赋值函数
~String(); //析构函数
char* get_c_str() const {return m_data;}
}; String::~String()
{
delete[] m_data;
} inline
String::String(const char* cstr = 0)
{
if (cstr)
{
m_data = new char[strlen(cstr)+1];
strcpy(m_data, cstr);
}else{
m_data = new char[1];
strcpy(m_data,'\0');
}
} inline
String::String(const String& cstr){
m_data = new char[strlen(cstr.m_data) + 1];
strcpy(m_data, cstr);
} inline
String& String::operator=(const String& str)
{
if(this == &str)
return *this;
delete[] m_data;
m_data = new char[strlen(str.m_data) + 1];
strcpy(m_data, str);
return *this;
}补充内容static
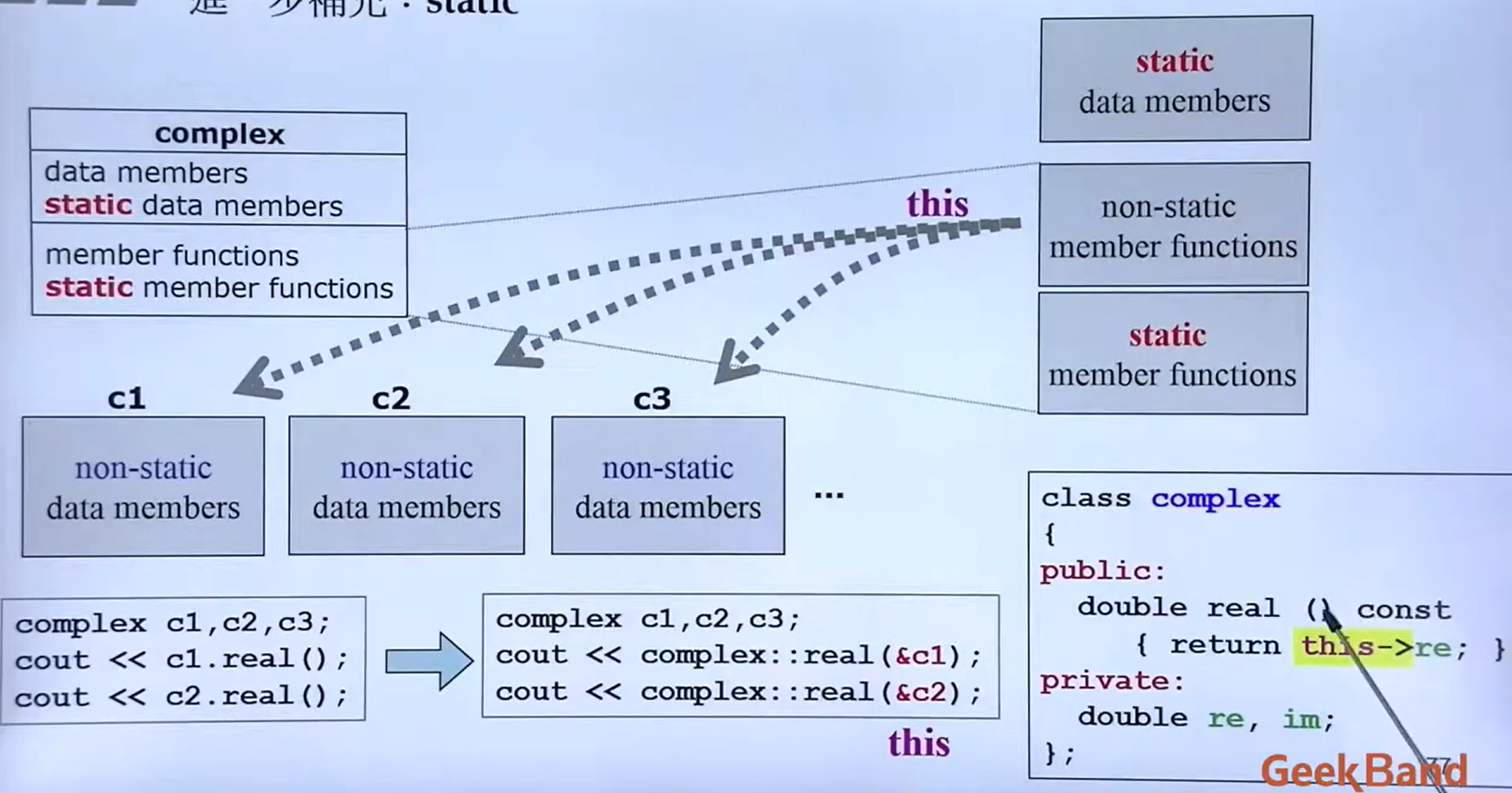
static在private中的使用例子


class template

function template
member template 成员模板
类模板中,还有类模板,通常是对构造函数的操作,如下图:

如下图代码

用意就是当一个指针指向父类时,初始化让他指向子类,那么此时需要实现上图类中的代码。
namespace(命令空间)
使用示例:
using namespace std;
{
……
}使用方法:
#include <iostream>
using namespace std;
int main()
{
cout<<……;
cin<<……;
return 0;
} #include <iostream>
using std::cout;
int main()
{
cout<<……;
std::cin<<……;
return 0;
}或者
#include <iostream>
int main()
{
std::cout<<……;
std::cin<<……;
return 0;
}嵌入式系统设计知识点
基于Cortex-A9微处理器的硬件平台
RISC和CISC
RISC是精简指令集计算机,CISC是复杂指令集计算机
RISC(精简指令集计算机,Reduced Instruction Set Computer)和CISC(复杂指令集计算机,Complex Instruction Set Computer)是两种不同的计算机架构设计理念,它们在指令集的复杂性、指令执行方式、硬件实现等方面有所区别。以下是RISC和CISC的主要特点及其区别:
- RISC(精简指令集计算机)
- 指令集简单:RISC架构拥有较少的指令,通常每个指令执行一个简单的操作。
- 指令执行快速:由于指令简单,大多数RISC指令可以在单个时钟周期内完成。
- 寄存器丰富:RISC架构通常具有更多的寄存器,以减少对内存的访问次数。
- 流水线执行:RISC处理器设计易于实现流水线技术,提高指令吞吐率。
- 编译器优化:RISC架构依赖编译器将复杂操作转换为一系列简单的指令。
- CISC(复杂指令集计算机)
- 指令集复杂:CISC架构拥有大量的指令,包括一些执行复杂操作的指令。
- 指令执行较慢:CISC指令可能需要多个时钟周期来完成。
- 寄存器较少:CISC架构通常具有较少的寄存器,更多依赖内存访问。
- 微指令执行:CISC处理器可能使用微指令(microcode)来实现复杂指令。
- 硬件复杂性:CISC处理器的硬件设计相对复杂,以支持广泛的指令集。
区别
- 指令集大小:RISC的指令集较小,CISC的指令集较大。
- 指令复杂性:RISC指令简单,CISC指令复杂。
- 执行速度:RISC指令通常执行更快,CISC指令执行可能较慢。
- 硬件设计:RISC处理器设计相对简单,CISC处理器设计复杂。
- 内存访问:RISC架构倾向于减少内存访问,CISC架构可能更频繁地访问内存。
- 依赖编译器:RISC架构更依赖编译器优化,CISC架构则在硬件层面提供复杂操作。
ARM处理器支持的基本数据类型
数据类型:字、半字、字节。
说明:
- 一个字节占8位,半个字节占16位,一个字占32位;
- 在存储数据时,字要按照4个字节来存储,所以每一次存时地址都加4,地址末位是00,例如0x13FFFFF8,0x13FFFFFC,
- 在存储数据时,半字要按照2个字节来存,所以每一次存时地址都加2,地址末位是0,例如0x13FFFFF4,0x13FFFFF6,;
ARM处理器的工作状态
主要有两种状态,主要区别就是执行的指令集位数不同;
- Thumb状态,微处理器执行16位的半字对齐的Thumb指令集,Thumb指令集是从ARM微处理的第四个版本开始增加(v4T);
- ARM状态,微处理器执行32位的字对齐的ARM指令集。
ARM存储格式
-
大端格式:高字节存储在低地址,低字节存储在低地址;
-
小端格式:高字节存在高地址,低字节存储在低地址; 说明:
-
对高字节和低字节可以这样理解,假设有一个32位的地址为0x13FFFFF1,它的高字节是31,也可以理解成最高那一位的下标,31这一位存了0,低字节是0存了1。把这个理解带入上面的大端格式,小端格式。
ARM处理器寄存器
- 共有40个32位的寄存器,其中33个通用寄存器,7个状态寄存器;
- 通用寄存器
- 未分组寄存器(R0-R7);
- 分组寄存器(R8-R14);
- ARM处理器的程序状态寄存器包括:CPSR(当前程序状态寄存器)和SPSR(程序状态备份寄存器)
中断
ARM工作模式
-
用户模式(usr):应用程序执行状态。
-
快速中断模式(fiq):用于高速数据传输或通道处理。
-
外部中断模式(irq):用于通用的外部中断。
-
特权模式(svc):操作系统使用的保护模式。
-
数据访问中止模式(abt):当数据或指令预取终止时进入该模式,可以用于虚拟存储及存储保护。
-
未定义指令中止模式(und):当未定义的指令执行时进入该模式,可用于支持硬件协处理器的软件仿真。
-
系统模式(sys):运行具有特权的操作系统任务。
-
监控模式(mon):可在安全模式与非安全模式之间转换。
-
执行程序什么模式?
-
读指令并执行,读取未定义指令什么模式?
-
遇到特权任务什么模式?
-
遇到中断什么模式?
-
指令执行结束什么模式?
3级、5级流水线
- 3级流水线指令可以分解成取指令、编译、执行;
- 5级流水线指令可以分解成取指令、编译、执行、缓冲、写回。
程序状态寄存器
-
CPSR中的[31:27]为条件标志位,具体含义如下:
- N:符号标志位。当用两个补码表示的带符号数进行运算时,N=1表示运算的结果为负数;N=0表示运算的结果为正数或零。
- Z:结果是否为0的标志。Z=1,表示运算结果为0;Z=0,表示运算结果为非0。
- C:进位或借位标志位。加法运算结果产生了借位时C=1,减法运算产生了借位时C=1,否则为0;包含移位操作的非加/减运算指令,C为移出值的最后一位;其他运算指令,C的值通常不变。
- V:溢出标志位。对于加减法运算指令,V=1表示符号位溢出,其它指令的影响V位。
-
CPSR中的[7:0]为控制位,具体含义如下:
- I:IRQ中断使能位;
- F:FIQ中断使能位;
- T:处理器运行状态控制位;
- M[4:0]:运行模式位。
-
其它标志位。
ARM指令集条件域
- EQ:相等,(CPSR)Z=1;
- GT:大于,Z=0&&N=Z;
- TF:小于等于,Z=1||N=Z;
寻址指令
数据处理指令
- RSB 逆向减法,例如:
RSB Rd Rn op2 ;op2-Rn赋值给Rd-
MUL 32位乘法,
-
CMP 比较,例如
CMP Rn op2 ;Rn-op2-
MOV指令:它的传送指令只能是把一个寄存器的值(要能用立即数表示)赋给另一个寄存器,或者将一个常量赋给寄存器,将后边的量赋给前边的量
-
ADD指令:ADD指令用于把两个操作数相加,并将结果存放到目的寄存器中。
-
SUB指令:SUB指令用于把操作数1减去操作数2,并将结果存放到目的寄存器中
SUB r0, r1, r2 ; r0 = r1 - r2
SUB r0, r1, #256
SUB r0, r2, r3, LSL#1 ; r0 = r2 - (r3 << 1)- LDR指令:LDR指令用于从存储器中将一个32位的字数据传送到目的寄存器中.
用法1: LDR r0, =0x20000000 用法2: LDR r0, =0x30000000
- STR指令:STR指令用于从源寄存器中将一个32位的字数据传送到存储器中。即:将前边的量赋值给后边的量。
STR r0,[r1] ; 将r0中的字数据写入以r1为地址的存储器中
STR r0,[r1], #8 ; 将r0中的字数据写入以r1为地址的存储器中,并将新地址r1+8写入r1。
STR r0,[r1, #8] ; 将r0中的字数据写入以r1+8为地址的存储器中。跳转指令
案例1
CMP R0, #0
MOVEQ R1, #0
MOVGT R1, #1
解:CMP R0, #0 ; 将R0的值减去0,并根据结果设置CPSR的标志位
MOVEQ R1, #0 ; 若R0等于0,Z=1,则将立即数0装入到R1
MOVGT R1, #1 ; 若R0大于0,Z=0,N=V,则将立即数1装入到R1程序实现的功能是判断R0的值与0的关系,将结果装入R1,若R0=0则R1=0,若R0>0则R1=1.用C语言描述如下。 设R0对应变量a,R1对应变量b,
if(a==0)
b=0;
else if(a>0)
b=1;
案例2
对程序各条指令进行注释,最后分析整个程序的功能。
AREA Example1,CODE,READONLY ; 声明代码段Example1
ENTRY ; 标识程序入口
CODE32 ; 声明32位ARM指令
START ; 标号/标签
MOV R0, #0 ; 设置参数,R0=0
MOV R1, #10 ; 设置参数,R1=10
LOOP ; 标号/标签
BL ADD_SUB ; 调用子程序ADD_SUB
B LOOP ; 跳转到LOOP
ADD_SUB ; 标号/标签
ADDS R0, R0, R1 ; R0 = R0 + R1,并根据结果设置CPSR的标志位
MOV PC, LR ; 子程序返回,PC=LR
END ; 声明文件结束整个程序的功能:程序实现了一个死循环,每次循环R0都增加10。
LInux编程基础
GCC编译的4个过程的主要功能
- 预编译:主要功能是读取源文件,并对头文件预编译语句和一些特殊符号进行分析和处理;
- 编译:主要包括检查代码语法和将预编译后的文件转换成汇编语言;
- 汇编:主要的功能是将汇编语言的代码编程目标文件;(机器代码,0和1)
- 连接:主要功能是连接代码,生成可执行文件。
简述Make工具和Makefile的基本结构
Make又叫工程管理工具,即管理较多的工程文件。
主要的功能:
- 通过Makefile文件来描述源程序之间相互依赖的关系,并自动完成维护编译工作;
- 能够根据文件的时间戳发现更新的文件,可以减少编译工作;
基本结构:
target : dependency
<tab 键> commandtarget:目标; dependency:依赖关系 command:命令
Makefile变量
- 用户自定义变量
- 预定义变量
- 自动变量
后两个是系统的变量,是Makefile文件常用的变量,其中有部分变量用户可以修改。
预定义变量
需要记住两个比较重要且常用的预定义变量,即
- CC:C编译器名称,默认cc
- CFLAGS:C编译器的选项,无默认值
自动变量(又叫系统变量)
- $@ :规则的目标所对应的文件;
- $<:规则中的第一个依赖文件;
- $^:规则中所有依赖的列表,以空格为间隔符。
文件操作编程
C语言库中的fopen、fclose、fwrite、fread等函数。
其实是由操作系统的API函数封装而来,如
- fopen内部其实调用的是open函数,
- fwrite内部调用的是write函数。
用户也可以直接利用Linux系统的API函数来完成文件操作编程
在Linux操作系统下,用C语言实现文件操作可以采用哪两种方法?
在LInux操作系统中,实现文件操作有两种方法,第一种是调用C语言标准库,第二种是通过Linux系统调用实现。前者独立于操作系统,在任何操作系统下使用C语言标准库函数操作文件,而后者以来于操作系统。
时间编程
- time函数
返回1970.1.1 0时到现在所经历的时间,操作失败返回((time_t)-1)
- gmtime函数 将日历转化为格林威治标准时间,结果存在结构体tm中。
在课堂上老师叫我们使用的并非上面这个函数,而是用localtime(const time_t *timep)这个函数,这个函数可以将日历转为本地时间,具体用法请看综合案例
- gettimeofday函数
获取从今日凌晨到现在的时差并存储在tv中,tz存放当地时区差;
综合案例
(4)编写一个程序,将系统时间以“year-month-day hour:minute:second”格式保存在time.txt文件中。
#include<stdio.h>
#include<string.h>
#include<fcntl.h>
#include<time.h>
#define MAX 40
int main()
{
int fd,n,ret;
char writebuf[MAX];
struct tm *t;
time_t lt;
lt=time(NULL);
t=localtime(<); //将日历时间转化为本地时间
sprintf(writebuf,"%d-%d-%d %d:%d:%d\n",t->tm_year+1900,t->tm_mon+1,t->tm_mday,t->tm_hour,t->tm_min,t->tm_sec); //按指定格式保存时间
/*打开文件,如果文件不存在,则会创建文件*/
fd = open("time.txt", O_RDWR | O_CREAT);
/*向文件写入字符串*/
ret = write(fd, writebuf, strlen(writebuf));
if (ret < 0){
perror("Write Error!"); return 1;
}
else
{
printf("write %d characters!\n", ret);
}
/*关闭时,会自动保存文件*/
close(fd);
}多线程编程
基本用法
使用到pthread_createh头文件,以及libpthread.so和libpthread.a库文件;
- pthread_create函数:创建线程
- pthread_exit函数:退出线程
- pthread_join函数:阻塞线程
互斥锁线程
解决多个线程在一起执行的时候共享数据、资源的问题。在POSIX中有两种线程同步机制,分别为互斥锁和信号量
- pthread_mutex_init:初始化互斥锁
- pthread_mutex_lock:互斥锁上锁
- pthread_mutex_unlock:互斥锁释放
嵌入式开发交叉编译与系统移植
嵌入式软件调试方法
- 实时在线仿真
- 模拟调试
- 软件调试
- 片上调试
引导程序移植
操作系统运行前的一个程序,也就是启动程序。
- BoolLoader工作模式
- 启动加载模式
- 下载模式
- BoolLoader启动过程
- 第一阶段
- 主要依赖CPU的体系结构硬件初始化的代码,通常使用汇编语言编写。
- 这个阶段的功能主要有:
- 基本硬件设备初始化;
- 为第二阶段准备ARM空间;
- 复制BootLoader的第二阶段代码到RAM;
- 设置栈堆;
- 跳转到第二阶段的入口点;
- 第二阶段
- 通常使用C语言完成,以便实现更复杂的功能,使程序具有更好的可读性和可移植性。
- 这一阶段的主要任务是:
- 初始化这一阶段要使用的硬件设备;
- 检测系统内存映射;
- 将内核文件和根目录系统映像文件从Flash读到RAM;
- 为内核设置启动参数,
- 调用内核。
- 第一阶段
常用的启动文件有很多,这里介绍Uboot。
Uboot是一个开源项目,最早是由德国登克斯(DENX)小组的开发,然后发布在网上,许多对这款软件感兴趣的开发人员共同来维护。
BootLoader的核心任务是什么?
启动内核,向内核提供启动参数,完成系统软件的部署功能。
系统加电后执行的第一段代码是什么?
BootLoader(引导程序)是系统上电后运行的第一段代码。
U-Boot命令和环境变量
U-Boot通常支持几十个常用命令,通过这些命令,可以对目标机进行调试,也可以引导Linux内核,还可以擦写Flash完成系统部署等功能。
- 常用命令: print: 通常用于打印信息或变量的值到控制台或终端。
setenv: 设置环境变量。环境变量是在操作系统中存储的配置信息,可以影响程序的行为。
saveenv: 保存环境变量。这个命令通常用于将当前的环境变量设置保存到非易失性存储器,以便在系统重启后保持这些设置。
ping: 网络诊断工具,用于测试主机之间的网络连接是否可达。
tftp: Trivial File Transfer Protocol(简单文件传输协议)的缩写,用于在设备之间传输文件。
boot: 启动系统或加载执行程序。
- 组合命令
- movi read:用来读取iNand到DDR上
- movi write:用来将DDR写到到iNand上
注释:
- 非易失性存储器 iNand
- 动态数据随机存取存储器 DDR
linux内核简介
Linux内核主要功能有:
- 进程管理
- 内存管理
- 文件管理
- 设备管理
- 网络管理
Linux内核源代码非常庞大,它使用目录树结构,内核源码的顶层有许多子目录,分别组织存放各种内核子系统或者文件,如下表:
Linux内核移植
Linux内核支持多种处理器,如果目标机使用的是ARM处理器核,使用的交叉编译工具链是arm-linux-,内核移植时要指定处理器的类型以及使用的交叉编译工具链,简述具体操作方法。
具体操作如下。 打开内核顶层目录下的Makefile文件,在文件中找到如下内容。 ARCH?=$(SUBARCH) CROSS_COMPILE?=$(CONFIG_CROSS_COMPILE:“%”=%) 将找到的以上代码修改为如下内容。 ARCH?=arm CROSS_COMPILE?=arm-none-linux-gnueabi- 其中,ARCH是CPU架构变量;CROSS_COMPILE是交叉编译工具链变量。修改完成后,保存文件退出。
驱动程序
驱动程序的功能
- 对设备初始化和释放
- 数据传输:把数据从内核传送到硬件和从硬件读取数据,读取应用程序传送给设备文件的数据和回送应用程序请求的数据.
- 检测和处理设备出现的错误
Open入口点
对象:字符设备文件; 特点:字符设备文件都需要经过open入口点调用 open子程序功能:为I/O口作必要的准备工作 同一时刻只能有一个程序访问此设备(即设备是独占的),则 open子程序必须设置一些标志以表示设备处于忙碌状态。open子程序的调用格式如下。 int open(char * filename,int acess)
第一个功能中
打开设备是由调用定义在incliude/linux/fs.h中的file_operations结构体中的 open()函数完成的。open()函数主要完成的主要工作:
1.若是首次打开,先初始化 2.增加设备的使用计数 3.检测设备是否异常,及时发现设备相关错误 4.读取设备次设备号。
驱动程序的主要组成部分
- 自动配置和初始化子程序:检测驱动的硬件设备是否正常,能否正常工作
- 服务子程序和中断服务程序:这两者分别是驱动程序的上下两部分。
- 驱动上部分,即设备服务子程序,它是系统调用的结果,并且伴随着用户态向核心态的演变,在此过程中还可以调用与进程运行环境有关的函数,比如 sleep()函数。
- 驱动程序的下半部分,即中断服务子程序
Linux设备分类 (用C表示设备)
- 字符设备
- 块设备
- 网络设备
应用程序操作设备框图
简述驱动程序和应用程序的区别
第一,应用程序一般有一个main函数,并从头到尾执行一个任务;驱动程序没有main函数,它在加载时,通过调用module_init宏,完成驱动设备的初始化和注册工作之后便停止工作,并等待被应用程序调用。
第二,应用程序可以和GLIBC库连接,因此可以包含标准的头文件;驱动程序不能使用标准的C库,因此不能调用所有的C库函数,比如输出函数不能使用printf,只能用内核的printk,包含的头文件只能是内核的头文件,比如Linux/module.h。
第三,驱动程序运行在内核空间(又称内核态)比应用程序执行的优先级要高很多。应用程序则运行在最低级别的用户空间(又称用户态),在这一级别禁止对硬件的直接访问和对内存的未授权访问。
应用程序一般有一个main函数,并从头到尾执行一个任务; 应用程序可以和 GLIBC 库连接,因此可以包含标准的头文件; 驱动程序运行在内核空间(又称内核态),比应用程序执行的优先级要高很多。
ArkTS
数据类型
条件语句

拓展:for in与for of的使用
- for in :遍历得到数组的角标,
- for of :直接得到元素。
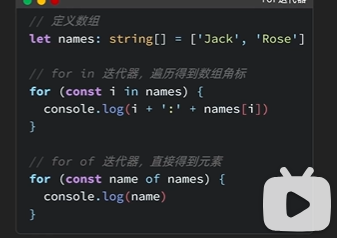
函数
使用function关键字声明函数,
function outname(name:string):void{
console.log('你好'+name+"!")
}
//第二种写法:
let outname = (name:string)=>{
console.log('你好'+name+"!")
}
outname('lucy')ts还提供了一种可传参数和不传参数也执行的函数的操作,写法如下:
let outname = (name:string='张三')=>{
console.log('你好'+name+"!")
}
outname()面向对象
模块的导入导出
提高代码的重复使用
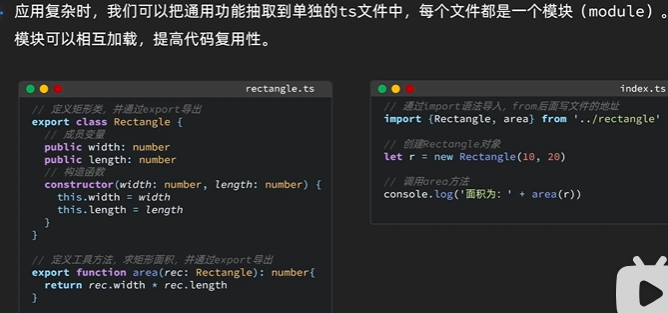
组件的使用
image组件
textinput组件
TextInput({text:this.imagewidth.toFixed(0)})
.width(150)
.backgroundColor('#36D00A')
.type(InputType.Number)
.onChange( values =>{
this.imagewidth = parseInt(values)
})
TextInput({placeholder:'nihao'})
.width(150)
.backgroundColor('#4399')效果如下图:

文本框内输入的值是什么类型的数据呢?
从上面的代码可知是字符型的,此处我们用parseInt将一个变量转换成number类型,又用方法.toFixed()将一个number类型的变量转换成字符串型。
按键组件
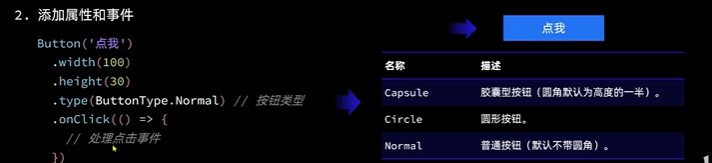
滑动条组件(slider)
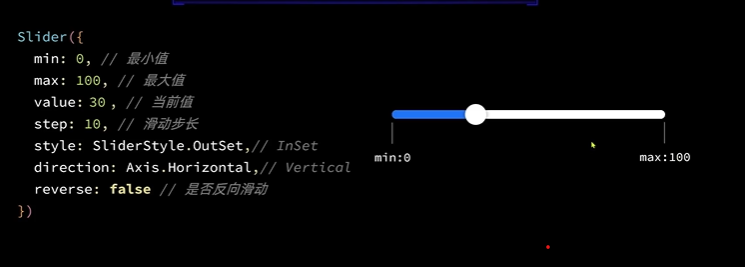
页面布局
线性布局

Row布局与Column布局类似,只是主轴方向不同
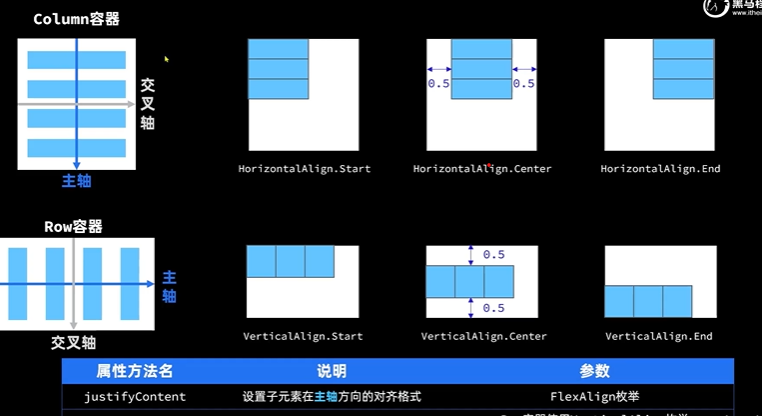
循环控制ForEach
使用router进行页面跳转时用replaceUrl与pushUrl的区别
后者会保留前一页信息,就是跳转后会返回上一页面,而后面的不会跳回上一页
11–t
f–!=11,运行时
电子电路
模拟电子技术知识。
- 模拟电子技术基础笔记
常用半导体器件
本征半导体
-
半导体:介于导体与绝缘体之间的
-
本征半导体:
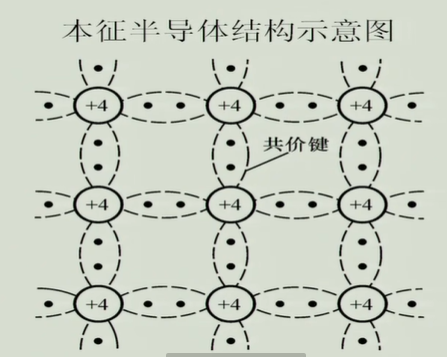
-
载流子 3.1 本征激发
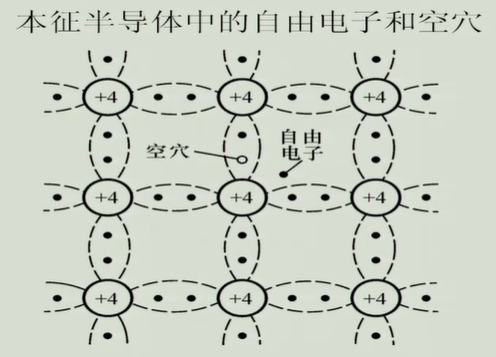 3.2 自由电子,带负电
3.3 空穴,带正电
自由电子和空穴都能到点。
3.4 复合:与本真激发相反的过程
3.2 自由电子,带负电
3.3 空穴,带正电
自由电子和空穴都能到点。
3.4 复合:与本真激发相反的过程
-
电子电路 的子部分
模拟电子技术基础笔记
常用半导体器件
本征半导体
-
半导体:介于导体与绝缘体之间的
-
本征半导体:
-
载流子 3.1 本征激发
3.2 自由电子,带负电
3.3 空穴,带正电
自由电子和空穴都能到点。
3.4 复合:与本真激发相反的过程 -
本征半导体的导电能力与载流子的浓度有关:此时处于动态平衡,本证激发与复合的速度一样。
从工程的角度看,只加热温度让导电能力增加不实际,还好它具有掺杂别的东西让导电能力增加。
杂质半导体
概念
掺杂少量 的杂志元素。
N型半导体
掺杂P元素(5价元素),本征半导体的导电能力增加,自由电子是多子,空穴是少子;
温度对多子影响小,因为多子本身就多,但对少子浓度的影响大,因为少子的量少;
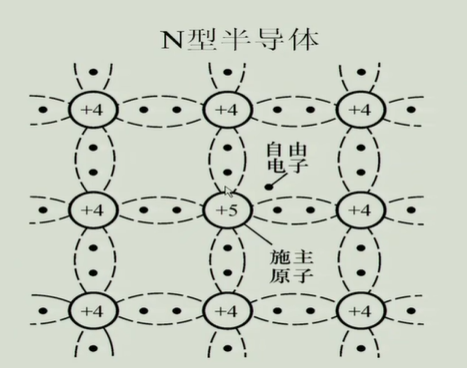
P型半导体
掺杂硼元素(3价元素),本征半导体的导电能力增加,自由电子是少子,空穴是多子;
PN结半导体
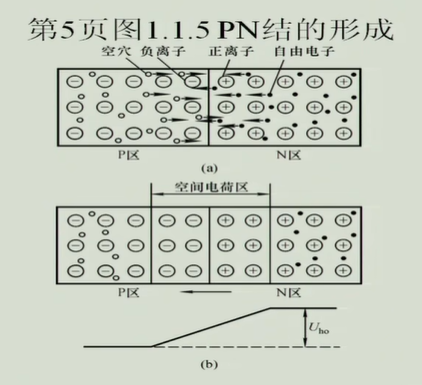
1.扩散运动:在浓度梯度的作用下,浓度高的地方向浓度低的地方扩散;
2.空间电荷区(耗尽层、PN结),这里举个例子,就右边空间电荷区的正电荷而言,从电场线出发,两边平衡我们可以理为正电荷发出的电场阻止了左边的空穴移动,而对于负电荷他也有这样的特性,所以两边达到平衡的状态。
虽然中间有空间电荷区形成势垒(由电压形成)组织了两遍的多子运动,但是这样的势垒能百分之百阻止多子向两边运动吗?
答案是不完全,还是有一小部分的多子冲破避雷向两边运动。下面是一张简单的图。
3.漂移运动:两边少子的运动称之为漂移运动
4.对称结与不对称结:由上面的图可以看出两边宽度一样,原因是掺杂的浓度一样,如果不一样?那么两边就不对称了,这时候称之为不对称结。
加外电压的PN结半导体
加正电压(P流向N,空间电荷区被削弱)
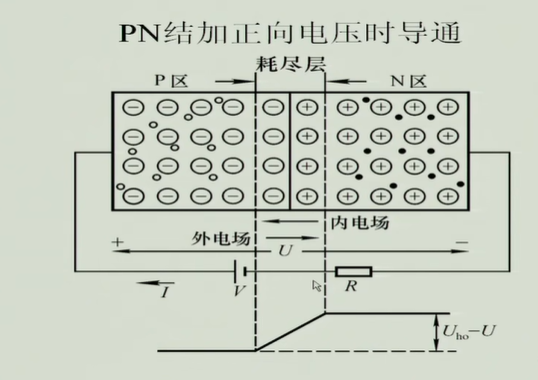
加反向电压(,空间电荷区增加)
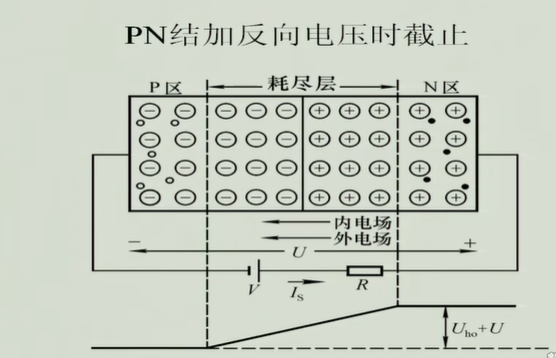
这个时候的漂移运动是增加的,但漂移运动是由少子形成的所以他的影响是很小的,值得注意的是漂移运动对 温度 是很敏感的。
PN结的电流方程
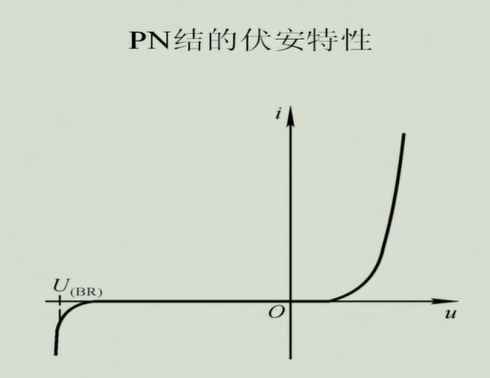
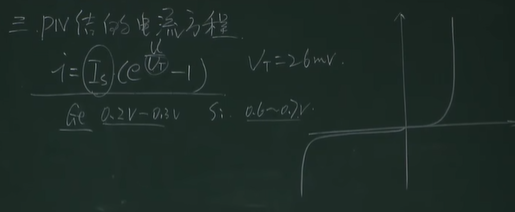 $i=I_s(e^{U/U{_T}}-1),其中V_T=26V$
$i=I_s(e^{U/U{_T}}-1),其中V_T=26V$
锗:0.2-0.3V 硅:0.6-0.7V
特性
- 正向特性
- 反向特性 2.1雪崩击穿(掺杂浓度低,温度越高,击穿电压越高,因为粒子需要加速) 2.2齐纳击穿(掺杂浓度高,温度越高,击穿电压越低,因为)
PN结的电容效应
当正负极两边的电压变化时,中间的电量发生改变;
1.势垒电容
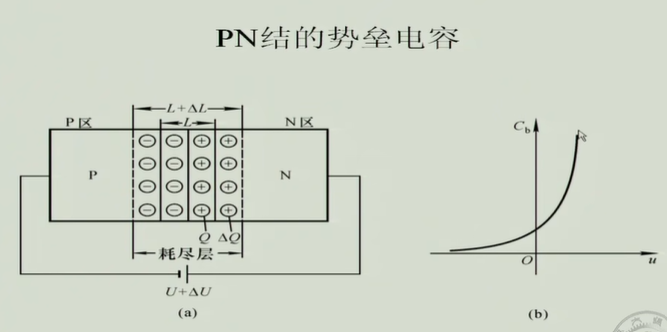
2.扩散电容:非平衡少子形成
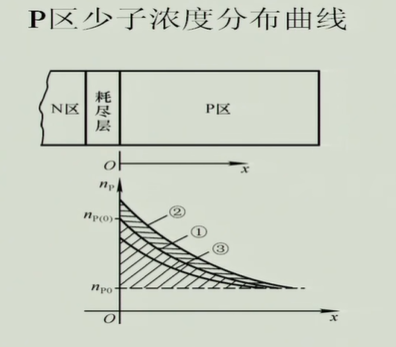
电压增高为2线,浓度增高,电压减小为3,浓度降低;
半导体二极管
常见结构
伏安特性
- 体电阻的存在,电流的PN结小;
- 反向电流大一些;
温度的影响
正向电流:温度升高,本证激发,粒子热运动增加,所以电压固定的时候,温度高的电流可定大,所以曲线往上走;
反向电流:温度升高,对少子影响大,饱和电流增加,所以曲线往下走;
二极管作用
- 单向导电性,规定电流流向,做整流器件;也可以稳压,但一般用反向的稳压
- 反向的饱和电流,简单的温度传感器;
- 反向截止电流,稳压二极管;
问:为什么稳压电路不用正向的电压稳压?
二极管的主要参数
- IF:工作的时候电流的最大流过电流,
- UR:最高反向电压,
- IR:反向电流(未击穿时),
- FM:最高频率(选高频电路的时候需要参考),
二极管的等效电路
 1.上图a为理想的等效电路
1.上图a为理想的等效电路
2.b图为常用的等效模型
上面三张图的 中间没有一杠,这是与普通二极管的区别。
中间没有一杠,这是与普通二极管的区别。
下面我们看二级管的几个应用:
- 整流电路
在上面的这个电路中我们假设交流电10mV,要想在$u_R$中测量出变化的电流那么需要加一个直流电压,将交流电抬高,曲线图如下:
上图B点的电压10mV升到A点,它们的关系是:$U_A=U_B+V$,那么此时就可以测量出$u_R$两端的变化的电流了。具体电路图如下:
最后得到的波形图是去掉Y轴的负半轴的正弦三角函数图像,也就是整流电路。
- 限幅电路
在分析这个电路时,要先判断正向导通和反向截止。
- 当$U_S-U_1<=Uon$的时候截止
- 当$U_S-U_1>=Uon$的时候导通
这时候的三角函数上半边会被割掉如下图:
操作系统
- Linux期末复习
认识Linux
安装Linux
图形界面与命令行
文件管理与常用命令
文件/目录的打包和压缩
gzip压缩文件和gunzip、zcat压缩文件命令
一般压缩解压文件:
例子:gzip [文件名] gunzip [解压文件名]
操作系统 的子部分
Linux期末复习
认识Linux
安装Linux
图形界面与命令行
文件管理与常用命令
文件/目录的打包和压缩
gzip压缩文件和gunzip、zcat压缩文件命令
一般压缩解压文件:
gzip [文件名]
gunzip [解压文件名] [root@localhost stdio]# ls
1.c 2.c 3.c hello.txt
[root@localhost stdio]# gzip hello.txt
[root@localhost stdio]# ls
1.c 2.c 3.c hello.txt.gz
[root@localhost stdio]# gunzip hello.txt.gz
[root@localhost stdio]# ls
1.c 2.c 3.c hello.txt
[root@localhost stdio]# 如果不想删除源文件要怎么做呢?使用如下命令:
gzip -c [文件名] > [压缩文件名.gz]
zcat [解压文件名.gz] >[压缩文件名.gz] [root@localhost stdio]# ls
1.c 2.c 3.c hello.txt
[root@localhost stdio]# gzip -c hello.txt >hello.txt.gz
[root@localhost stdio]# ls
1.c 2.c 3.c hello.txt hello.txt.gz
[root@localhost stdio]# zcat hello.txt.gz >he.txt
[root@localhost stdio]# ls
1.c 2.c 3.c hello.txt hello.txt.gz he.txt
[root@localhost stdio]# 在上面的命令中,zcat [解压文件名.gz] >[压缩文件名.gz] 与 gunzip -c [解压文件名.gz] >[压缩文件名.gz] 作用一样,另外,zcat [文件名]会将文件压缩信息输出在窗口上,即输出在 std。
bzip2压缩文件和bunzip2压缩文件命令
一般压缩解压文件:
bzip2 [文件名]
bunzip2 [解压文件名]
//压缩解压后不会删除原文件
bzip2 -k [文件名]
bunzip2 -k [解压文件名]例子:
[root@localhost stdio]# ls
1.c 2.c 3.c hello.txt
[root@localhost stdio]# bzip2 hello.txt
[root@localhost stdio]# ls
1.c 2.c 3.c hello.txt.bz2
[root@localhost stdio]# bunzip2 hello.txt.bz2
[root@localhost stdio]# ls
1.c 2.c 3.c hello.txt
[root@localhost stdio]# bzip2 -k hello.txt
[root@localhost stdio]# ls
1.c 2.c 3.c hello.txt hello.txt.bz2
[root@localhost stdio]# rm hello.txt
rm:是否删除普通文件 "hello.txt"?y
[root@localhost stdio]# ls
1.c 2.c 3.c hello.txt.bz2
[root@localhost stdio]# bunzip2 -k hello.txt.bz2
[root@localhost stdio]# ls
1.c 2.c 3.c hello.txt hello.txt.bz2
[root@localhost stdio]# tar归档文件命令
在Linux系统中,tar 是一个非常重要的归档工具,用于将一组文件和目录打包到一个单一的.tar文件中。它创建的这种归档文件并不进行压缩,仅仅是将多个文件集合在一起,并保持原始文件的权限、所有权和其他元数据信息。
tar -cvf [文件名]
tar -xvf [解压文件名]然而,为了减少存储空间占用以及在网络上传输时加快速度,通常会结合使用 tar 和压缩工具(如gzip或bzip2)对归档文件进行压缩。这里 -z 或 -j 参数的作用就是启用压缩功能
tar -czvf [文件名]
tar -xzvf [解压文件名]
tar -cjvf [文件名]
tar -xjvf [解压文件名]如果要选择性的归档或压缩、解压某个文件或目录,那么需要加 w,如下:
tar -cwzvf [文件名]
tar -xwzvf [解压文件名]
tar -cwjvf [文件名]
tar -xwjvf [解压文件名]在命令中;
- c(create):表示创建新备份
- z(gzip或gunzip):表示使用gzip指令处理文件
- v(verbose):显示指令执行过程
- f(file):指定备份文件
- w(interactive):对每一步都进行确认
- j:表示使用bzip2、bunzip2指令进行压缩解压
如果加选项 -C (directory),则说明转到指定的目录,命令如下:
[root@localhost ~]# tar -cjvf stdio.tar stdio/
stdio/
stdio/1.c
[root@localhost ~]# tar -xjvf stdio.tar -C st/
stdio/
stdio/1.c
[root@localhost ~]# cd st/
[root@localhost st]# ls
stdio
[root@localhost st]# ls stdio/
1.c
[root@localhost st]# 用户与用户组管理
用户与组文件
用户文件-passwd
存放用户登录用户信息的文件位置:/etc/passwd 文件中域的的格式:
username:passwd:uid:gid:userinfo:home:shell:
例子:
[root@localhost st]# tail -1 /etc/passwd daliu:x:1008:1006::/home/daliu:/bin/bash
/etc/passwdw 文件中域的含义
| 域 | 含义 |
|---|---|
| username | 用户名 |
| password | 登录密码(一般显示的是密码转换后的乱码) |
| uid | 用户ID(0-99一般为系统保留) |
| gid | 用户组ID |
| userinfo | 用户信息 |
| home | 分配该用户的主目录(但位置是人为决定的,自己可以修改) |
| shell | 登录后启动的shell |
一般root用户的UID为0,UID一般是唯一的为的是区分不同的用户,但UID为0的除外,UID为0则说明为超级用户;
创建用户时,系统会分配一个主目录给用户一般在 home 目录下,例如用户user主目录为 /home/user。
用户文件-shadow
Linux系统中的/etc/shadow文件是存放用户密码信息的重要安全文件,也称为“影子口令文件”。它的主要作用是存储用户的加密密码以及与密码相关的属性,以增强系统的安全性。
在早期的Unix/Linux系统中,密码是以明文或简单加密的形式存储在/etc/passwd文件中。为了提高系统的安全性,从1970年代末期开始引入了影子口令的概念,将密码字段从/etc/passwd移出,并存放在只有超级用户(root)可以读取的/etc/shadow文件中,而原来的 /etc/passwd 中的密码字段显示 x ,这就是上面的例子中显示x的原因。
通过这种方式,即使攻击者获取了/etc/shadow文件,由于密码已经被高度加密,直接破解难度大大增加,从而有效提高了系统的密码安全级别。同时,通过对密码策略的设定,还可以实现对用户密码复杂度和有效期的管理。
| 域 | 含义 |
|---|---|
| username | |
| password | |
| min | |
| max | |
| warm | |
| inactive | |
| expire | |
| flag |
下面就举个例子:
[root@localhost st]# tail -1 /etc/passwd daliu:x:1008:1006::/home/daliu:/bin/bash
[root@localhost st]# tail -1 /etc/shadow daliu:$6$f703Izgm$gIA74I6Vyqdjstz3BazhvEUVWfSyelNuv7UKTUtB3cScauSctebqrBIr/KShHnBcWWQideao3aucMrXsO.I6Z/:19694:0:99999:7:::
用户组文件-group
用户组一方面是为了查找用户时更方便,比如查找user用户,你不需要去passwd文件一行一行的查找,你只需要去group文件找到对应的用户组即可。
同样的,用户组也有类似passwd、shadow之和这样的文件,分别为group、gshadow.
/etc/group 文件中域的含义如下:
| 域 | 含义 |
|---|---|
| group_name | 组用户名 |
| group_password | 加密后的用户组口令 |
| group_id | 用户组ID |
| group_members | 以逗号隔开的用户清单 |
/etc/gshadow 文件中域的含义如下:
| 域 | 含义 |
|---|---|
| group_name | 组用户名 |
| group_password | 加密后的用户组口令 |
| group_members | 以逗号隔开的用户清单 |
检验用户与用户组文件之间是否正确
- 检验 /etc/passwd 与 /etc/shadow 文件之间的正确性,使用命令 pwck,当发生错误,两个文件之间信息不对应时,系统会提示对相应项进行修改;
- 检验 /etc/group 与 /etc/gshadow 文件之间的正确性,使用命令 grpck,当发生错误,两个文件之间信息不对应时,系统会提示对相应项进行修改。
相关的命令操作
1.添加用户与用户组———— useradd & groupadd
用法:
- useradd [选项] 登录
- useradd -D
- useradd -D [选项]
值得注意的是,对于选项的-d、-md,加了m表示在/home目录创建用户目录,如果不加,表示该目录已存在不需要再使用m,详细请结合下面的展开内容来开。
用法: groupadd [选项] [组名] ,一般会用到的选项有
- -g: 用户设置组ID;
- -o: 与-g配合使用,设置不唯一的组ID;
- -n: 修改组的名字,如:gpasswd -n [新组名] [旧组名]
2.删除用户与用户组———— userdel & groupdel
- userdel:一般用法就是在后面加要删除的用户,如果加选项-r则会删除主目录文件;
- groupdel:在后面加要删除的用户组
3.修改用户与用户组———— usermod 、passwd & gpasswd
- usermod: 一般就是对问文件中的域进行修改,会加加上选项-u、-g、-s等,最后还得指定用户,用法: usermod [选项] [用户名]。另外,-L(-U) 的作用是对用户的锁定(解锁);
- passwd:一般就是用来修改用户的密码,在登录的是root用户情况下passwd是要指定修改密码的用户的,而如果登录的是用户本身,使用passwd时就不用指定在;
- gpasswd: 用法: gpasswd [选项] [组名] ,一般会用到的选项有
- -a(添加组的用户),
- -d(删除组里的用户),gpasswd -d [用户名] [组名]
- -A(添加组的管理员).
- -g(修改组GID),例如:gpasswd -g [新ID] [组名]
对于usermod的进一步说明,除了上面提到的选项,还有如下选项:
3.登录用户与用户组———— su newgrp
root用户与普通用户之间的切换使用su,如果要切换根目录则需要在su 后加-,即: su - [用户]。
在Linux中,组的登录使用 newgrp ,即 newgrp [组名]。
下面通过一个例子加以理解:
添加一个用户名为15user,且该用户在用户组15group中,设置用户组和用户密码为123,创建一个用户15user2让该用户为用户组管理员,修改user的UID为2024,最后删除所用所建信息。
在上面的例子中,我们使用gpasswd -A来设置用户组管理员。
文件目录和目录权限管理
文件访问权限与用户分类
文件的访问权限
- 读(r):允许读文件的内容
- 写(w):允许向文件中写入数据
- 执行(x):允许将文件作为程序执行
目录的访问权限
- 读(r):允许查看目录中有哪些文件和目录;
- 写(w):允许该在目录下创建(或删除)文件、目录,修改文件名字或者目录名字
- 执行(x):允许访问目录(用 cd 命令进入该目录,并查看目录中可读文件的内容)
用户分类
- 文件所有者(owner):建立文件、目录的用户。
- 同组用户(group):属于同一组群的用户对属于该组群的文件有相同的访问权限。
- 其他用户(other):除了文件所有者、同组用户的其他用户。
我们先用ls -l 查看文件的权限信息:
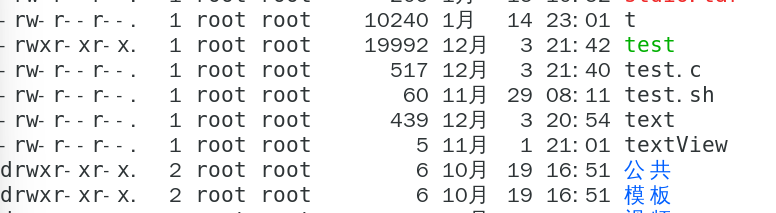
在上面的开头有三段他们分别表示为文件所有者、同组用户、其他用户:

其中的d表示目录。
权限修改
访问权限的表示
- (1)字母表示法(如:rwxr-xr-x)
- (2)数字表示法 (如:755)
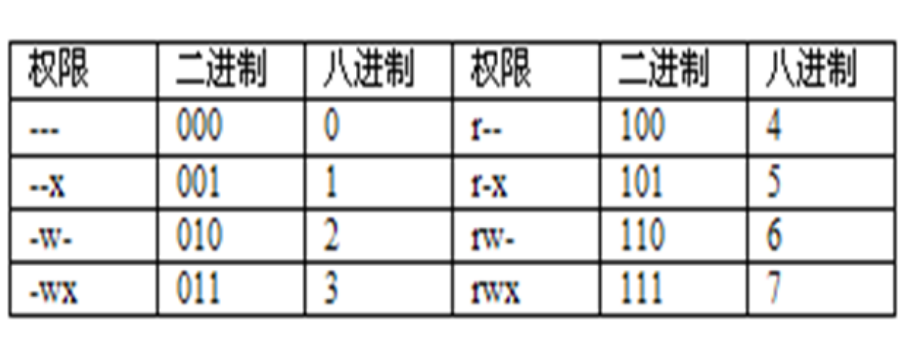
使用数字进行文件权限的划分,其中r=4、w=2、x=1、-=0,这样rwx这组权限就是4+2+1=7,r-x这组权限就是5。
修改权限的命令:chmod
- 命令格式1: chmod $n{_1}n{_2}n{_3}$ <文件|目录>
- 功能:为指定文件或目录修改给定的数值访问权限。
- 选项:$n{_1}n{_2}n{_3}$三位数字表示的文件访问权限。
- 命令格式2: chmod [用户标识] [设定方法] [权限字符] <文件名或目录名〉
- 功能:修改文件或目录的访问权限。
- 选项:
- (1)用户标识:所有者(u)、同组(g)、其他人(o)、所有的人员(a)
- (2)设定方法:+ 增加权限、- 删除权限、= 分配权限,同时删除旧的权限
- (3)权限字符:r(读)、w(写)、x(执行)、u(和所有者的权限相同)、g(和所同组用户的权限相同)、o(和其他用户的权限相同)
修改文件所有者的命令:chown
- 格式:chown [-R] <用户[:组]> <文件或目录>
- 功能:更改属主和组。
- 选项: -R:对目录及其子目录进行递归设置。
例如:chown sjh:sjh result.txt
修改文件所属组群的命令:chgrp
格式:chgrp group file
其中group:组名或组代号
功能: 改变文件或目录组群
例如:chgrp user result.txt
关于chown与chgrp的命令的例子:
修改默认权限的命令:umask
格式:umask [mask]
功能:设置文件或目录的默认权限
注意:系统默认屏蔽的权限为022(umask的默认值为0022),因此新 创建的目录权限就为777-022=755,用字符表示就是rwxr-xr-x,新创 建的普通文件权限为666-022=644,即rw–r–r–。
文件隐藏属性
-
1)查看文件隐藏属性:lsattr
-
2)修改文件隐藏属性:chattr
-
chattr [+-=] [ ai] 文件或目录名称
- a: 当设置a之后,这个文件将只能增加数据,而不能删除也不能修改数据, 必须要为root才能设置这个属性。
- i:不能删除,不能修改,不能改名。必须要为root才能设置这个属性。
文件特殊权限
文件特殊权限有以下三种:
1)SUID:Set UID(只对二进制程序有效,对shell script无效)
例如:ll /usr/bin/passwd
注意:当用户执行passwd命令的时候,需要修改/etc/shadow文件,而该文件普通用户并没有任何权限。
2)SGID:Set GID
例如:ll /usr/bin/locate 注意:当用户执行locate命令的时候,需要读取/var/lib/mlocate/mlocate.db文件。
3)SBIT:Sticky Bit (只对目录有效)
设置方法:
chmod -o+t [指定目录名]
或者
chmod 1777 [指定目录名]对一个目录进行如上设置以后,假设有用户A和B,用户A在该目录下创建的文件只有他自己的root用户可以删,像B这样的其他用户删不了。
软件包管理
接下里介绍两个软件安装的工具,分别是RPM:Red Hat Package Manager(Red Hat软件包管,以及YUM:Yellow dog Dpdater,Modified.
RPM工具不需要网络,需要提前准备好安装包,但是他也有缺点安装的时候如果缺少依赖包你还需要再安装依赖包;
而YUM工具需要再有网的状态下才可以下载,它免去了依赖包提醒,自动将依赖包下载好,较为方便,我跟推荐使用YUM。
RPM工具的使用
1.安装软件包(install)
rpm -ivh rpm软件包全名:
- i:安装一个新的软件包
- v:显示详细信息
- h:显示安装进度条理工具
2.查询已安装的软件包(query)
rpm –qa //查询出本机所有已经安装的软件
rpm –q httpd //查询httpd软件包是否已经安装
rpm -q【i l c d R】 vsftpd
rpm -qf /etc/inittab
查询未安装的软件包:
rpm -qp 【i l c d R】 gconf-editor-2.28.0-3.el6.i686.rpm3.升级与更新(upgrade/freshen)
rpm -Uvh 软件包名称
//原来没有安装过的,直接安装;如果已安装过,则更新至新版
rpm -Fvh 软件包名称
//原来没有安装过的,不安装;如果已安装过,则更新至新版4.卸载RPM包(erase)
rpm -e vsftpd
注意:卸载时只需要给出软件包名称vsftpd,而不需要给出软件包的全部名称信息vsftpd-2.2.2-6.el6.i686.rpm。YUM工具的使用
yum在线升级机制:
- 安装软件 yum install gcc
- 删除软件 yum remove gcc
- 查询软件 yum search gcc
软件包管理:
- 举例一:搜寻与磁盘阵列(raid)相关的软件有哪些? [root@www ~]# yum search raid
- 举例二:找出mdadm这个软件的功能为何? [root@www ~]# yum info mdadm
- 举例三:列出yum 服务器上面提供的所有软件名称。 [root@www ~]# yum list
- 举例四:列出目前服务器上可供本机进行升级的软件有哪些? [root@www ~]# yum list updates
- 举例五:列出提供passwd这个文件的软件有哪些? [root@www ~]# yum provides passwd
yum的软件组功能:
- 查询软件组:yum grouplist(查阅目前容器与本机上面的可用与安装过 的软件群组有哪些?)
yum groupinfo Eclipse(查询Eclipse软件组的相关信息)
- 安装软件组: yum groupinstall Eclipse
- 删除软件组: yum groupremove Eclipse
硬盘分区及格式化
硬盘分区介绍
- 硬盘的分区分为主磁盘分区和扩展磁盘分区。
- 一个硬盘最多可以划分为 4 个主磁盘分区,这时不能再创建扩展分区。
- 一个硬盘中最多只能创建 1个扩展分区 ,扩展分区不能直接使用,必须在扩展分区中再划分出逻辑分区才可以使用。
- 逻辑分区是从5开始的,每多1个分区,数字加1就可以。
硬盘标识
(1)IDE硬盘:hd[a-d]*
hd表示硬盘类型为IDE,中括号中的字母为a、b、c、d中的一个,a是基本盘,b是从盘,是辅助主盘,d是辅助从盘,*指分区,即主分区和扩展分区。
例如:hda1代表第一块IDE硬盘上的第一个分区。hdb5代表第二块IDE硬盘的第一个逻辑分区。
(2)SCSI/SATA硬盘:sd[a-p]*
sd表示SCSI/SATA硬盘。SCSI/SATA的引导盘使用设备文件/dev/sda1、/dev/sda2、/dev/sda3、/dev/sda4作为主分区或者扩展分区,而以/dev/sda5,/dev/sda6等作为逻辑分区。
创建硬盘分区
先使用ls -l /dev |grep ‘sd’查看文件里是否有可用的磁盘,如果没有需要创建一个磁盘,创建步骤:
1.通过虚拟机设置增加一块SCSI硬盘,大小为5G,重启系统。
按照下图点击下一步 根据实际情况输入所需硬盘大小,这里输入5GB 然后点击完成 最后在命令窗口输入reboot重启。
展开
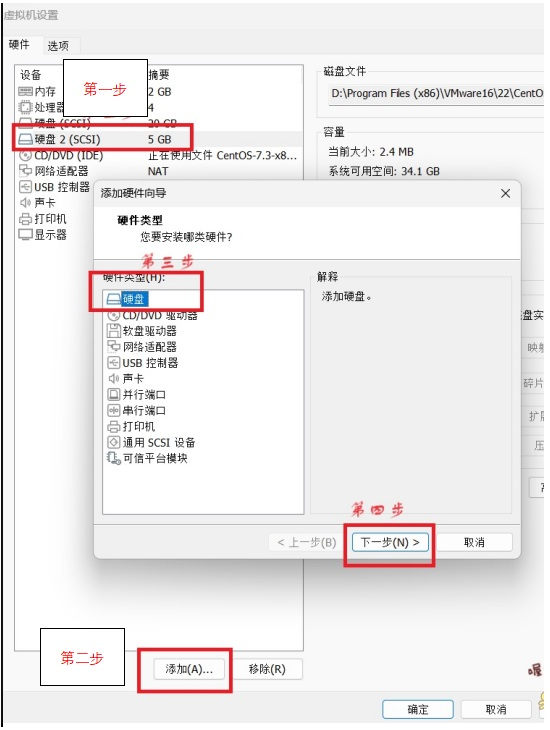
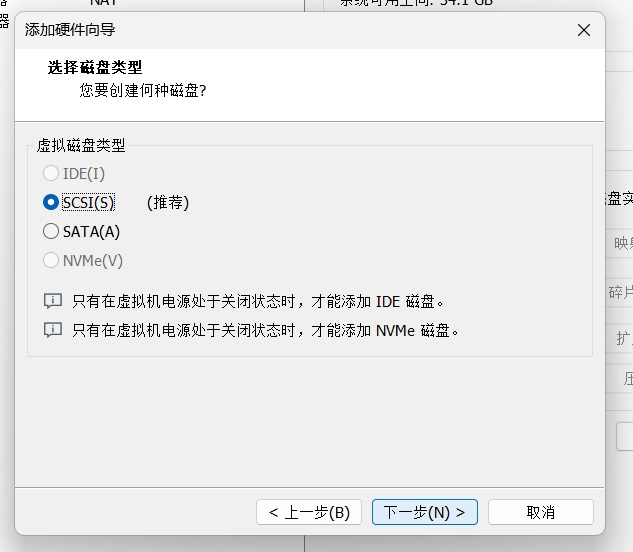
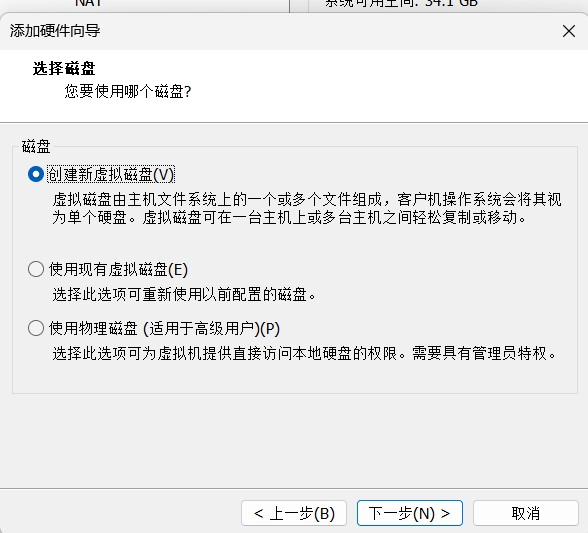
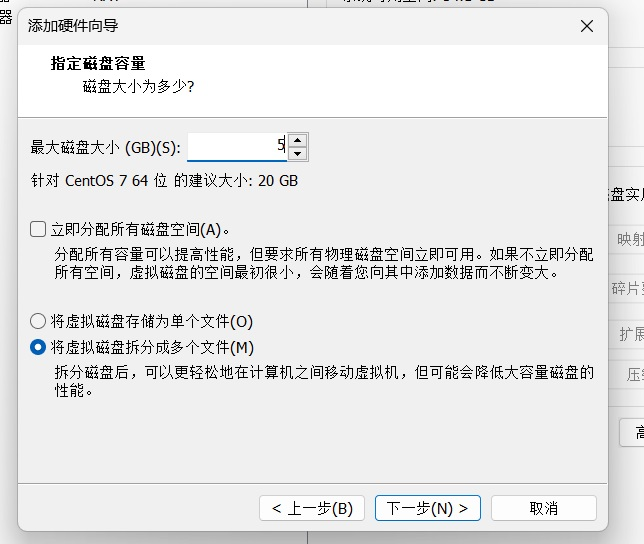
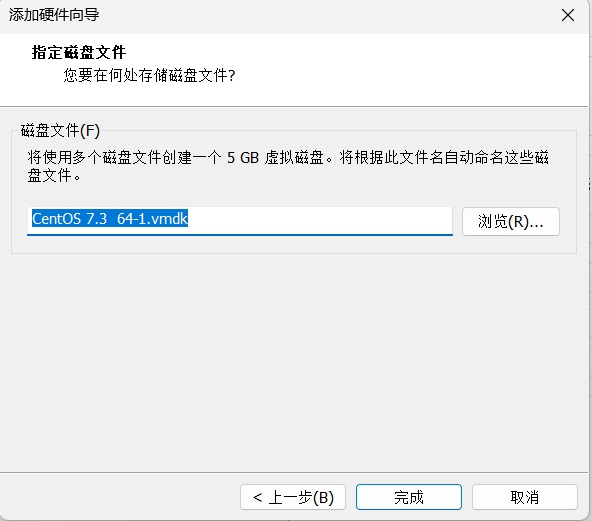
2.将该硬盘分为2个主分区(每个主分区的大小为1G),1个扩展分区(大小为3G),将第2个主分区制作成swap分区。
命令: 3.将扩展分区划出2个逻辑分区(大小分别为1G、2G)。
命令:
查看磁盘情况与磁盘格式化
- (1)查看系统中的新硬盘:
ls /dev/sd* - (2)查看分区:
fdisk –l /dev/sda - (3)创建主分区:
fdisk /dev/sdc - (4)创建扩展分区:输入n,再输入e
- (5)创建逻辑分区: 输入n,再输入l
- (6)修改分区类型
- (7)格式化分区:
mkfs –t ext4 /dev/sdc1还可以写成**mkfs.ext4 /dev/sdc1**- 格式化交换分区略有不同,使用命令 mkswap ,例如:
mkswap dev/sdb2
- (8)磁盘检查命令:
fsck –t ext4 /dev/sdc1badblocks /dev/sdb5
- (9)查看磁盘使用情况
df,或使用df -h输出更易于查看。
上面的-t意思是参数TYPE的意思,后面接ext4()、vfat(FAT32)、ntfs()等,
挂载文件系统:mount
- 1、 挂载硬盘分区:
- 步骤1:mkdir /usr/music
- 步骤2:mount /dev/sdc5 /usr/music
- 2、 挂载光驱:
- 步骤1:mkdir /mnt/cdrom
- 步骤2:mount /dev/cdrom /mnt/cdrom
- 3、 挂载U盘:
- 步骤1:mkdir /mnt/usb
- 步骤2:mount /dev/sdd1 /mnt/usb
- 4、 挂载Windows下的C盘 (FAT32格式):
- 步骤1:mkdir /mnt/dosc
- 步骤2:mount -t vfat /dev/sda1 /mnt/dos
注意: C盘必须已经被格式化为FAT32格式。
显示系统内所有已经挂载的文件系统
mount 不带任何参数执行mount命令,则会显示当前系统中已经挂载的所有的文件系统列表。
卸载设备:umount
格式: umount <设备名或挂载点>
说明:卸载指定的设备,既可以使用设备名也可以使用挂载点。
举例: # umount /dev/cdrom
自动挂载文件系统:/etc/fstab
每条记录由6个字段组成。
1.设备名称 2.设备挂载点 3.文件系统类型 4.挂载选项 5.是否备份 6.自检顺序
如果想要系统自动挂载/dev/sdc5分区,可在/etc/fstab文件添加下面这行:
/dev/sdc5 /usr/music ext4 defaults 0 0
注意:由于fstab文件非常重要,如果这个文件有错误,就可能会造成系统不能正常启动。因此向fstab文件中添加数据时应非常小心。修改完该文件后务必使用mount -a命令测试有没有错误。
磁盘配额
以sdb1为例
第一步:先配置sdb磁盘,然后挂载sdb1磁盘
第二步:使用quotaon /sdb1/生成aquota.group和aquota.user文件
第三步:对用户或用户组进行磁盘限制,例如:edquota -u user1,然后会进入一个文件,文件里的0表示禁用,在里面可以设置创建文件个数或文件大小的软限制、硬限制;
第四步:我们登录user1,在/sdb/目录下创建文件,使用 db if=/dev/zero of=/sdb1/test/ bs=1k count=10这条命令进行测试,这是一个写文件大小的命令,这样可以快速测试文件大小的软限制和硬限制;
第五步:子里面建文件,检验创建文件个数的软限制和硬限制;
第六步: 可以使用repquota -u查看目录的情况;
第七步:关闭磁盘匹配额,quotatoff /sdb1/
Linux编程
AndroidStudio
AndroidStudio
接下来将将介绍AndroidStudio的复习资料,包括AndroidStudio简介、AndroidStudio中 Make Project 、Clean Project 、Rebuild Project 的作用、Run窗口、manifests文件夹(清单文件夹)、java文件夹、res文件夹、Android系统体系结构四层等。
AndroidStudio笔记
这篇文章主要介绍AndroidStudio的使用,以及一些Android开发的基础知识。以及一些开发中遇到的问题和解决方法,除此之外,还会介绍一些开发中常用的工具和技巧。
2-1.Toolbar工具栏
本篇文章主要介绍**Toolbar**工具栏的使用,以及**menu**文件的使用
AndroidStudio 的子部分
AndroidStudio
接下来将将介绍AndroidStudio的复习资料,包括AndroidStudio简介、AndroidStudio中 Make Project 、Clean Project 、Rebuild Project 的作用、Run窗口、manifests文件夹(清单文件夹)、java文件夹、res文件夹、Android系统体系结构四层等。
AndroidStudio简介
Important1.配置Android开发环境:
- 安装JDK: (1)下载JDK (2)配置环境变量;
- 安装Android Studio;
- 安装SDK。
2.自动构建工具Gradle:
Gradle 是以 Groovy 语言为基础,面向Java应用为主,基于DSL(领域特定语言)语法的自动化构建工具。它可以自动化地进行软件构建、测试、发布、部署、软件打包,同时也可以完成项目相关功能,如生成静态网站、生成文档等。另外其集合了Ant的灵活性和强大功能,以及Maven的依赖管理和约定,从而创造了一个更有效的构建方式。凭借Groovy的DSL和创新打包方式,Gradle提供了一个可声明的方式,并在合理默认值的基础上描述所有类型的构建。Gradle目前已被选作许多开源项目的构建系统。
3.Logcat日志输出工具:使用 Logcat 查看日志
Android Studio 中的 Logcat 窗口会实时显示设备日志来帮助您调试应用,例如,使用 Log 类添加到应用的消息、在 Android 上运行的服务发出的消息或系统消息(例如在发生垃圾回收时)。如果应用抛出异常,Logcat 会显示一条消息,后跟相关联的堆栈轨迹,其中包含指向代码行的链接。
4.Android Studio中 Make Project 、Clean Project 、Rebuild Project 的作用
- Make Project:编译Project下所有Module(组件或模块),一般是自上次编译后Project下有更新的文件,增量编译,不生成Apk。
- Clean Project:删除之前编译后的编译文件。部分版本的AS会自动重新编译整个Project,不生成Apk。
- Rebuild Project:先执行Clean操作,删除之前编译的编译文件和可执行文件,然后重新编译新的编译文件,不生成Apk
5.Run窗口:可以输出程序运行过程中出现的错误。 6.manifests文件夹(清单文件夹):Android系统配置文件夹,包含一个AndroidManifest.xml文件(清单文件),可在此文件注册声明
<activity>页面、<service>服务、<receiver>接收器、<provider>提供者或提供程序、<uses-permission>使用权限等;
7.java文件夹:存放Java代码的文件夹,新建项目时默认生成了三个文件夹,com.first.project文件夹用来存放Java文件,这里包含一个名为MainActivity的Java文件,是新建项目时默认生成的。 第二个和第三个文件为测试代码文件夹,不是十分常用。
- res文件夹:存放Android项目的资源文件,包含四个文件夹:
- drawable(图片资源文件夹)、
- layout(布局资源文件夹)、
- mipmap(图片资源文件夹,存放项目图标)、
- values(存放数值资源文件),
- 此外有menu文件(菜单资源文件)。
8.Android系统体系结构四层,从上到下分别是
- 应用程序层
- 应用程序框架层
- 系统运行库层
- Linux内核层 每一层都是用其下面各层所提供的服务。
应用程序层
Android平台包含了许多核心的应用程序,诸如Email客户端、SMS短消息程序、日历、地图、浏览器、联系人等应用程序。这些应用程序都是用Java语言编写的。开发人员可以灵活地根据需求替换这些自带的应用程序或者开发新的应用程序。
应用程序框架
开发者可以完全访问核心应用程序所使用的API框架。该层简化了组件的复用,使得开发人员可以直接使用系统提供的组件来进行快速地开发,也可以通过继承灵活地加以拓展。这些东西包括:
活动管理器(Activity Manager,管理各个应用程序的生命周期以及通常的导航回退功能) 视图系统(View System,构建应用程序的基本组件) 内容提供器(ContentProvider,使得不同的应用程序之间可以存取或者分享数据) 资源管理器(Resource Manager,提供应用程序使用的各种非代码资源,如本地化字符串、图片、布局文件等) 通知管理器(Notification Manager,使应用程序可以在状态栏中显示自定义的提示信息)等。
系统运行库层
包括系统库和Android Runtime,系统库是应用程序框架的支撑,是连接应用程序框架层与Linux内核层的重要纽带。程序在Android Runtime中执行,其运行时分为核心库和Dalvik虚拟机两部分。
Linux内核层
Android基于Linux2.6的内核,其核心系统服务如安全性、内存管理、进程管理、网络协议以及驱动模型都依赖于Linux内核,同时内核层也扮演了介于硬件层和软件栈之间的抽象层的角色。 Linux内核层和系统运行库层之间,从Linux操作系统的角度来看,是内核空间与用户空间的分界线,Linux层运行于内核空间,以上各层运行于用户空间。系统运行库层和应用框架层之间是本地代码层和Java代码层的接口。应用框架层和应用程序层是Android的系统API的接口,对于Android应用程序的开发,应用程序框架层以下的内容是不可见的,仅考虑系统API即可。
9.四大核心组件有:activity(活动或页面)、service(服务)、broadcast receiver(广播接收器)、content provider(内容提供者)
10.Activity介绍Android系统是通过任务栈来管理Activity的。当一个Activity启动时,会把Activity压入到堆栈中,当用户按返回键或者结束掉该Activity时,它会从堆栈中弹出。
11.Android为我们定义了四种加载方式
Standard 加载模式 ——标准模式/默认加载模式
标准模式:系统默认的Activity启动模式,当Intent欲打开Activity时,在该Activity不存在,存在于栈顶和存在于栈底三种情况下都会正常创建Activity,并压入任务栈栈顶;
SingleTop 加载模式 ——栈顶单例模式
栈顶单例模式:当启动一个Activity时,只有当该activity存在任务栈中且为栈顶,Intent才会通过onNewIntent()方法传递给在栈顶Activity实例;其他情况则正常创建Activity并压入任务栈;
SingleTask 加载模式 ——栈内单例模式
站内单例模式:当启动一个Activity时,系统会先检查任务栈内是否有该Activity,如果该Activity不存在则正常创建Activity实例,如果存在且在栈底则会将它上面的Activity弹出并销毁,使该Activity置于栈顶再调用onNewIntent()方法;
SingleInstence 加载模式 ——全局单例模式
与SingleTask模式基本一样,只是在这个模式下Activity所处的任务栈中只能有Activity这一个实例,不能有其他的实例。
12.Activity生命周期是指Activity从创建到销毁的过程,在这一过程中,Activity一般处于4种状态,即:Active/Running、Paused、Stop、Killed
(1)Active/Running 此时Activity一定处于屏幕的最前端,用户完全可以看得到,并且可以与用户进行交互。对于Activity栈来说,它处于栈顶; (2)Paused 此时Activity在屏幕上仍然可见,但是它已经失去了焦点,用户不能与之进行交互。暂停状态的Activity是存活的,它仍然维持着其内部状态和信息,但是系统可能会在手机内存极低的情况下杀掉该Activity; (3)Stop 此时Activity在屏幕上完全不能被用户看见,也就是说这个Activity已经完全被其他Activity所遮住。处于停止状态的Activity,系统仍然保留有其内部状态和成员信息,但是它经常会由于手机系统内存被征用而被系统杀死回收; (4)Killed Activity被系统杀死回收或者未启动。
13.为了能够让Android程序了解自身状态的变化,Android系统中具有很多事件回调函数,我们可以重载这些方法来实现自己的操作。Android生命周期的事件回调函数如下:
void onCreate(Bundle savedInstanceState)
void onStart()
void onRestart()
void onResume()
void onPause()
void onStop()
void onDestroy()14.Activity生命周期
15.Fragment必须是依存于Activity而存在,因此Activity的生命周期会直接影响到Fragment的生命周期。图在课本第50页。
由图可以看到Fragment比Activity多了几个额外的生命周期回调函数:
onAttach(Activity):当Fragment与Activity发生关联时调用。从该方法开始,就可以通过Fragment.getActivity方法获取与Fragment关联的窗口对象了,但在该方法中仍然无法操作Fragment中的控件。 onCreateView(LayoutInflater, ViewGroup, Bundle):创建该Fragment的视图。onActivityCreated(Bundle):当Activity的onCreate方法返回时调用。
onDestoryView():与onCreateView相对应,当该Fragment的视图被移除时调用。onDetach():与onAttach相对应,当Fragment与Activity关联被取消时调用。
16.在使用Intent进行Activity之间的跳转时,我们通常有三种Intent跳转方式,即:不带参数的跳转、带参数的跳转以及带返回值的跳转,代码实现可参考实验报告或书本。
17.TextView常用的属性
android:id="@+id/textView1"表示该控件的id,在布局文件中或者代码中被引用
android:textStyle="bold"表示TextView里面的字加粗显示
android:layout_height="wrap_content"表示该控件的高度为其包含内容的高度
android:layout_width="wrap_content"表示该控件的宽度为其包含内容的宽度
android:text="@string/signin" 显示的内容,这里表示存放在string.xml文件中name=signin的文本
android:layout_height="40dip"设置具体的高度
android:textColor="#7089c0"设置文本的颜色
android:textSize="18sp"设置文本的大小
android:gravity="center_vertical"设置文本垂直居中
android:paddingLeft="5dip"设置内边距
android:layout_marginTop="5dip"设置外边距18.LinearLayout线性布局、
- RelativeLayout相对布局、
- FrameLayout帧布局、
- TableLayout表格布局、
- AbsoluteLayout绝对布局
线性布局,是指该容器(LinearLayout)内子控件的摆放方式有两种: 第一种:垂直放置(VERTICAL),相对水平放置来讲,垂直放置就相当于一列,放置的控件或者容器只能在该列中的某个位置,两个控件之间只存在上下方向的关系,不存在其他方向上的关系。当这一列放满后,再添加的控件就至于屏幕之外存在,无法看见。 第二种:水平放置(HORIZONTAL),指的是该容器里面存放的控件或者容器只能以一行的形式出现,放置的控件只能是该行中的某个位置,两个控件或者容器之间只有左右关系没有其他方向上的关系,当放置水平方向满屏时不会自动换行,再放置的控件将在屏幕之外存在,无法看见。 在线性布局中重要的属性值对应表示
android:orientation //设置控件或者容器存放的方式
android:id //设置控件id,方便在使用时找到其引用
android:layout_width //容器的宽度,该值必须设置
android:layout_height //容器的高度,该值必须设置
android:layout_weight //该属性针对其内的子控件,存放在LinearLayout中的控件都有这个属性,用来设置该控件或者容器占父控件或者容器的比例。相对布局,是指利用控件之间的相对位置关系来对布局进行放置。换句话说,在该容器中的控件与其他任何一个控件或者容器(包括父控件)有相对关系。
帧布局,是指该容器内放置的控件或者容器没有上下左右的关系,只有层叠前后的关系。放置在容器内的控件按放置的前后顺序逐一层叠摆放,自然地后面摆放的控件就将前面摆放的控件覆盖了,叠在它的上面了。对于放置前后的关系,在没有设置其他属性之前,Android系统采用的是叠放的原则,即后加入节点的层叠在上面。设置属性android:bringToFront=“true|false”将前面放置的控件提到最前面可见。
表格布局,指该容器是一个表格,放置控件时,控件的位置坐落在表格的某个位置上。其中TableRow是配合TableLayout使用的,目的是为了让TableLayout生成多个列,否则TableLayout中就只能存在一列元素,但可以有多行。
TableLayout的直接父类是LinearLayout,所以其具有LinearLayout的属性,TableLayout中的每一行用TableRow表示,每一列就是TableRow中的个数指定的。TableRow的直接父类是LinearLayout,但是其放置的方式只能水平放置。
绝对布局,是指以屏幕左上角为坐标原点(0,0),控件在容器中的位置以坐标的形式存在,可以随意指定控件的坐标位置,非常灵活。在开发过程中很少使用,原因是屏幕兼容性不好,不便控制两个控件之间的位置。其中控件或者容器放置的位置通过android:layout_x和android:layout_y这两个属性进行设置。
ConstraintLayout约束布局
优点:
ConstraintLayout之所以成为目前Android开发中主流的布局,除了官方建议使用ConstraintLayout外还有以下几个方面的优势 1.功能强大,ConstraintLayout几乎能实现其他布局所有的功能 2.能减少布局层次的嵌套,有性能的优势 3.可视化操作的增强,大部分界面用ConstraintLayout都能通过可视化编辑区域完成
19.对话框(Dialog)是Android系统在Activity或者其他组件运行过程中提供的一种资源消耗很小的提示机制,它可以帮助应用完成一些必要的提示功能,同时还提供一些用户交互的功能,包括简单的提示、等待、选择、展示等功能。操作简单,资源消耗较少。代码实现可参考实验报告或书本
1提示对话框
package com.example.alertdialog;
import android.content.DialogInterface;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.TextView;
import android.widget.Toast;
import androidx.annotation.Nullable;
import androidx.appcompat.app.AlertDialog;
import androidx.appcompat.app.AppCompatActivity;
import java.util.ArrayList;
import java.util.HashMap;
public class MultipleChoiceDialogBox extends AppCompatActivity {
private Button button;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.test);
button = findViewById(R.id.dialog_box_up);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
AlertDialog.Builder builder = new AlertDialog.Builder(MultipleChoiceDialogBox.this);
builder.setTitle("这是一个简单的弹窗");
builder.setIcon(R.mipmap.ic_launcher);
builder.setMessage("你学会了吗?");
builder.setPositiveButton("学会了", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
}
});
builder.setNegativeButton("不会", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
}
});
builder.show();
}
});
}
}2单选对话框
package com.example.alertdialog;
import android.content.DialogInterface;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.TextView;
import android.widget.Toast;
import androidx.annotation.Nullable;
import androidx.appcompat.app.AlertDialog;
import androidx.appcompat.app.AppCompatActivity;
import java.util.ArrayList;
import java.util.HashMap;
public class MultipleChoiceDialogBox extends AppCompatActivity {
private Button button;
private TextView textView;
private String sexx[] ={"男","女"};
private int choiceWitch = 1;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.test);
button = findViewById(R.id.dialog_box_up);
textView=findViewById(R.id.show_dialog_box_text);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
AlertDialog.Builder builder = new AlertDialog.Builder(MultipleChoiceDialogBox.this);
builder.setCancelable(false);
builder.setSingleChoiceItems(sexx, -1, new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
choiceWitch=which;
}
});
builder.setPositiveButton("确定", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
textView.setText(sexx[choiceWitch]);
}
});
builder.setNegativeButton("取消", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
}
});
builder.show();
}
});
}
}3多选对话框
package com.example.gpc.wzxapplicationwu1;
import android.content.DialogInterface;
import android.os.Bundle;
import android.support.annotation.Nullable;
import android.support.v7.app.AlertDialog;
import android.support.v7.app.AppCompatActivity;
import android.view.View;
import android.widget.Button;
import android.widget.TextView;
import java.util.ArrayList;
import java.util.HashMap;
public class AlertDialogActivity extends AppCompatActivity{
private Button button;
private TextView textView;
private String sexx[] ={"a","b","c","d"};
private boolean stu[] = {false,false,false,false};
private int choiceWitch = 1;
private ArrayList<Integer> list = new ArrayList();
private String str = "";
private HashMap<Integer,Integer> map = new HashMap<>();
@Override
protected void onCreate(@Nullable final Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.alert_dialog);
textView = findViewById(R.id.alert_dialog_textview);
button = findViewById(R.id.alert_dialog_button);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
AlertDialog.Builder builder = new AlertDialog.Builder(AlertDialogActivity.this);
builder.setMultiChoiceItems(sexx, stu, new DialogInterface.OnMultiChoiceClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i, boolean b) {
if(b == true){
map.put(i,i);
} else {
map.remove(i);
}
}
});
builder.setPositiveButton("确定", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
for (Integer j : map.keySet()){
int z = map.get(j);
str = str + sexx[z];
}
textView.setText(str);
str = "";
}
});
builder.setNegativeButton("取消", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
}
});
builder.show();
}
});
}
}19.Android系统中的ContextMenu(上下文菜单)类似于PC中的右键弹出菜单,当一个视图注册了上下文菜单时,长按该视图对象将出现一个提供相关功能的浮动菜单。上下文菜单可以被注册到任何视图对象中,最常见的是用于列表视图中,但上下文菜单不支持图标和快捷键。
选项菜单 当Activity在前台运行时,如果用户按下微信消息列表页面右上角加号键,此时就会在屏幕右上角弹出相应的选项菜单。但这个功能需要开发人员编程来实现,如果在开发应用程序时没有实现该功能,那么程序运行时按下手机的meun键是不会起作用的。
下拉菜单 严格来讲Spinner不算是一个菜单,但是其操作和表现形式具有菜单的行为。Spinner的有效使用可以提高用户的体验。当用户需要选择的时候,可以提供一个下拉列表将所有可选的项列出来,供用户选择。
21.Toast(提示)的使用,代码实现可参考实验报告或书本。
Toast.makeText(MultipleChoiceDialogBox.this,“nihao”,Toast.LENGTH_LONG).show();
22.Notification表示通知,是可以显示在Android系统通知栏上的一种数据的封装形,运用Notification可以提高应用的交互性,带来良好的用户感受。 关于Notification,主要涉及到Notification类与NotificationManager类的使用。 Notification类的实例表示在通知栏显示的一个通知,该通知内容包括该通知的ID、时间、内容、标题、图标等。 NotificationManager实例用来将该通知发送到系统的通知栏上。
23.本地服务(Local Service)用于应用程序内部,可以实现应用程序自己的一些耗时任务,比如查询升级信息、网络传输,或者在一些场合需要在后台执行,比如播放音乐,并不占用应用程序比如Activity所属的线程,而是单开线程后台执行,这样用户体验比较好。
Service的两种启动方式 (1)通过bindService绑定: 绑定时,bindService -> onCreate() –> onBind(); 解绑定:unbindService –>onUnbind() –> onDestory(); 此时如果调用者(如Activity)直接退出,Service 由于与调用者绑定在一起,则Service随着调用者一同停止。
(2)通过startService绑定: 启动时,startService –> onCreate() –> onStart(); 停止时,stopService –> onDestroy(); 此时,服务与调用者(如Activity)没有绝对关联,当调用者关闭后服务还会一直在后台运行。 服务的生命周期
23.在Android里面有各式各样的广播,比如:电池的状态变化、信号的强弱状态、电话的接听和短信的接收等等,本节将会介绍系统发送、监听这些广播的机制。
两种广播注册方法的区别 第一种不是常驻型广播,也就是说广播跟随程序的生命周期 第二种是常驻型,也就是说当应用程序关闭后,如果有信息广播过来,程序广播接收器也会被系统调用自动运行
25.作为一个完整的应用程序,数据的存储与操作是必不可少的。Android系统为我们提供了四种数据存储方式,分别是:Shared Preference、SQLite、File和ContentProvider。 SharedPreference:一种常用的数据存储方式,其本质就是基于xml文件存储键值对(key-value)数据,通常用来存储一些简单的配置信息。
SQLite:一个轻量级的数据库,支持基本SQL语法,是Android系统中常被采用的一种数据存储方式。Android为此数据库提供了一个名为SQLiteDatabase的类,封装了一些操作数据库的API。 文件储存:即常说的文件(I/O)存储方法,常用于存储数量比较大的数据,但缺点是更新数据将是一件困难的事情。 ContentProvider:它是Android系统中能实现应用程序之间数据共享的一种存储方式。由于Android系统中,数据基本都是私有的,存放于“data/data/程序包名(package name)”目录下,所以要实现数据共享,正确方式是使用ContentProvider。由于数据通常在各应用间是私密的,所以此存储方式较少使用,但是其又是必不可少的一种存储方式。如果应用程序有数据需要共享时,就需要使用ContentProvider为这些数据定义一个URI(包装成Uri对象),然后其他的应用程序就通过ContentResolver传入这个URI来对数据进行操作。
26.SharedPreferences对象的常用方法有以下几种:
27.Sqlite数据库的使用涉及到两个类:SQLiteDataBase和SQLiteOpenHelper
SQLiteDatabase具体方法:
SQLiteOpenHelper 具体方法
例:要得到一个可写数据库,首先创建一个类继承 SQLiteOpenHelper,重写 onCreate()方法并在该方法中创建表,然后使用创建出的 SQLiteOpenHelper 的子类对象的 getWritableDatabase()方法获得一个可读写的数据库对象。
28.网络状态
29.JSON数据解析 是一种轻量级的数据交换格式,它基于纯文本,采用完全独立于语言的文本格式来存储和传输数据。在编程环境中解析JSON数据意味着将JSON字符串转换为程序可以理解并操作的数据结构 JSON Object:JSON中对象(Object)以“{”开始, 以“}”结束。对象中的每一个item都是一个键值对,表现为“key:value”的形式, 键值对之间使用逗号分隔。如下代码所示: { “name”:“coolxing”, “age”:24, “male”:true, “address”:{ “street”:“huiLongGuan”, “city”:“beijing”, “country”:“china” } }
JSONArray: JSON数组(Array)以"[“开始, 以”]“结束, 数组中的每一个元素可以是String,Number, Boolean, null, Object对象甚至是Array数组, 数组间的元素使用逗号分隔,如下代码所示: [ “coolxing”, 24, { “street”:“huiLongGuan”, “city”:“beijing”, “country”:“china” } ]
30.Webview WebView 加载页面主要调用三个方法:LoadUrl、LoadData、LoadDataWithBaseURL. LoadUrl 直接加载网页、图片并显示。 LoadData 显示文字与图片内容。(模拟器1.5、1.6)。 LoadDataWithBase 显示文字与图片内容 (支持多个模拟器版本)。 使用webview的websetting来设置,WebSetting websetting = webView.getSettings(). Websetting常用方法:
31.进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元。 通俗地讲一个进程代表一个应用程序,该应用程序运行在自己的进程当中,使用系统为其分配的堆内存,不受其他应用程序或者是其他进程的影响,是独立运行的。当然一个进程中可以同时运行多个应用程序,这时堆内存是共享的。
Android系统为每个应用程序分配了一个进程,应用程序中组件(Activity,Service,BroadCast)的状态决定的一个进程的“重要性层次”,层次最低的属于旧进程。这个“重要性层次”有五个等级,也就是进程的生命周期,按最高层次到最低层次排列如下: (1)前台进程 (2)可视进程 (3)服务进程 (4)背景进程 (5)空进程
一个Android应用只能存在一个进程,但是可以存在多个线程,也就是说,当应用启动后,系统分配了内存,这个进程的内存不被其他进程使用,但被进程中一个或多个线程共享。宏观地讲所有的进程是并发执行的,而进程中的多个线程同时执行但并不是并发的,系统的CPU会根据应用的线程数触发每个线程执行的时刻,当CPU时间轮到分配某个线程执行时刻时该线程开始执行,执行到下一个线程执行的时,依此轮询,直到线程执行结束。 在理解启动模式前,理解几个概念
- 任务 用户尝试在您的应用中执行操作时与之互动的一系列 activity。这些 activity 按照每个 activity 的打开顺序排列在称为“返回堆栈”的堆栈中,也称为任务栈。
- Activity:简单理解就是页面,下面介绍启动模式的时候我们都把它理解为“页面”;
- Intent:教材一般叫意图,简单理解它就是带操作的信息,像指令一样,接收到Intent就类似接收到指令一样。
- 一个应用可以有多个任务栈,在考虑一个应用一个任务栈的情况下,两个页面如果在不同应用程序,那么在启动这两个页面的时候,他们会被压入各自的任务栈,所以两个不同应用程序的各自页面一般不会出现在同一个任务栈中;
- onNewIntent() 方法的作用主要是允许已存在的 Activity 更新其状态以响应新的 Intent 数据。例如,在接收动态广播(如地理位置更新、消息通知等)或重新加载内容时,无需重启 Activity 就可以处理新的数据。开发者需要重写这个方法并在其中处理接收到的新 Intent 数据。
四种启动模式:
标准模式(standard)
默认启动模式,如果任务栈中没有Activity则会实例化一个新的Activity,并将其压入当前任务栈的顶部。 如果同一个Activity已经存在栈顶,那么新的实例仍然会被创建并压入栈中,因此栈中可能包含多个该Activity实例。
单例模式(singleTop)
当一个新的Intent要启动已位于栈顶的Activity(与请求的Intent匹配的Activity)时,系统不会创建新的Activity实例,而是将intent通过onNewIntent()方法传递给现有的Activity实例;
- 如果目标Activity不在栈顶,则会正常创建新的实例;
- 如果目标Activity不在栈顶而在栈顶的下一层呢? 比如现在有A-B-C-D,D在栈顶,如果传来的Intent是要打开页面C,在单例模式下也是正常创建;
总结:
在单例模式下,
- 如果页面不存在,也就是要打开的Activity没有在任务栈中实例化,那么正常创建Activity实例,并压入栈中;
- 如果Activity已经存在于任务栈中,且为栈顶,那么系统不创建新的Activity实例,而是将intent通过onNewIntent()方法传递给现有的Activity实例,
- 如果不是栈顶,正常创建Activity实例。
栈内复用模式(singleTask)
当打开一个页面,也就是启动一个Activity时,系统首先会在整个任务栈中查找这个Activity是否已经在栈中,
- 情况一:如果存在并且处于栈底,则直接把该Activity之上的所有Activity弹出栈,使这个Activity置于栈顶并调用其onNewIntent()。
- 情况二:如果在栈顶,则将intent通过onNewIntent()方法传递给现有的Activity实例
如果不存在已有的Activity实例,才会创建新的实例并放入栈顶。这种模式下的Activity始终只有一个实例存在于任务栈中。
单实例模式(singleInstance)
当启动Activity时,系统会为它创建一个新的任务栈,然后在这个新的栈顶放上这个Activity的实例。 如果再次启动这个Activity,即使是在另一个任务栈中,系统也不会创建新实例,而是将意图传递给已经存在的Activity实例。
AndroidStudio笔记
这篇文章主要介绍AndroidStudio的使用,以及一些Android开发的基础知识。以及一些开发中遇到的问题和解决方法,除此之外,还会介绍一些开发中常用的工具和技巧。
第一章
配置开发环境
- 1.安装JDK “安装连接”
- 2.安装AndroidStudio “安装连接”
- 3.安装SDK
- 4.AndroidStudio汉化
- https://www.bilibili.com/video/BV1Hz4y1K7Tc/
第二章
Gradle():自动构建 日志输出工具:查看报错 Run(运行)
工程结构: (清单文件):对Activity,service,re广播等进行注册的文件 Java目录: 后缀为 .class drawable目录:资源文件,放图片、图标、背景资源的文件 Layout目录:放页面布局文件 放图片和.xml文件,适配不同分辨率的文件夹 values目录:颜色、数组、字符串、样式
Android基本原理
Android体系结构
Android 用用程序核心组件
Activity
第四章 Activity、Fragment以及Intent通信机制
Activity生命周期
四种状态的转换
布局的特点:
第八章 数据存储和提供器
SharedPreference
使用键值对关系来获取文件
SQLite
轻量级占用内存小,支持基本的MySQL语言。 创建过程:
ContentPreference(应用存储)
通过暴露URL让软件之间可以共享文件 好比一般使用文件时,软件会要求需要访问你手机文件权限。
文件存储
网络通信编程
网络访问方式
网络状态码,例如404表示什么?
数据解析
1.JSON格式解析: 以类对象的方式进行相应,以数组的方式进行相应,也可以二者混合。
网络状态
JavaScript与Java交互
webView的使用
在简单的使用webview过程中可能无法进入指定的网页,而且AndroidStudio模拟机上还会弹出如下错误:
**Webpage not available**
The webpage at http://www.baidu.comi could not beloaded because:
net::ERR_CLEARTEXT_NOT_PERMITTED解决的办法: 请在AndroidManifest.xml文件下添加代码:
.xml文件
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE" />如果添加上面的还不可以,请在manifest中添加如下代码:
.xml文件
<?xml version="1.0" encoding="utf-8"?>
<manifest ...>
<application
...
android:usesCleartextTraffic="true">
...
</application>
</manifest>getwebSetting
2-1.Toolbar工具栏
menu文件的创建
在创建menu这个目录前,请看查看res/目录下是否包含该目录,如果没有则创建。
接着在该目录下创建xml文件,此处文件名为content_menu。在该content_menu使用<item,如下为部分代码:
.xml文件
<item
android:id="@+id/content_menu_group_chat"
android:title="发起群聊"
android:orderInCategory="1"
/><?xml version="1.0" encoding="utf-8"?>
<menu xmlns:android="http://schemas.android.com/apk/res/android">
<item
android:id="@+id/content_menu_group_chat"
android:title="发起群聊"
android:orderInCategory="1"
/>
<item
android:id="@+id/content_menu_add_friend"
android:title="添加朋友"
android:orderInCategory="2"
/>
<item
android:id="@+id/content_menu_add_RichScan"
android:title="扫一扫"
android:orderInCategory="3"
/>
<item
android:id="@+id/content_menu_add_QRcode"
android:title="扫码"
android:orderInCategory="4"
/>
</menu>结果

创建布局页面
详细代码如下:
.xml文件
<androidx.appcompat.widget.Toolbar
android:id="@+id/options_menu_toolbar"
android:layout_width="409dp"
android:layout_height="wrap_content"
android:background="?attr/colorPrimary"
android:minHeight="?attr/actionBarSize"
android:theme="?attr/actionBarTheme"
app:layout_constraintLeft_toLeftOf="parent"
app:layout_constraintRight_toRightOf="parent"
app:layout_constraintTop_toTopOf="parent" /><?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent">
<androidx.appcompat.widget.Toolbar
android:id="@+id/options_menu_toolbar"
android:layout_width="409dp"
android:layout_height="wrap_content"
android:background="?attr/colorPrimary"
android:minHeight="?attr/actionBarSize"
android:theme="?attr/actionBarTheme"
app:layout_constraintLeft_toLeftOf="parent"
app:layout_constraintRight_toRightOf="parent"
app:layout_constraintTop_toTopOf="parent" />
</androidx.constraintlayout.widget.ConstraintLayout>Activity.java1文件中
此处创建类的步骤,继承AppCompatActivity方法就不再赘述。
- 在
onCreate获取Toolbar的id,这个过程也叫实例化; - 接着使用方法
setSupportActionBar; - 在onCreate外重写
onCreateOptionsMenu和onOptionsItemSelected方法。
.java文件
@SuppressLint("MissingInflatedId")
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.opetions_menu);
toolbar = findViewById(R.id.options_menu_toolbar);
setSupportActionBar(toolbar);
}@Override
public boolean onCreateOptionsMenu(Menu menu) {
getMenuInflater().inflate(R.menu.content_menu,menu);
return super.onCreateOptionsMenu(menu);
}@Override
public boolean onOptionsItemSelected(@NonNull MenuItem item) {
//获取menu目录中content_menu.xml文件里item的id
int id = item.getItemId();
//判断id是否被点击,被点击就执行相应的动作,比如页面跳转
if(id == R.id.content_menu_add_friend){
Intent intent = new Intent(OpetionsMenu.this,ListDialogActivity.class);
startActivity(intent);
}else if(id == R.id.content_menu_group_chat){
return super.onContextItemSelected(item);
}
return false;
}package com.example.practiceapplication;
import android.annotation.SuppressLint;
import android.content.Intent;
import android.os.Bundle;
import android.view.Menu;
import android.view.MenuItem;
import androidx.annotation.NonNull;
import androidx.annotation.Nullable;
import androidx.appcompat.app.AppCompatActivity;
import androidx.appcompat.widget.Toolbar;
public class OpetionsMenu extends AppCompatActivity {
private Toolbar toolbar;
@SuppressLint("MissingInflatedId")
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.opetions_menu);
toolbar = findViewById(R.id.options_menu_toolbar);
setSupportActionBar(toolbar);
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
getMenuInflater().inflate(R.menu.content_menu,menu);
return super.onCreateOptionsMenu(menu);
}
@Override
public boolean onOptionsItemSelected(@NonNull MenuItem item) {
int id = item.getItemId();
if(id == R.id.content_menu_add_friend){
Intent intent = new Intent(OpetionsMenu.this,ListDialogActivity.class);
startActivity(intent);
}else if(id == R.id.content_menu_group_chat){
return super.onContextItemSelected(item);
}
return false;
}
}最终结果
结果

-
Activity.java这个文件的一般就是我们所说的主程序,类似与C语言中的包含main入口的文件。 ↩︎
计算机组成原理
- 过年
- 计算机组成原理-复习
1 计算机系统概论
计算机的分类
计算机总体上分为:电子模拟计算机1和电子数字计算机。二者区别如下表
比较内容 电子数字计算机 电子模拟计算机 数据表示方法 0或1 电压 计算方式 数字计算 电压组合和测量值 控制方式 程序控制 盘上连线 精度 高 低 数据存储量 大 小 逻辑计算能力 强 无 计算机的五代变化
- 第一代1946~1957年, 数据处理 得到应用;
- 第二代1958~1964年, 工业控制 开始得到应用;
- 第三代1965~1971年, 小型计算机开始出现;
- 第四代1972~1990年, 微型计算机 开始出现;
- 第五代1991年开始, 单片机 开始出现
计算机的性能指标
处理机字长 指处理机运算其中一次能工处理的二进制数运算的位数,例如32位,64位。 存储器带宽 单位时间内从存储器独处的二进制数信息量,一般用 字节数/秒表示。
计算机组成原理 的子部分
过年
计算机组成原理-复习
1 计算机系统概论
计算机的分类
计算机总体上分为:电子模拟计算机1和电子数字计算机。二者区别如下表
| 比较内容 | 电子数字计算机 | 电子模拟计算机 |
|---|---|---|
| 数据表示方法 | 0或1 | 电压 |
| 计算方式 | 数字计算 | 电压组合和测量值 |
| 控制方式 | 程序控制 | 盘上连线 |
| 精度 | 高 | 低 |
| 数据存储量 | 大 | 小 |
| 逻辑计算能力 | 强 | 无 |
计算机的五代变化
- 第一代1946~1957年, 数据处理 得到应用;
- 第二代1958~1964年, 工业控制 开始得到应用;
- 第三代1965~1971年, 小型计算机开始出现;
- 第四代1972~1990年, 微型计算机 开始出现;
- 第五代1991年开始, 单片机 开始出现
计算机的性能指标
处理机字长 指处理机运算其中一次能工处理的二进制数运算的位数,例如32位,64位。 存储器带宽 单位时间内从存储器独处的二进制数信息量,一般用 字节数/秒表示。
2 运算方法和运算器
注:
- 掌握各进制之间的转换;
- 掌握小数点之间的二进制与十进制之间的转换;
二进制纯小数或纯整数表示方法
- 二进制纯小数: 0.10101 或 1.10101,0或1表示正负号,在正负号后面,在实际中计算机并不存储小数点;
- 二进制纯整数: 10101.,同样纯整数也用0或1区分正负号。
用Xn-1表示二进制数的个数,Xn表示符号位,如下:
Xn Xn-1……X0 符号 量值(尾数)
纯小数表示范围: $0<=|x|<=1-2^{-n} $ 纯整数表示范围: $0<=|x|<=2^{-n} - 1$
浮点数表示方法
电子质量(克): 9×10^28 = 0.9×10^27 太阳质量(克): 2×10^33 = 0.2×10^34
任意十进制数 N 可以表示为:
$$N=10^E \cdot M$$同样在二进制中也有这样类似的表达:
$$ N=2^e \cdot M$$在二进制浮点数表达中:
- 尾数:M,是一个纯小数;
- 比例因子:e,表示指数,常用整数表示,也称为 阶码 ;
- 基数:式子中的2
二进制浮点数格式:
| $E_s$ | $E_m-1…E_1 E_0$ | $M_s$ | $M_m-1…M_1 M_0$ |
|---|---|---|---|
| 阶符 | 阶码 | 数符 | 尾数 |
IEEE754标准格式表示浮点数
知识储备: $\frac{1}{2^0}=1$,$\frac{1}{2^1}=0.5$,$\frac{1}{2^2}=0.25$,$\frac{1}{2^3}=0.125$,$\frac{1}{2^4}=0.0625$,$\frac{1}{2^5}=0.03125$
浮点数表示:
$$ N=2^e \cdot M$$浮点数所占位数:
| $S$ | $E$ | $M$ |
|---|---|---|
| $31$ | $30 \gets 23$ | $22 \gets 0$ |
- 基数R=2,基数固定,采用隐含方式来表示它。
- 32位的浮点数:
- S数的符号位,1位,在最高位,“0”表示正数,“1”表示负 数。
- M是尾数, 23位,在低位部分,采用纯小数表示,不对小数点进行存储;
- E是阶码,8位,也就是说阶码最大不超过255,但阶码采用移码表示$E=2^{7}+e=127+e$,原因是移码比较大小方便。
- 规格化: 若不对浮点数的表示作出明确规定,同一个浮点数的表示就不是惟一的,所以一般都会规定这个浮点数的位数
- 尾数域最左位(最高有效位)总是1, 故这一位经常不予存储,而认为隐藏在小数点的左边。
- 采用这种方式时,将浮点数的指数真值e变成阶码E时,应将指数e加上一个固定的偏移值127(01111111),即E=e+127。如果是二进制转真值就E=e-127
下面举两个例子进行说明:
例1:二进制转十进制若浮点数x的754标准存储格式为(41360000)16,求其浮点数的十进制数值。
解:将16进制数展开后,可得二制数格式为
0 100 00010 011 0110 0000 0000 0000 0000
符号S=0
阶码E=100 00010
尾数M=011 0110 0000 0000 0000 0000
指数e=E-127=10000010-01111111=00000011=$(3)_10$,故有
1.M=1.011 0110 0000 0000 0000 0000=1.011011
于是有
$x=(-1)S \times 1.M \times 2^e=+(1.011011) \times 2^3=+1011.011=(11.375)_10$问: 0.011怎么转成0.375?
根据上面的知识储备有$ \frac{1}{2^0}\times 0 + \frac{1}{2^1}\times 1 +\frac{1}{2^2}\times 1=0+0.25+0.125=0.375 $
例2:十进制转二进制若浮点数为$(28.8125)_10$,求其浮点数的IEEE754标准存储格式的二进制数值。
解:$(28.8125)_10$=$(11100.1101)_2$
格式化表示为:$(11100.1101)_2=1.11001101 \times 2^4$
于是有
e=4
E=e+127=4+127=131=$(1000 0011)_2$
M=1100 1101 0000 0000 0000 000(去掉小数点和小数点前的1,而且有23位,不够补0)
S=0
IEEE754标准的32为存储数据位:0 1000 0011 1100 1101 0000 0000 0000 000
数的机器码表示
计算机进行运算时,会把符号位和数字一起编码表示为相应的数,这些数可以用不同的方法表示,例如:原码、补码、移码、反码;
为了区别一般写的数(比如-12,+3等)和机器中的编码(比如 0 1100,1 0011),通常前者称之为 真值,后者称为 机器数 或 机器码 。
$[x]_原$表示机器数,x表示真值。
例如:
$x=+0011$,$[x]{_原}=\textbf{0}0011$
$x=-0011$,$[x]{_原}=\textbf{1}0011$,
原码机器中有“+0”“-0”之分,固有两种形式:例如:$[x]{_原}$与$\textbf{1}0011$表达的意思一样。
数学上把类似于$-3=+9 (mod12)$的式成为 同余式。
原码、反码、补码、移码
对原码、反码、补码、移码的简单说明,已知计算机为4位,x=-3.
| 例子 | 表示方法 | 二进制 | 说明 |
|---|---|---|---|
| -3 | 原码 | $[-3]{_原}$=00011 | |
| -3 | 反码 | $[-3]{_反}$=01100 | 按位取反 |
| -3 | 补码 | $[-3]{_补}$=01101 | 反码最低位加1,注意这个时候符号还是1 |
| -3 | 移码 | $[-3]{_移}$=1,1101 | $[e]{_移}=2^{k}+e=2^4-0011=0,1101$ |
对于正数来说,前三个都一样,重点说明移码:
定点整数定义 $[e]{_移}=2^{k}+e, 2^k >e≥-2^k$
上面的表达式中,$[e]{_移}$表示机器码,e为真值,$2^k$表示固定偏移常量。
已知e=+0011,k=4,$[e]{_移}=2^{k}+e=2^{4}+0011=1,0011$
已知e=-0011,k=4,$[e]{_移}=2^{k}+e=2^{4}-0011=0,1101$
移码中的逗号不是小数点,而是表示左边一位是符号位,显然移码中符号位与前三者的表示相反(详见P21)。
下面请看例题:
已知计算机是8位的,请分别写出纯整数125,-110,纯小数+0.125,-0.375;二进制数x=11011,y=-01010的原码、反码、补码、移码。(注意格式,要对齐)
| 表示方法 | 表示方法 | |
|---|---|---|
| +125=00101 1111 | -110=10011 1011 | |
| $[125]{_原}$=00101 1111 | $[-110]{_原}$=10011 1011 | |
| $[125]{_反}$=00101 1111 | $[-110]{_反}$=11100 0100 | |
| $[125]{_补}$=00101 1111 | $[-110]{_补}$=11100 0101 | |
| $[125]{_移}$=1,0101 1111 | $[-110]{_移}$=0,1100 0100 | |
| +0.125=0.0010 0000 | -0.357=1.0110 0000 | |
| $[125]{_原}$=0.0010 0000 | $[-110]{_原}$=1.0110 0000 | |
| $[125]{_反}$=0.0010 0000 | $[-110]{_反}$=1.1001 1111 | |
| $[125]{_补}$=0.0010 0000 | $[-110]{_补}$=1.1010 0000 | |
| $[125]{_移}$=1,0010 0000 | $[-110]{_移}$=0,1010 0000 | |
| x=11011 | -110=-01010 | |
| $[125]{_原}$=00001 1011 | $[-110]{_原}$=10000 1010 | |
| $[125]{_反}$=00001 1011 | $[-110]{_反}$=11111 0101 | |
| $[125]{_补}$=00001 1011 | $[-110]{_补}$=11111 0111 | |
| $[125]{_移}$=1,0001 1011 | $[-110]{_移}$=0,1111 0111 |
定点加法、减法运算
公式 补码加法:任意两数补码之和等于两数之和的补码,$[x]{_补}+[y]{_补}=[x+y]{_补}$
补码减法:$[x-y]{_补}=[x]{_补}-[y]{_补}=[x]{_补}+[-y]{_补}$
从$[y]{_补}$求$[-y]{_补}$的法则是对$[y]{_补}$包括符号位在内求反,最低位加1得到表达式为:
$[-y]{_补}=\rightharpoondown [y]{_补}+2^{-n}$其中,符号$\rightharpoondown$表示对$[y]{_补}$作求反操作,包括正负号在内,$2^{-n}$表示末位(最低位)加1.
下面举例加以理解运算过程:
( 详见P29 )
溢出概念与检验方法
在定点整数机器中,运算过程中出现大于字长绝对值的现象称为 溢出,溢出分正、负溢出两种,用两位符号位表示, 00、11分别表示整数和负数,01表示正溢出,10 表示负溢出。
详细说明原理: 假设x表示二进制数,用$2^{-n}
定点乘法运算
乘法运算拆分来看主要有算术运算加法,逻辑运算异或,还有移位操作。
四位二进制数x,y,两数进行乘法运算,符号位不参与数值位分开运算,一开始y的最低位与x的每一位进行异或并输出结果,下一次y的次高位与x的每一位进行异或运算,结果输出并左移次高位的位数,假设次高位是2,那么左移两位输出结果。
举个例子,如下:
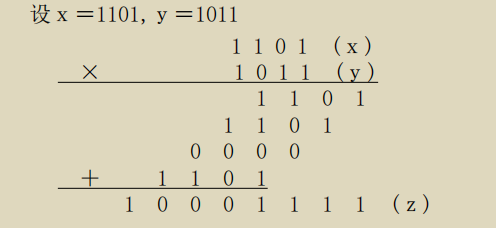
定点数除法运算
定点数除法运算这里提供两种方法:
- 恢复余数法
这种方法是手工计算,而非机器计算,如下图:
定点原码一位除法实现方案(手工)0.10010/0.1011
 2. 加减交替法(不恢复余数法)
2. 加减交替法(不恢复余数法)
在这之前我们先简单了解并行除法器,如下图:
被除数 $0.x{_6}x{_5}x{_4}x{_3}x{_2}x{_1}$
(双倍长)
除数 $0.y{_3}y{_2}y{_1}$
商数 $0.q{_3}q{_2}q{_1}$
余数 $0.r{_6}r{_5}r{_4}r{_3}r{_2}r{_1}$
除数右移
例题:x=0.101001, y=0.111, 求${x}\div{y}$

浮点运算方法,浮点运算器
再次我们在此复习浮点数的表示方法
$$ N=2^e \cdot M$$以及32位IEEE754标准格式
| $S$ | $E$ | $M$ |
|---|---|---|
| $31$ | $30 \gets 23$ | $22 \gets 0$ |
浮点运算步骤
- 0操作数检查。一般就是检查运算数是否为0,不卸载步骤中
- 比较阶码(E)并完成对阶(小阶向大阶对齐)
- 尾数(M)求和运算
- 结果规格化,把运算结果写成1.M的格式
- 检查上溢出或下溢出(-127<=x<=127,x在这个范围就表示没有溢出,如果溢出需要通过 变形补码 来判断是正溢出(01),还是负溢出(10))
- 舍入处理。写出要求需要的有效位,并用十进制检验是否正确
例题:设$x=0.5{_10},y=0.4375{_10}$,假设尾数有效位为4位,用二进制求$(x+y){_浮}$
把x和化为1.M的格式 $x=0.5{_10}=0.1{_2}=0.1{_2}\cdot 2^0=1.000{_2}\cdot 2^{-1}$ $x=-0.4375{_10}=-0.0111{_2}=-0.0111{_2}\cdot 2^0=-1.000{_2}\cdot 2^{-2}$
在这里需要对上面的转换进行说明,说明前我们先看$0.2\cdot10^{0}$,如果现在想写成2,那上面的式子该怎么改呢?
修改如下: $0.2\cdot10^{0}=2\cdot10^{-1}$
也就是要让式子的左右相等,所以后面10的次方就不一样,理解了上面这个我们再来看$-0.1{_2}\cdot 2^0=-1.000{_2}\cdot 2^{-1}$就会更好理解。
下面是具体的步骤:
- 对阶,由上可知y的阶小,向x的看齐 $-1.000{_2}\cdot 2^2=-0.100{_2}\cdot 2^{-1}$
- 尾数相加, $1.000{_2}\cdot 2^{-1}+(-0.100{_2}\cdot 2^{-1})=0.001{_2}\cdot 2^{-1}$
- 规格化:把结果把x和化为1.M的格式 $0.001{_2}\cdot 2^{-1}=1.0000{_2}\cdot 2^{-4}$
- 检验上溢或下溢 由于指数-4用移码表示,-127<=-4<=127,-4在这个范围即没有溢出
- 舍入操作 根据题目要求$(x+y){_浮}=1.0000{_2}\cdot 2^{-4}=0.0625{_10}$ 十进制检验结果x+y=0.5-0.4375=0.0625
浮点数乘除法运算
乘除运算分为四步
- 0操作数检查
- 阶码加减操作
- 尾数乘除操作
- 结果规格化和舍入处理
流程与浮点数乘除法类似,但也有不同的地方,下面以乘法运算为例子详细说明具体步骤:
- 将两数的指数部分相加(前提是你要把两数规格化为1.M的形式)
- 将被乘数和乘数的尾数相乘
- 规格化于溢出检测
- 舍入操作
- 确定乘积的符号(同号为正,异号为负)
存储系统
存储系统的层次结构
目前存储器的特点是:
• 速度快的存储器价格贵,容量小; • 价格低的存储器速度慢,容量大。
- 高速缓冲存储器简称cache,它是计算机系统中的一个高速小容量半导体存储器。
- 主存储器简称 主存,是计算机系统的主要存储器,用来存放计算机运行期间的 大量程序 和 数据 。
- 外存储器简称 外存,它是大容量辅助存储器。
存储系统分类
- 按 存储介质 分类:磁表面/半导体存储器
- 按 存取方式 分类:随机/顺序存取(磁带)
- 按 读写功能 分类:ROM,RAM
- RAM,随机存取存储器 :双极型/MOS
- ROM,只读存储器 :MROM/一次可编程只读存储器PROM/可擦除EPROM/电可擦除EEPROM
- 按信息的可保存性分类:永久性和非永久性的
- 按存储器系统中的作用分类:主/辅/缓/控
存储器的编制和端模式
- 字存储单元:存放一个机器字的存储单元,相应的单元地址叫字地址。
- 字节存储单元:存放一个字节的单元,相应的地址称为字节地址。
- 端模式:一个存储字内部的多字节排列方式。
- 大端 big-endian
- 小端 little-endian
存储器技术
- 存储容量: 指一个存储器中可以容纳的存储单元总数。存储容量越大,能存储的信息就越多。
- 存取时间 又称存储器访问时间:指一次读操作命令发出到该操作完成,将数据读出到数据总线上所经历的时间。通常取写操作时间等于读操作时间,故称为存储器存取时间。
- 存储周期: 指连续启动两次读操作所需间隔的最小时间。通常,存储周期略大于存取时间,其时间单位为ns。
- 存储器带宽: 单位时间里存储器所存取的信息量,通常以位/秒或字节/秒做度量单位。 记住:$1KB=2^{10}B,1MB=2^{20}B,1GB=2^{30}B,1TB=2^{40}B$
SRAM存储器
- 主存(内部存储器)是半导体存储器。根据信息存储的机理不同可以分为两类:
- 静态读写存储器(SRAM):存取速度快
- 动态读写存储器(DRAM):存储密度和容量比SRAM大。
三组信号线:
地址线:n条地址线,确定存储单元(地址)的个数,或说有2^n个存储单元。
数据线:决定字的长度(位数)。6条地址线,4条数据线,没那么有64*4个存储位元的总数。
行线
列线
控制线:控制读/写,读写不会同时进行
例如一台计算机数据线有4条,那么它就是4位的计算机。
存储容量的扩充
1、字长位数扩展 字节不变,即给的地址线不变,改变数据线让芯片容量符合设计要求。
芯片个数d=设计要求的存储器容量/选择芯片存储器容量
[例2] 利用1M×4位的SRAM芯片,设计一个存储容量 为1M×8位的SRAM存储器。
解:所需芯片数量=(1M×8)/(1M×4)=2片
2、字存储容量扩展
位不变,即数据线不变,通过增加芯片改变地址线使其符合设计要求。
芯片个数d=设计要求的存储器容量/选择芯片存储器容量
[例3]利用1M×8位的DRAM芯片设计2M×8位的DRAM存储 器 解:所需芯片数d=(2M×8)/(1M×8)=2(片)
3、字节扩展
先进行位扩展(数据线bite),字节扩展(字节扩展Byte)
动态随机存取存储器
工作原理图
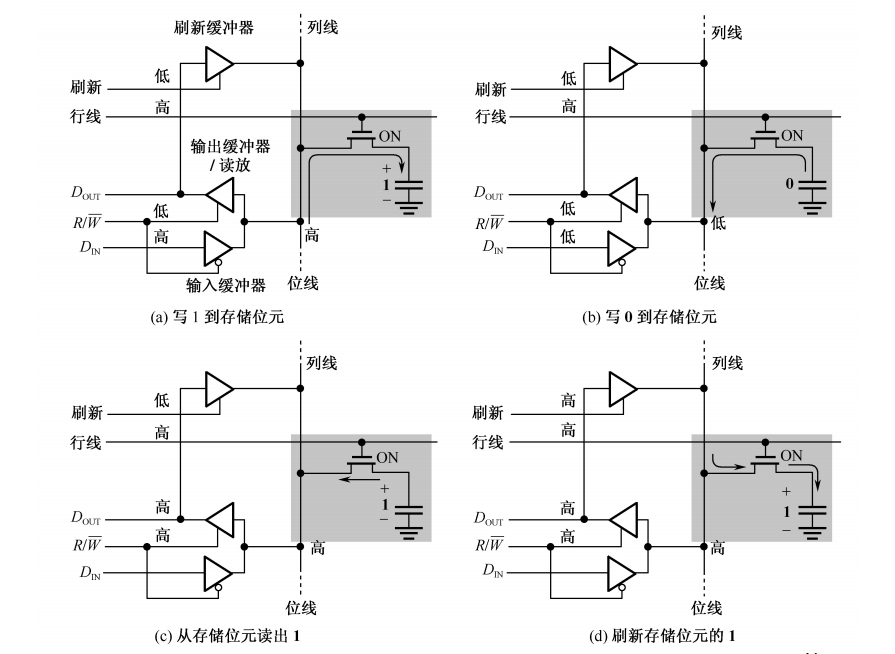 原理图上的刷新本质上是给mos管充电。
原理图上的刷新本质上是给mos管充电。
动态随机存取存储器的刷新操作
刷新的目的是为了保存存储器的存储信息。 注:读出1才会刷新,读出0不会刷新。 当前主流的DRAM器件的刷新周期间隔时间为64秒
- 集中式刷新。先工作最后在进行充电,假设DRAM有1024行,刷新周期为8ms(这里假设是8ms)
- 分散式刷新。边工作边刷行,假设DRAM有1024行,由8ms(这里假设是8ms)除以1024=7.4us,所以刷新周期为7.4us
只读存储器
ROM叫做只读存储器。顾名思义,只读的意思是 在它工作时只能读出,不能写入。然而其中存储的原 始数据,必须在它工作以前写入。只读存储器由于工 作可靠,保密性强,在计算机系统中得到广泛的应用。
主要有两类:
- 掩模ROM:掩模ROM实际上是一个存储内容固定的ROM,由生产厂家提供产品。
- 可编程ROM:用户后写入内容,有些可以多次写入。
- 一次性编程的PROM
- 多次编程的EPROM和E2PROM。
掩模ROM
1、掩模ROM的阵列结构和存储元
2、可编程ROM
EPROM叫做 光擦除可编程可读存储器。它的存储内容可以根据需要写入,当需要更新时将原存储内容抹去,再写入新的内容。 现以浮栅雪崩注入型MOS管为存储元的EPROM为例进行说明,结构如下图所示。
E2PROM存储元
EEPROM,叫做电擦除可编程只读存储器。其存储元是一个具有两个栅极的NMOS管,如图(a)和(b)所示,G1是控制栅,它是一个浮栅,无引出线;G2是抹去栅,它有引出线。在G1栅和漏极D之间有一小面积的氧化层,其厚度极薄,可产生隧道效应。如图(c)所示,当G2栅加20V正脉冲P1时,通过隧道效应,电子由衬底注入到G1浮栅,相当于存储了1”。利用此方法可将存储器抹成全“1”状态。
FLASH
FLASH存储器也翻译成闪速存储器,它是高密度非失易失性的读/写存储器。高密度意味着它具有巨大比特数目的存储容量。非易失性意味着存放的数据在没有电源的情况下可以长期保存。总之,它既有RAM的优点,又有ROM的优点,称得上是存储技术划时代的进展。
FLASH存储器的基本操作 编程操作、读取操作、擦除操作。
并行存储器
并行存储器的作用:提高读写效率
双端口与存储器
1、双端口存储器的逻辑结构
双端口存储器由同一个存储器具有两组 相互独立的读写控制电路 而得名。由于进行并行的独立操作,因而是一种高速工作的存储器,在科研和工程中非常有用。 举例说明,双端口存储器IDT7133的逻辑框图 。如下图:
2、无冲突读写控制
当两个端口的地址不相同时,在两个端口上进行读写操作,一定不会发生冲突。当任一端口被选中驱动时,就可对整个存储器进行存取,每一个端口都有自己的片选控制(CE)和输出驱动控制(OE)。读操作时,端口的OE(低电平有效)打开输出驱动器,由存储矩阵读出的数据就出现在I/O线上。
3、有冲突读写控制
当两个端口同时存取存储器同一存储单元时,便发生读写冲突。为解决此问题,特设置了BUSY标志。在这种情况下,片上的判断逻辑可以决定对哪个端口优先进行读写操作,而对另一个被延迟的端口置BUSY标志(BUSY变为低电平),即暂时关闭此端口。
多模块交叉存储器
1、存储器的模块化组织 一个由若干个模块组成的主存储器是线性编址的。这些地址在各模块中如何安排,有两种方式:
- 一种是 顺序方式 ,
- 一种是 交叉方式 。
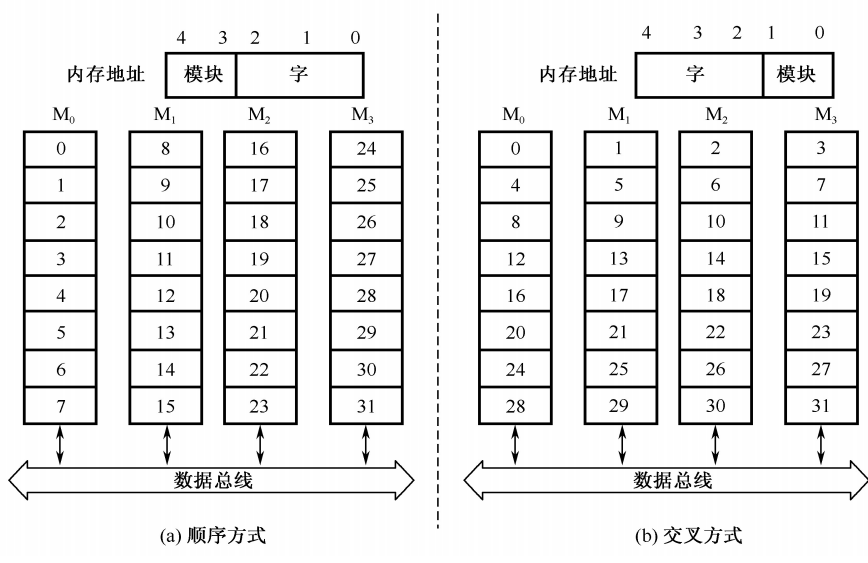
顺序方式
[例]M0-M3共四个模块,则每个模块8个字
顺序方式:
M0:0—7 M1:8-15 M2:16-23 M3:24-31
- 5位地址组织如下: X X X X X
- 高位选模块,低位选块内地址
- 特点:某个模块进行存取时,其他模块不工作,优点是某一模块出现故障时,其他模块可以照常工作,通过增添模块来扩充存储器容量比较方便。缺点是各模块串行工作,存储器的带宽受到了限制。
交叉方式
-
M0:0,4,…除以4余数为0
-
M1:1,5,…除以4余数为1
-
M2:2,6,…除以4余数为2
-
M3:3,7,…除以4余数为3
-
5位地址组织如下: X X X X X
-
高位选块内地址,低位选模块
-
特点:连续地址分布在相邻的不同模块内,同一个模块内的地址都是不连续的。优点是对连续字的成块传送可实现多模块流水式并行存取,大大提高存储器的带宽。使用场合为成批数据读取。
多模块交叉存储器的基本结构 下图为四模块交叉存储器结构框图。主存被分成4个相互独立、容量相同的模块M0,M1,M2,M3,每个模块都有自己的读写控制电路、地址寄器和数据寄存器,各自以等同的方式与CPU传送信息。在理想情况下,如果程序段或数据块都是连续地在主存中存取,那么将大大提高主存的访问速度。 !ptu13
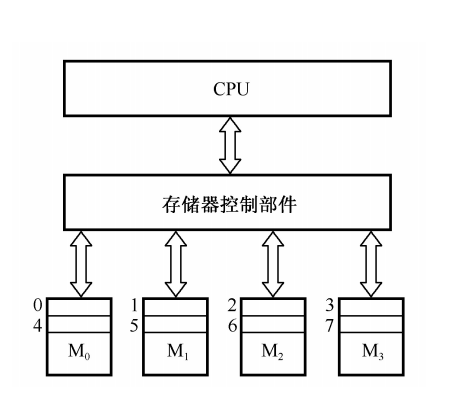{kind=link}
- 通常在一个存储器周期内,n个存储体必须分时启动,则各个存储体的启动间隔为$t=\frac{T}{n}$(n为交叉存取度)
- 整个存储器的存取速度有望提高n倍 $t{_顺序}=xT$ $t{_交叉}=T\frac{x+n-1}{n}$
cache 基本原理
为了解决CPU和主存之间速度不匹配而采取的一种重要技术。
- 一般采用高速的SRAM构成。
- CPU和主存之间的速度差别很大采用两级或多级Cache系统
- 早期的一级Cache在CPU内,二级在主板上
- 现在的CPU内带L1 Cache和L2 Cache
- 全由硬件调度,对用户透明
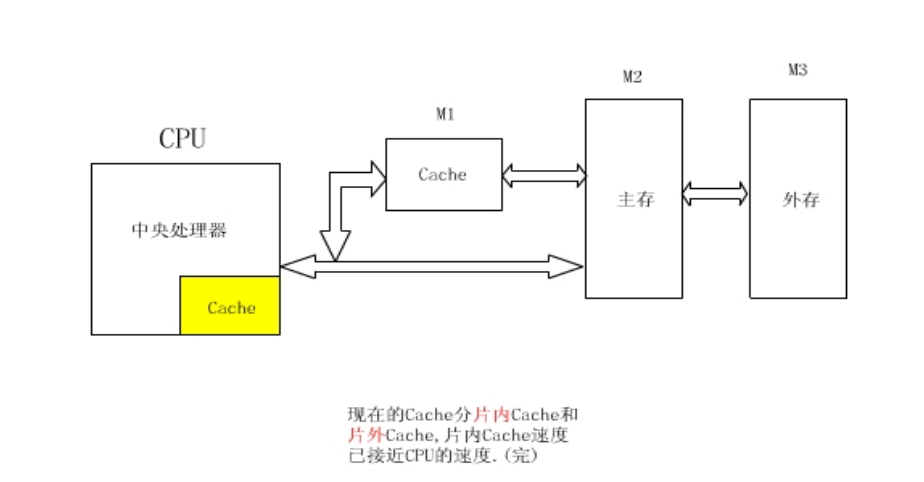 cpu与缓存之间数据交换是以字节为单位,而缓存与主存之间的数据交换以块为单位,一个块有若干组成,是定长的。
cpu与缓存之间数据交换是以字节为单位,而缓存与主存之间的数据交换以块为单位,一个块有若干组成,是定长的。
从CPU来看,增加一个cache的目的,就是在性能上使主存的平均读出时间尽可能接近cache的读出时间。为了达到这个目的,在所有的存储器访问中由cache满足CPU需要的部分应占很高的比例,即cache的命中率应接近于1。由于程序访问的局部性,实现这个目标是可能的。
命中率:CPU访问cache且需要获取的文件在cache里,即为命中,公示如下: $h=\frac{N{_c}}{N{_c}+N{_m}}$
$N{_c}$:cache完成存取的总次数(访问cache的总次数);
$N{_m}$:主存完成存取的总次数。
主存与cache的地址映射
无论选择那种映射方式,都要把主存和cache划分为同样大小的“块”。下面介绍三种一映射方式:
1、全相联的映射方式(一对多,一是指缓存,多是指主存里的数据块)
(1)将地址分为两部分(块号和字),在内存块写入Cache时,同时写入块号标记;
(2)CPU给出访问地址后,也将地址分为两部分(块号和字),比较电路块号与Cache 表中的标记进行比较,相同表示命中,访问相应单元;如果没有命中访问内存,CPU 直接访问内存,并将被访问内存的相对应块写入Cache。
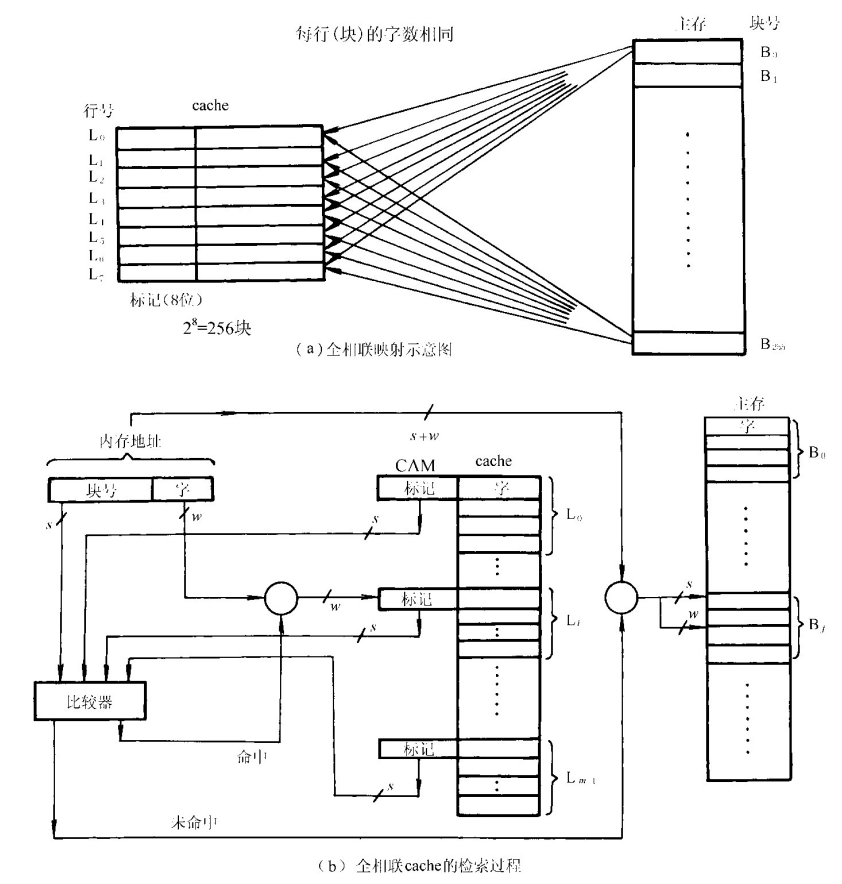
1、全相联映射方式
特点:
- 优点:冲突概率小,Cache的利用高。
- 缺点:比较器电路难实现,适用于小容量的Cache
直接映射方式
2、直接映射方式(一对多):
- i= j mod m
- m为cache中的总行数
- 主存第j块内容拷贝到Cache的i行
- 一般I和m都是2^N级
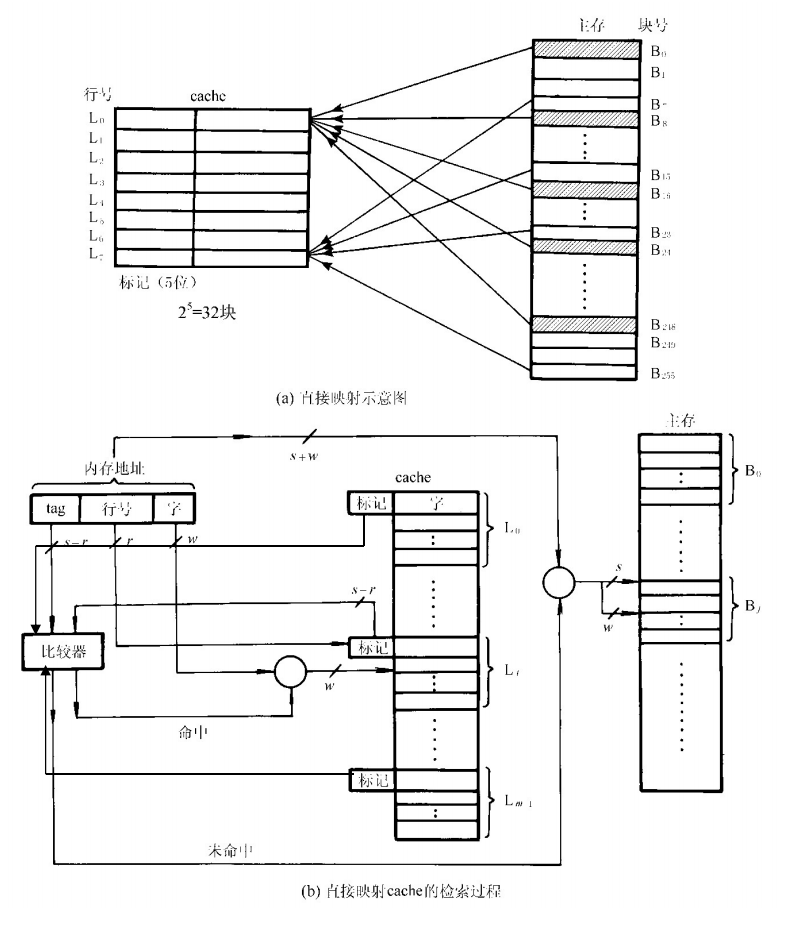
[例]cache容量16字,主存容量256字,则地址2,18,34…..242等都存放在cache的地址2内,如果第一次2在cache中,下次访问34内容,则不管cache其他位置的内容访问情况,都会引起2块内容的替换。
特点
- 优点:比较电路少m倍线路,所以硬件实现简单,Cache地址为主存地址的低几位,不需变换。
- 缺点:冲突概率高(抖动)
- 适合大容量Cache
组相联映射方式
前两者的组合
- Cache分组,组间采用直接映射方式,组内采用全相联的映射方式
- Cache分组U,组内容量V
- 映射方法(一对多)
- q= j mod u
- 主存第j块内容拷贝到Cache的q组中的某行
- 地址变换
- 设主存地址x,看是不是在cache中,先y= x mod u,则在y组中一次查找
分析:比全相联容易实现,冲突低
- v=1,则为直接相联映射方式
- u=1,则为全相联映射方式
- v的取值一般比较小, 一般是2的幂,称之为v路组相联cache。
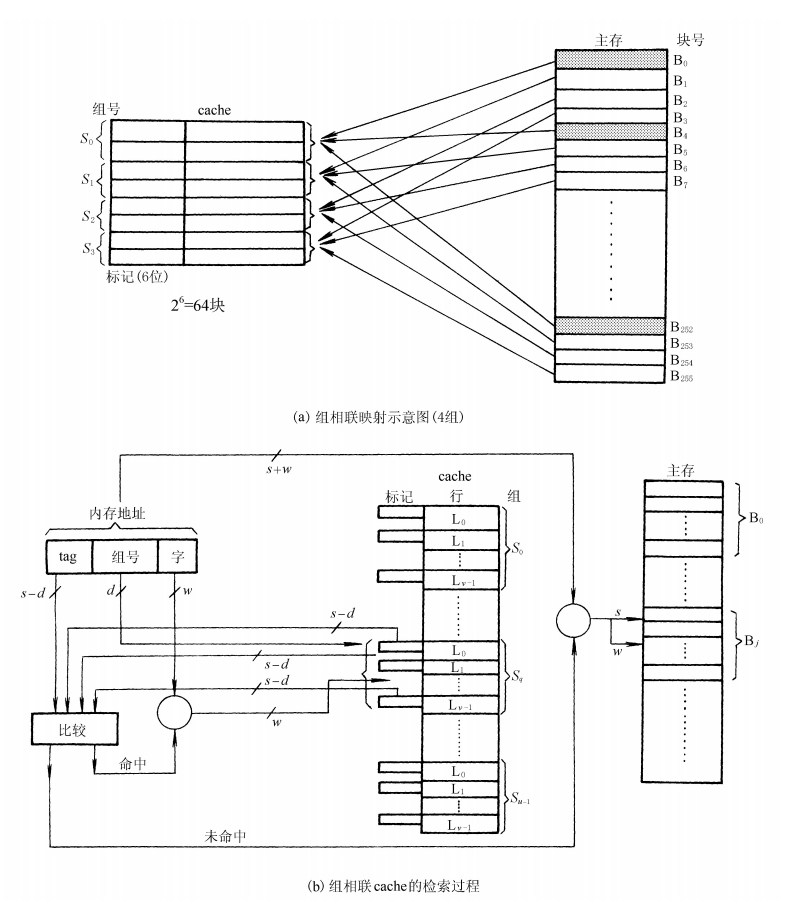
cache替换策略
- LFU(最不经常使用 ):每行有一个计数器,被访问的行计数器增加1,哪一行的值小,就换值小的行,不能反映近期cache的访问情况,
- LRU(近期最少使用) :被访问的行计数器置0,其他的计数器增加1,哪一行的值大,换值大的行,符合cache的工作原理
- 随机替换:随机替换策略实际上是不要什么算法,从特定的行位置中随机地选取一行换出即可。这种策略在硬件上容易实现,且速度也比前两种策略快。
- 缺点:随意换出的数据很可能马上又要使用,从而降低命中率和cache工作效率。
- 优点:但这个不足随着cache容量增大而减小。随机替换策略的功效只是稍逊于前两种策略。
由于cache的内容只是主存部分内容的拷贝,它应当 与主存内容保持一致。而CPU对cache的写入更改了cache的内容。如何与主存内容保持一致,可选用如下三种写操作策略。
- 写回法:换出时,对行的修改位进行判断,决定是写回还是舍掉。当主存数据传向缓存而缓存满的时候,缓存就要进行替换,只有这个时候才将数据写回主存。
- 全写法:写命中时,Cache与内存一起写,也就是主存和缓存一起更改;
- 写一次法:与写回法一致,第一次Cache命中时采用全写法,也就是这个时候要把数据写回主存,因为第一次命中的时候CPU会在总线上启动一个存储写周期,其他cache即可监听到该消息,选择复制或丢弃该数据,以便委会系统全部cache的一致性。
4 指令系统
指令系统基本概念
指令:就是要计算机执行某种操作的命令。从计算机组成的层次结构来说,计算机的指令有微指令、机器指令和宏指令之分。
$指令=\begin{cases}微指令\\机器指令\\宏指令\end{cases}$- 微指令 是微程序级的命令,它属于硬件;
- 宏指令: 由若干条机器指令组成的软件指令,它属于软件;
- 机器指令: 介于微指令与宏指令之间,通常简称为指令,每一条指令可完成一个独立的算术运算或逻辑运算操作。
本小节介绍的就是机器指令。
指令系统的性能要求
- 完备性
- 规整性
- 有效性
- 兼容性
低级语言与高级语言的关系
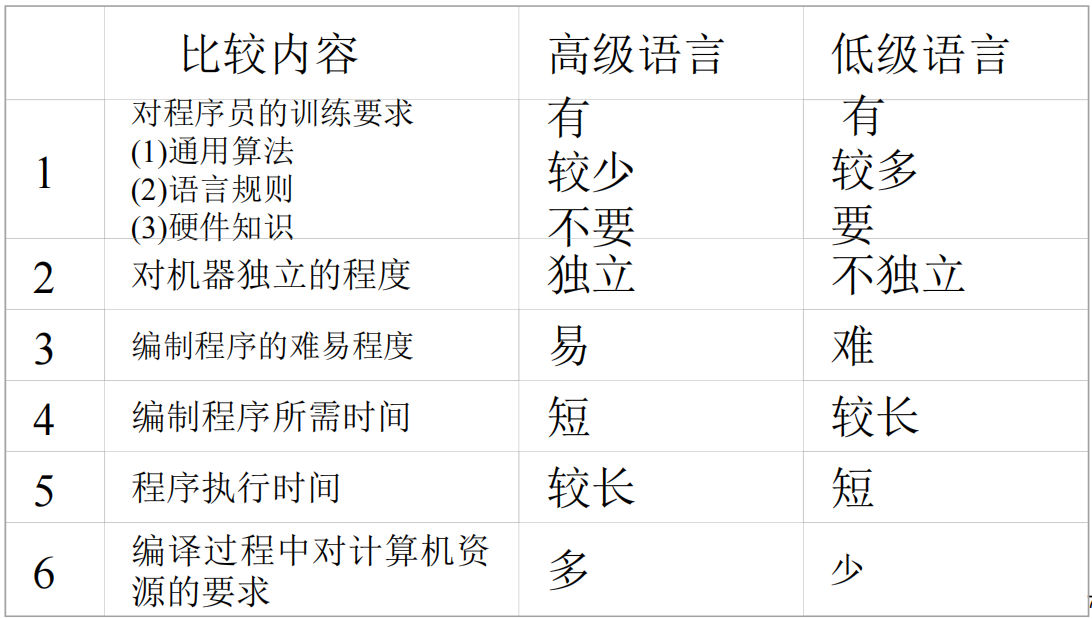
机器程序员看到的计算机属性就是指令系统体系结构,简称 ISA。
指令格式
| 操作字段OP | 地址码字段A |
|---|---|
| 表示进行什么性质的操作,如+、-等 | 存储操作数的地址 |
不同的指令用操作码字段的不同编码来表示,每一种编码代表一种指令。
根据一条指令中有几个操作数地址,可将该指令称为几操作数指令或几地址指令。
- 三地址指令
- 二地址指令
- 单地址指令
- 零地址指令
地址码名称 操作码 地址块1 地址块2 地址块3 三地址指令 OP码 $A_1$ $A_2$ $A_3$ 二地址指令 OP码 $A_1$ $A_2$ 一地址指令 OP码 $A$ 零地址指令 OP码
三地址指令
| 三地址指令 | OP码 | $A_1$ | $A_2$ | $A_3$ |
|---|---|---|---|---|
| 操作码 | 被操作数或源操作数地址 | 操作数或终点操作数地址 | 存放结果操作数地址 |
- 功能描述:
- (A1) op(A2)→A3(把A1A2的结果存放到A3中)
- (PC) +1→PC(PC加1)
这种格式虽然省去了一个地址,但指令长度仍比较长,所以只在字长较长的大、中型机中使用,而小型、微型机中很少使用。
二地址指令(双操作数指令)
| 二地址指令 | OP码 | $A_1$ | $A_2$ |
|---|---|---|---|
| 操作码 | 第一操作数 | 第二操作数 |
- 功能描述:
- (A1) op(A2)→A1
- (PC)+1→PC
- 二地址指令在计算机中得到了广泛的应用,但是在使用时有一点必须注意:指令执行之后,A1中原存的内容已经被新的运算结果替换了。
二地址地址根据操作数的物理位置分为:
- SS 存储器-存储器类型
- RS 寄存器-存储器类型
- RR 寄存器-寄存器类型 RR到RS再到SS,指令执行会越来越慢,也就是说指令执行从内存某个单元到内存的另一个单元比较慢。
一地址指令
| 一地址指令 | OP码 | $A$ |
|---|---|---|
| 操作码 | 操作数 |
功能描述:
- (AC) op(A1) →A1
- (PC)+1→PC
- 单操作数运算指令,如“+1”、“-1”、“求反”
- 指令中给出一个源操作数的地址
零地址指令
| 零地址指令 | OP码 |
|---|---|
| 操作码 |
功能:“停机”、“空操作”、“清除”等控制类指令。
指令字长度
概念
- 指令字长度(一个指令字包含二进制代码的位数)
- 机器字长:计算机能直接处理的二进制数据的位数。
- 单字长指令
- 半字长指令
- 双字长指令
多字长指令的优缺点
-
优点提供足够的地址位来解决访问内存任何单元的寻址问题 ;
-
缺点必须两次或多次访问内存以取出一整条指令,降低了CPU的运算速度,又占用了更多的存储空间。
-
指令系统中指令采用 等长指令 的优点:各种指令字长度是相等的,指令字结构简单,且指令字长度是不变的 ;
-
采用 非等长指令 的的优点:各种指令字长度随指令功能而异,结构灵活,能充分利用指令长度,但指令的控制较复杂 。
指令助记符
| 零地址指令 | OP码 | OP码 |
|---|---|---|
| 加法 | ADD | 001 |
| 减法 | SUB | 010 |
| 传送 | MOV | 011 |
| 跳转 | JMP | 100 |
| 转子 | JSR | 101 |
| 存数 | STO | 110 |
| 取数 | LAD | 111 |
操作数类型
- 地址数据:地址实际上也是一种形式的数据。( 类似指针 )
- 数值数据:计算机中普遍使用的三种类型的数值数据。
- 字符数据:文本数据或字符串,目前广泛使用ASCII码。
- 逻辑数据:一个单元中有几位二进制bit项组成,每个bit的值可以是1或0。当数据以这种方式看待时,称为逻辑性数据。(类似布尔型)
指令和数据的寻址方式
$指令寻址方式=\begin{cases}顺序寻址\\跳跃寻址\end{cases}$ 此处的跳跃寻址包含了选择和循环。
操作数基本寻址方式
1、隐含寻址
- 指令中隐含着操作数的地址,比如隐藏累加器的地址,当该指令被执行时会执行累加器,但累加器的地址是没有表现在该指令上的。
- 如某些运算,隐含了累加器AC作为源和目的寄存器
- 如8086汇编中的STC指令,设置标志寄存器的C为1
2、立即寻址
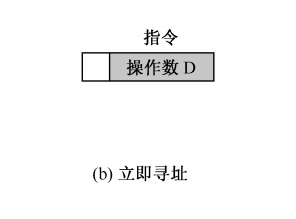
指令的地址指出的不是操作数地址,而是操作数本身。比如
int x=6,y=7;
int z=x+y;在上面这个例子中,执行加法的时候x,y不是6和7的地址,而是6和7本身;
3、直接寻址

在指令格式中的地址上指出操作数在内存中的地址。其实这很像数组,例如
char x='1';//地址为5673
char cha[]={'x'};//地址为2341
我们在使用cha[0]的时候,地址2341指向的就是1的地址5673,一个地址指向另一个地址。
4、间接寻址
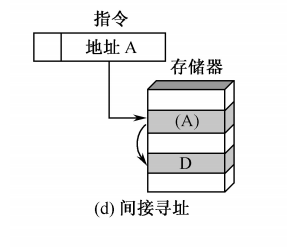
类似二维数组
5、寄存器寻址
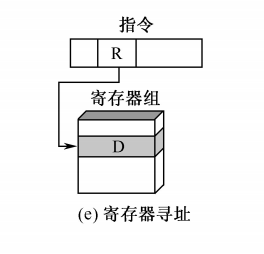
当操作数不在内存而是在CPU的寄存器中时使用这个寻址方式
6、寄存器简介寻址
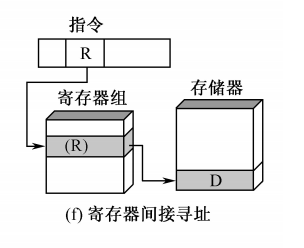
操作数不在寄存器中,而是在寄存器地址所知的位置,比如内存(类似二维数组)
7、偏移寻址

类似于数组中,数组下标的变化会对应不同的地址上的值,下标的变化可以理解为加了某一个偏移量而产生改变。
下面介绍三种不同的偏移寻址,他们的不同我觉得就是使用的寄存器不一样,本质上都是地址加了偏移量后找到第二个地址,再通过第二个地址上的值进行操作。
7.1 相对寻址
使用的是程序计数器(CP),CP作为原始地址,EA=A+(CP)
7.2 基址寻址
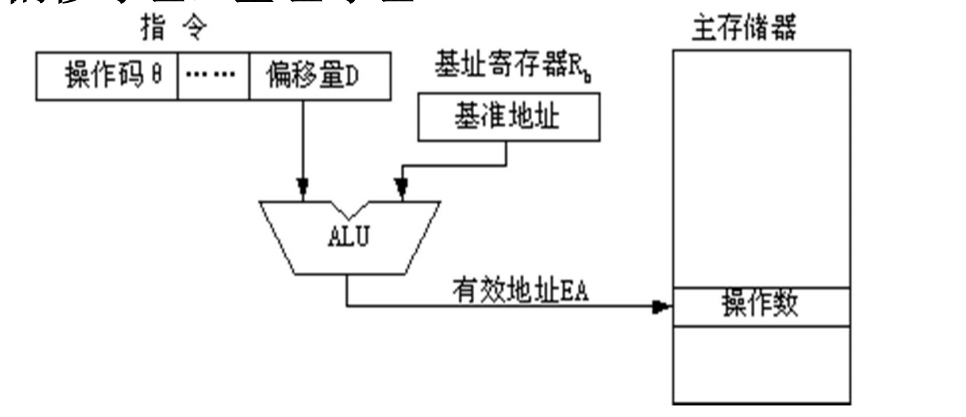
使用存储器地址,作为原始地址,
7.3 变址寻址
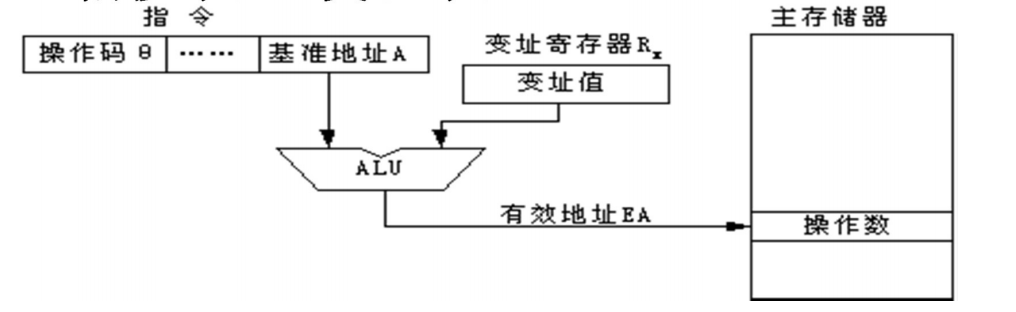
就是将指令的地址码部分给出的基准地址A与CPU内某特定的变址寄存器Rx中的内容相加,以形成操作数的有效地址。
8、分寄存器堆栈、存储器堆栈以先进后出原理存储数据
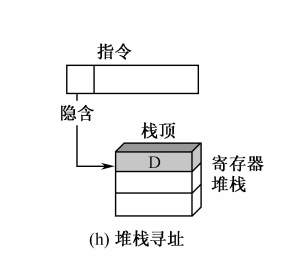
9、段寻址方式
存储空间划分为多段
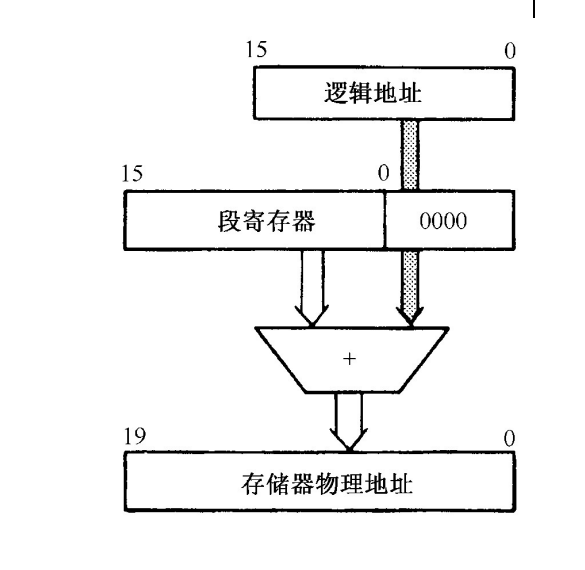
典型的指令
- 数据处理
- 数据存储
- 数据传送
- 程序控制
- 数据传送指令
- 算术运算指令
- 逻辑运算指令
- 程序控制指令
- 输入输出指令
- 字符串处理指令
- 特权指令
中央处理器
冯诺一曼机的运算器与控制器是分开的,二现今这两个是设计在同一块芯片上,成为 CPU ,而单片机就是 CPU+存储器。
CPU的功能和组成
CPU的功能
取指令,执行指令
- 指令控制。程序的顺序控制 。
- 操作控制。控制指令的取出与执行。
- 时间控制。对操作实施时间上的定时。
- 数据加工。例如算数运算和逻辑运算
CPU的组成
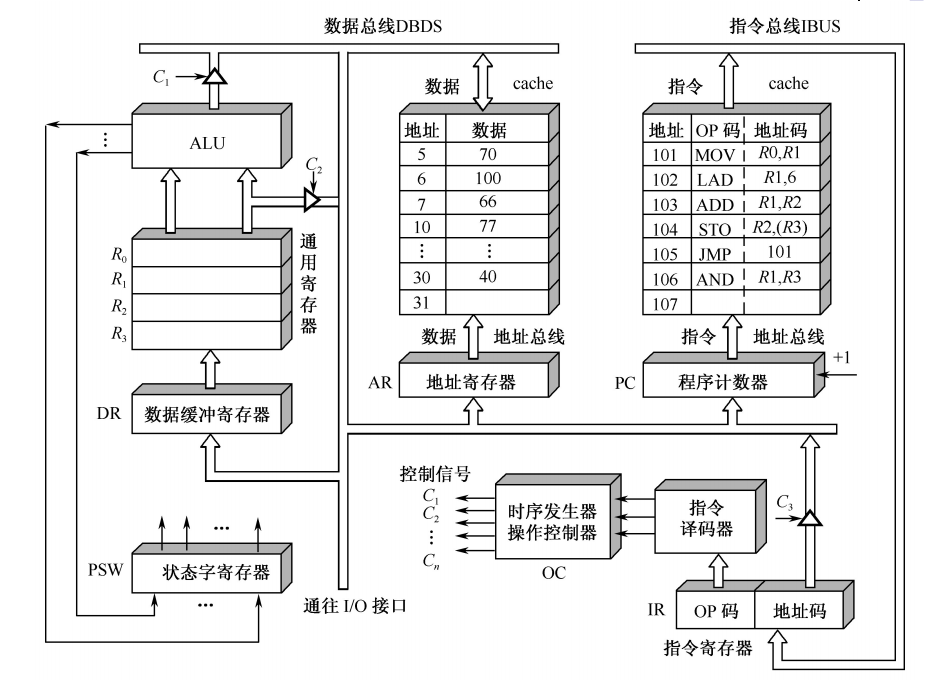 中央处理器CPU = 运算器 + cache + 控制器
中央处理器CPU = 运算器 + cache + 控制器
运算器
- ALU:算术逻辑运算单元
- 通用寄存器:R0~R3
- 数据缓冲寄存器:DR
- 程序状态字寄存器:PSWR
控制器
程序计数器、指令寄存器、时序发生器、操作控制寄存器;
- 程序计数器PC(Programming Counter)
- 用来存放正在执行的指令的地址或接着将要执行的下一条指令的地址。
- 顺序执行 时,每执行一条指令,PC的值应 加1
- 要改变程序执行顺序的情况时,一般由转移类指令将转移目标地址送往PC ,可实现程序的转移。
- 指令寄存器IR(Instruction Register)
- 指令寄存器用来存放从存储器中 取出的待执行的指令。
- 在执行该指令的过程中,指令寄存器的内容不允许发生变化,以保证实现指令的全部功能。
重要的寄存器
- 数据缓冲寄存器(DP):暂时存放ALU(算术逻辑运算单元)运算结果,或或有数据寄存器读出的数据字,或外部接口的数据字。
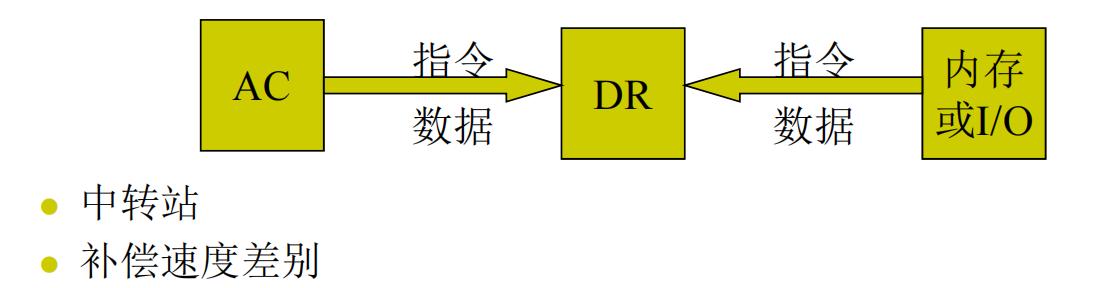
- 指令寄存器(IR):用来保存当前正在执行的第一条指令
- 程序计数器(PC):总是保持将要执行的下一条指令,绝大多数是顺序程序,所以修改过程中通常是简单的PC加1.
- 数据地址寄存器(AR)用来保存当前CPU所访问的数据存储单元的地址。
- 通用寄存器(R0~R3):存常用的指令,
- 状态字寄存器(PSW):保存有算术运算或逻辑运算或测试结果产生的更重条件代码,简而言之就是存储一些运算的结果,比如进位、溢出、零标志、负标志等
指令周期
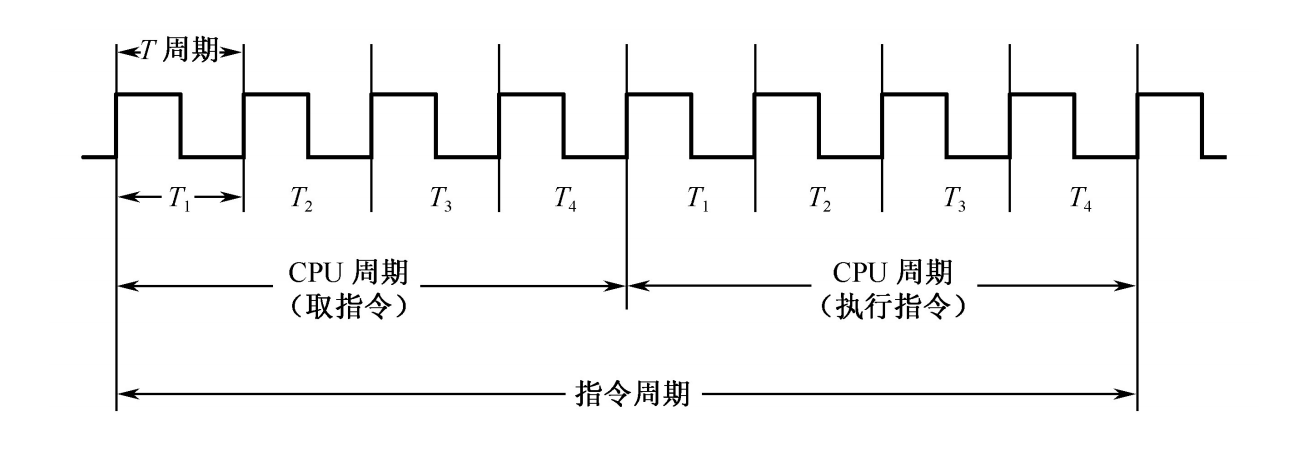 指令周期由若干个CPU周期数表示,CPU周期又称为机器周期,在一些系统中称机器周期为时钟周期。
指令周期由若干个CPU周期数表示,CPU周期又称为机器周期,在一些系统中称机器周期为时钟周期。
指令周期又分为取指令周期与执行指令周期
-
也被称为电脑,或者电子计算机。 ↩︎
51单片机
- pretues+kiel5仿真软件配合使用时需要注意的地方
不知道keil5从哪个版本开始就不支持了晶振的设置操作,我在网上搜也得到不同的答案,所以从哪个版本开始限制这就不提了, 好在这样的改变并不会形象我们使用keil5。最近在刚进阶学习stm32,用到了pretues_8.11 仿真软 件和keil5代码编辑器,自己把心中所得分享一下。
51单片机 的子部分
pretues+kiel5仿真软件配合使用时需要注意的地方
不知道keil5从哪个版本开始就不支持了晶振的设置操作,我在网上搜也得到不同的答案,所以从哪个版本开始限制这就不提了, 好在这样的改变并不会形象我们使用keil5。最近在刚进阶学习stm32,用到了pretues_8.11 仿真软 件和keil5代码编辑器,自己把心中所得分享一下。
别人编译编译成功的工程,我另外用keil5打开编译为什么会失败?
假设你拿到的别人的工程所选芯片为stm32f103VC,那么你在另外的电脑打开keil5,在设置里选芯片也是stm32f103VC,如果选的芯片与工程最初选的型号不同,那编译可能会失败,接着在打勾生成.hex文件。
pretues里没有找到keil5里选择的芯片,能用别的芯片代替吗?
答案是可以的,但尽量使用版本更高的芯片,使之能向下兼容,在keil5如果选了stm32f103VC,而pretues仿真的芯片是stm32f103C6,那么你并不用担心芯片不对应而导致你仿真失败。
在pretues导入.hex文件后直接开始仿真,为什么报了许多错误?
可能原因:在选择好.hex文件后,还必须设置晶振频率,即12MHz,如果没置会导致仿真失败,另外你不用担心选择的.hex文件路径有中文,我测过即使导入文件路径有中文也可以正常运行。
19.设计模式(C++)
组件协作
模板方法-template method
在C语言代码编写中主函数调用常调用库函数,进行功能实现。那么现在面向对象编程中,可以选择在库中调用未来写在主函数中的函数,这个设计方式就叫template method(个人的理解,不是定义)。举个例子,假设有一个lib.h的库,里面写了画圆的步骤,主体框架已经在rung()中写好,但是还有一个函数没用写,该函数是用来指定圆的半径等参数的,这个函数用virtual修饰,在未来主函数中可以继承该类并重写这个函数,最后在调用lib.h库里的run()即可。
在这里画圆的框架以及步骤已经规定好,也就是稳定的,而圆的半径是变化,使用以上方法就把稳定与变化分开,这也是设计模式的核心要点之一。例子粗糙但已经能说明该设计模式了
前一过程称为早绑定,后一过程称为晚绑定。
策略方法-strategy
如下图是该方法的结构图。
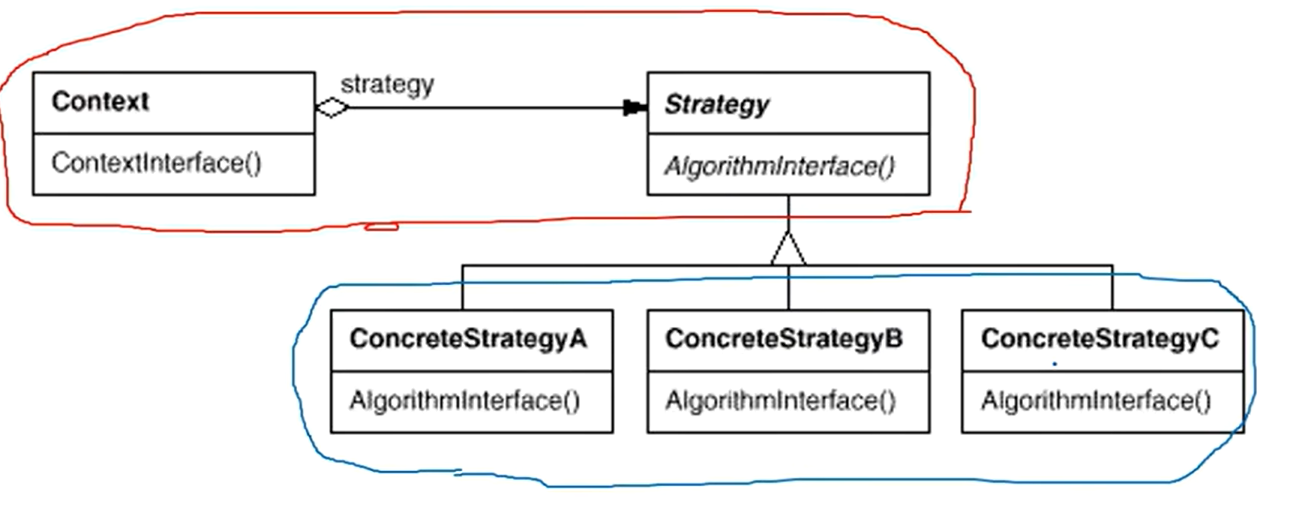
该方法是为了应对未来的需求,这在业务就很常见,在未来会增加业务的功能,主要体现在代码运行时,假设现在有三种算分分别对应三种不同的情况,在运算时需要对不同的算法做不同的处理,以往我们会使用if-else或Switch-case,但是当情况不是三种或未来增加时,后者的代码会变得冗长,也不好维护,现在我们可以把三种情况对应的算法继承一个基类中的virtual修饰的方法,并重写这个方法。在运行处通过上下文调用对应的算法。